Семейство видеокарт Nvidia GeForce 20: справочная информация
Предыдущие поколения видеокарт Nvidia GeForce
Спецификации чипов семейства Turing
| Кодовое имя | TU102 | TU104 | TU106 | TU116 | TU117 |
|---|---|---|---|---|---|
| Базовая статья | здесь | здесь | здесь | здесь | здесь |
| Технология, нм | 12 | ||||
| Транзисторов, млрд | 18,6 | 13,6 | 10,8 | 6,6 | 4,7 |
| Площадь кристалла, мм² | 754 | 545 | 445 | 284 | 200 |
| Универсальных процессоров | 4608 | 3072 | 2304 | 1536 | 1024 |
| Текстурных блоков | 288 | 192 | 144 | 96 | 64 |
| Блоков блендинга | 96 | 64 | 64 | 48 | 32 |
| Шина памяти | 384 | 256 | 256 | 192 | 128 |
| Типы памяти | GDDR6 | GDDR5 | |||
| Системная шина | PCI Express 3.0 | ||||
| Интерфейсы | DVI Dual Link HDMI 2.0b DisplayPort 1.4 |
Спецификации референсных карт на чипах семейства Turing
| Карта | Чип | Блоков ALU/TMU/ROP | Частота ядра, МГц | Эффективная частота памяти, МГц | Объем памяти, ГБ | ПСП, ГБ/c (бит) |
Текстурирование, Гтекс | Филлрейт, Гпикс | TDP, Вт |
|---|---|---|---|---|---|---|---|---|---|
| Titan RTX | TU102 | 4608/288/96 | 1365/1770 | 14000 | 24 GDDR6 | 672 (384) | 510 | 170 | 280 |
| RTX 2080 Ti | TU102 | 4352/272/88 | 1350/1545 | 14000 | 11 GDDR6 | 616 (352) | 420 | 136 | 250 |
| RTX 2080 Super | TU104 | 3072/192/64 | 1650/1815 | 15500 | 8 GDDR6 | 496 (256) | 349 | 116 | 250 |
| RTX 2080 | TU104 | 2944/184/64 | 1515/1710 | 14000 | 8 GDDR6 | 448 (256) | 315 | 109 | 215 |
| RTX 2070 Super | TU104 | 2560/160/64 | 1605/1770 | 14000 | 8 GDDR6 | 448 (256) | 283 | 113 | 215 |
| RTX 2070 | TU106 | 2304/144/64 | 1410/1620 | 14000 | 8 GDDR6 | 448 (256) | 233 | 104 | 175 |
| RTX 2060 Super | TU106 | 2176/136/64 | 1470/1650 | 14000 | 8 GDDR6 | 448 (256) | 224 | 106 | 175 |
| RTX 2060 | TU106 | 1920/120/48 | 1365/1680 | 14000 | 6 GDDR6 | 336 (192) | 202 | 81 | 160 |
| GTX 1660 Ti | TU116 | 1536/96/48 | 1500/1770 | 12000 | 6 GDDR6 | 288 (192) | 170 | 85 | 120 |
| GTX 1660 | TU116 | 1408/88/48 | 1530/1785 | 8000 | 6 GDDR5 | 192 (192) | 157 | 86 | 120 |
| GTX 1650 | TU117 | 896/56/32 | 1485/1665 | 8000 | 4 GDDR5 | 128 (128) | 93 | 53 | 75 |
Графический ускоритель GeForce RTX 2080 Ti
После длительного застоя на рынке графических процессоров, связанного с несколькими факторами, в 2018 году вышло новое поколение GPU компании Nvidia, сразу обеспечившее переворот в 3D-графике реального времени! Аппаратно ускоренной трассировки лучей многие энтузиасты ждали уже давно, так как этот метод рендеринга олицетворяет физически корректный подход к делу, просчитывая путь лучей света, в отличие от растеризации с использованием буфера глубины, к которой мы привыкли за много лет и которая лишь имитирует поведение лучей света. Об особенностях трассировки мы написали большую подробную статью.
Хотя трассировка лучей обеспечивает более высокое качество картинки по сравнению с растеризацией, она весьма требовательна к ресурсам и ее применение ограничено возможностями аппаратного обеспечения. Анонс технологии Nvidia RTX и аппаратно поддерживающих ее GPU дал разработчикам возможность начать внедрение алгоритмов, использующих трассировку лучей, что является самым значительным изменением в графике реального времени за последние годы. Со временем она полностью изменит подход к рендерингу 3D-сцен, но это произойдет постепенно. Поначалу использование трассировки будет гибридным, при сочетании трассировки лучей и растеризации, но затем дело дойдет и до полной трассировки сцены, которая станет доступной через несколько лет.
Что предлагает Nvidia уже сейчас? Компания анонсировала свои игровые решения линейки GeForce RTX в августе 2018 года, на игровой выставке Gamescom. GPU основаны на новой архитектуре Turing, представленной еще чуть ранее — на SIGGraph 2018, когда были рассказаны лишь некоторые подробности о новинках. В линейке GeForce RTX объявлено три модели: RTX 2070, RTX 2080 и RTX 2080 Ti, они основаны на трех графических процессорах: TU106, TU104 и TU102 соответственно. Сразу бросается в глаза, что с появлением аппаратной поддержки ускорения трассировки лучей Nvidia поменяла систему наименований и видеокарт (RTX — от ray tracing, т. е. трассировка лучей), и видеочипов (TU — Turing).

Почему Nvidia решила, что аппаратную трассировку необходимо представить в 2018-м? Ведь прорывов в технологии производства кремния не было, полноценное освоение нового техпроцесса 7 нм еще не закончено, особенно если говорить о массовом производстве таких больших и сложных GPU. И возможностей для заметного повышения количества транзисторов в чипе при сохранении приемлемой площади GPU практически нет. Выбранный для производства графических процессоров линейки GeForce RTX техпроцесс 12 нм FinFET хоть и лучше 16-нанометрового, известного нам по поколению Pascal, но эти техпроцессы весьма близки по своим основным характеристикам, 12-нанометровый использует схожие параметры, обеспечивая чуть большую плотность размещения транзисторов и сниженные утечки тока.
Компания решила воспользоваться своим лидирующим положением на рынке высокопроизводительных графических процессоров, а также фактическим отсутствием конкуренции в момент анонса RTX (лучшие из решений единственного конкурента с трудом дотягивали даже до GeForce GTX 1080) и выпустить новинки с поддержкой аппаратной трассировки лучей именно в этом поколении — еще до возможности массового производства больших чипов по техпроцессу 7 нм.
Кроме модулей трассировки лучей, в составе новых GPU есть аппаратные блоки для ускорения задач глубокого обучения — тензорные ядра, которые достались Turing по наследству от Volta. И надо сказать, что Nvidia идет на приличный риск, выпуская игровые решения с поддержкой двух совершенно новых для пользовательского рынка типов специализированных вычислительных ядер. Главный вопрос заключается в том, смогут ли они получить достаточную поддержку от индустрии — с использованием новых возможностей и новых типов специализированных ядер.
| Графический ускоритель GeForce RTX 2080 Ti | |
|---|---|
| Кодовое имя чипа | TU102 |
| Технология производства | 12 нм FinFET |
| Количество транзисторов | 18,6 млрд (у GP102 — 12 млрд) |
| Площадь ядра | 754 мм² (у GP102 — 471 мм²) |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12, с поддержкой уровня возможностей Feature Level 12_1 |
| Шина памяти | 352-битная: 11 (из 12 физически имеющихся в GPU) независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6 |
| Частота графического процессора | 1350 (1545/1635) МГц |
| Вычислительные блоки | 34 потоковых мультипроцессора, включающих 4352 CUDA-ядра для целочисленных расчетов INT32 и вычислений с плавающей запятой FP16/FP32 |
| Тензорные блоки | 544 тензорных ядра для матричных вычислений INT4/INT8/FP16/FP32 |
| Блоки трассировки лучей | 68 RT-ядер для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 272 блока текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 11 (из 12 физически имеющихся в GPU) широких блоков ROP (88 пикселей) с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка подключения по интерфейсам HDMI 2.0b и DisplayPort 1.4a |
| Спецификации референсной видеокарты GeForce RTX 2080 Ti | |
|---|---|
| Частота ядра | 1350 (1545/1635) МГц |
| Количество универсальных процессоров | 4352 |
| Количество текстурных блоков | 272 |
| Количество блоков блендинга | 88 |
| Эффективная частота памяти | 14 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 352-бит |
| Объем памяти | 11 ГБ |
| Пропускная способность памяти | 616 ГБ/с |
| Вычислительная производительность (FP16/FP32) | до 28,5/14,2 терафлопс |
| Производительность трассировки лучей | 10 гигалучей/с |
| Теоретическая максимальная скорость закраски | 136–144 гигапикселей/с |
| Теоретическая скорость выборки текстур | 420–445 гигатекселей/с |
| Шина | PCI Express 3.0 |
| Разъемы | один HDMI и три DisplayPort |
| Энергопотребление | до 250/260 Вт |
| Дополнительное питание | два 8-контактных разъема |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | $999/$1199 или 95990 руб. (Founders Edition) |
Как это стало обычным делом для нескольких семейств видеокарт Nvidia, линейка GeForce RTX предлагает специальные модели самой компании — так называемые Founders Edition. В этот раз при более высокой стоимости они обладают и более привлекательными характеристиками. Так, фабричный разгон у таких видеокарт есть изначально, а кроме этого, GeForce RTX 2080 Ti Founders Edition выглядят весьма солидно благодаря удачному дизайну и отличным материалам. Каждая видеокарта протестирована на стабильную работу и обеспечивается трехлетней гарантией.

Видеокарты GeForce RTX Founders Edition имеют кулер с испарительной камерой на всю длину печатной платы и два вентилятора для более эффективного охлаждения. Длинная испарительная камера и большой двухслотовый алюминиевый радиатор обеспечивают большую площадь рассеивания тепла. Вентиляторы отводят горячий воздух в разные стороны, и при этом работают они довольно тихо.
Система питания в GeForce RTX 2080 Ti Founders Edition также серьезно усилена: применяется 13-фазная схема iMon DrMOS (в GTX 1080 Ti Founders Edition была 7-фазная dual-FET), поддерживающая новую динамическую систему управления питанием с более тонким контролем, улучшающая разгонные возможности видеокарты, о которых мы еще поговорим далее. Для питания скоростной GDDR6-памяти установлена отдельная трехфазная схема.
Архитектурные особенности
Применяемая в старшей модели видеокарты GeForce RTX 2080 Ti модификация графического процессора TU102 по количеству блоков ровно вдвое больше, чем TU106, который появился в виде модели GeForce RTX 2070 чуть позднее. Самый же сложный TU102, применяемый в 2080 Ti, имеет площадь 754 мм² и 18,6 млрд транзисторов против 610 мм² и 15,3 млрд транзисторов у топового чипа семейства Pascal — GP100.
Примерно то же самое и с остальными новыми GPU, все они по сложности чипов как бы сдвинуты на шаг: TU102 соответствует TU100, TU104 по сложности похож на TU102, а TU106 — на TU104. Так как GPU усложнились, но техпроцессы применяются очень схожие, то и по площади новые чипы заметно увеличились. Посмотрим, за счет чего графические процессоры архитектуры Turing стали сложнее:
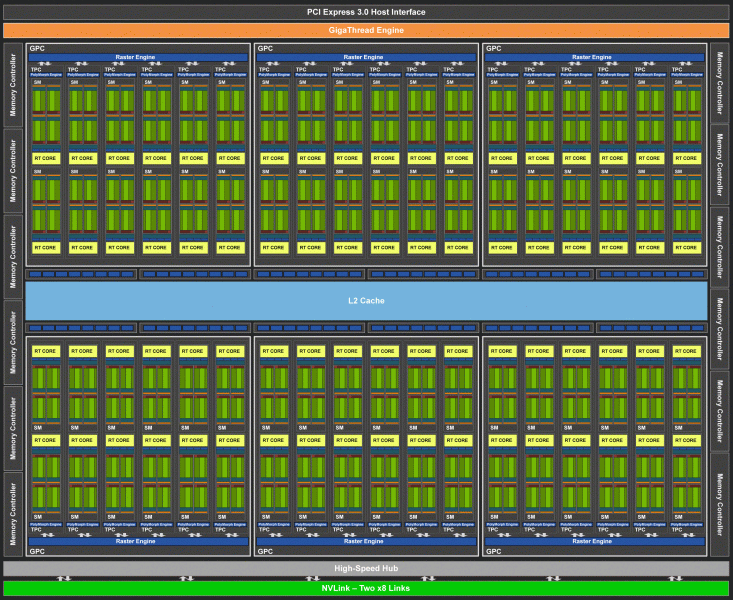
Полный чип TU102 включает шесть кластеров Graphics Processing Cluster (GPC), 36 кластеров Texture Processing Cluster (TPC) и 72 потоковых мультипроцессора Streaming Multiprocessor (SM). Каждый из кластеров GPC имеет собственный движок растеризации и шесть кластеров TPC, каждый из которых, в свою очередь, включает два мультипроцессора SM. Все SM содержат по 64 CUDA-ядра, по 8 тензорных ядер, по 4 текстурных блока, регистровый файл 256 КБ и 96 КБ конфигурируемого L1-кэша и разделяемой памяти. Для нужд аппаратной трассировки лучей каждый мультипроцессор SM имеет также и по одному RT-ядру.
Всего в полной версии TU102 получается 4608 CUDA-ядер, 72 RT-ядра, 576 тензорных ядер и 288 блоков TMU. Графический процессор общается с памятью при помощи 12 отдельных 32-битных контроллеров, что дает 384-битную шину в целом. К каждому контроллеру памяти привязаны по восемь блоков ROP и по 512 КБ кэш-памяти второго уровня. То есть всего в чипе 96 блоков ROP и 6 МБ L2-кэша.
По структуре мультипроцессоров SM новая архитектура Turing очень схожа с Volta, и количество ядер CUDA, блоков TMU и ROP по сравнению с Pascal выросло не слишком сильно — и это при таком усложнении и физическом увеличении чипа! Но это не удивительно, ведь основную сложность привнесли новые типы вычислительных блоков: тензорные ядра и ядра ускорения трассировки лучей.
Еще были усложнены сами CUDA-ядра, в которых появилась возможность одновременного исполнения целочисленных вычислений и операций с плавающей запятой, а также серьезно увеличен объем кэш-памяти. Об этих изменениях мы поговорим далее, а пока что отметим, что при проектировании семейства Turing разработчики намеренно перенесли фокус с производительности универсальных вычислительных блоков в пользу новых специализированных блоков.
Но не следует думать, что возможности CUDA-ядер остались неизменными, их тоже значительно улучшили. По сути, потоковый мультипроцессор Turing основан на варианте Volta, из которого исключена большая часть FP64-блоков (для операций с двойной точностью), но оставлена удвоенная производительность на такт для FP16-операций (также аналогично Volta). Блоков FP64 в TU102 оставлено 144 штуки (по два на SM), они нужны только для обеспечения совместимости. А вот вторая возможность позволит увеличить скорость и в приложениях, поддерживающих вычисления со сниженной точностью, вроде некоторых игр. Разработчики уверяют, что в значительной части игровых пиксельных шейдеров можно смело снизить точность с FP32 до FP16 при сохранении достаточного качества, что также принесет некоторый прирост производительности. Со всеми подробностями работы новых SM можно ознакомиться в обзоре архитектуры Volta.
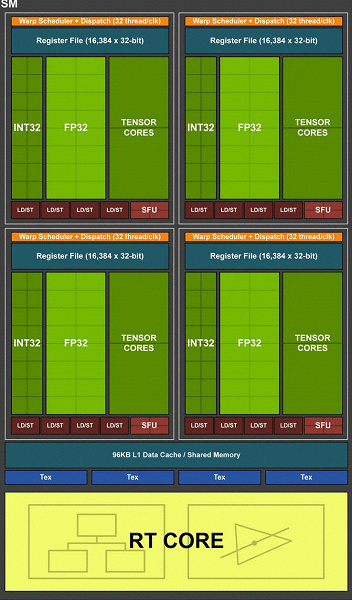
Одним из важнейших изменений потоковых мультипроцессоров является то, что в архитектуре Turing стало возможным одновременное выполнение целочисленных (INT32) команд вместе с операциями с плавающей запятой (FP32). Некоторые пишут, что в CUDA-ядрах «появились» блоки INT32, но это не совсем верно — они «появились» в составе ядер сразу, просто до архитектуры Volta одновременное исполнение целочисленных и FP-инструкций было невозможно, и эти операции запускались на выполнение по очереди. CUDA-ядра архитектуры Turing же схожи с ядрами Volta, которые позволяют исполнять INT32- и FP32-операции параллельно.
И так как игровые шейдеры, помимо операций с плавающей запятой, используют много дополнительных целочисленных операций (для адресации и выборки, специальных функций и т. п.), то это нововведение способно серьезно повысить производительность в играх. По оценкам компании Nvidia, в среднем на каждые 100 операций с плавающей запятой приходится около 36 целочисленных операций. Так что лишь это улучшение способно принести прирост скорости вычислений порядка 36%. Важно отметить, что это касается только эффективной производительности в типичных условиях, а на пиковых возможностях GPU не сказывается. То есть пусть теоретические цифры для Turing и не столь красивы, в реальности новые графические процессоры должны оказаться более эффективными.
Но почему, раз в среднем целочисленных операций лишь 36 на 100 FP-вычислений, количество блоков INT и FP одинаково? Скорее всего, это сделано для упрощения работы управляющей логики, а кроме этого, INT-блоки наверняка значительно проще FP, так что «лишнее» их количество вряд ли сильно повлияло на общую сложность GPU. Ну и задачи графических процессоров Nvidia давно не ограничиваются игровыми шейдерами, а в других применениях доля целочисленных операций вполне может быть и выше. Кстати, аналогично Volta повысился и темп выполнения инструкций для математических операций умножения-сложения с однократным округлением (fused multiply–add — FMA), требующих лишь четырех тактов по сравнению с шестью тактами на Pascal.
В новых мультипроцессорах SM была серьезно изменена и архитектура кэширования, для чего кэш первого уровня и разделяемая память были объединены (у Pascal они были раздельные). Shared-память ранее имела лучшие характеристики по пропускной способности и задержкам, а теперь пропускная способность L1-кэша выросла вдвое, снизились задержки доступа к нему вместе с одновременным увеличением емкости кэша. В новом GPU можно изменять соотношение объема L1-кэша и разделяемой памяти, выбирая из нескольких возможных конфигураций.
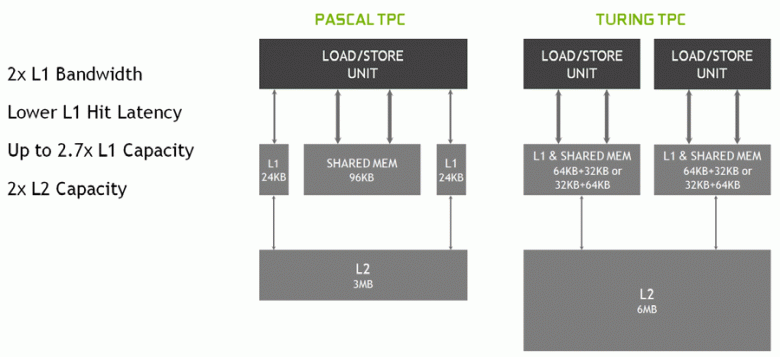
Кроме этого, в каждом разделе мультипроцессора SM появился L0-кэш для инструкций вместо общего буфера, а каждый кластер TPC в чипах архитектуры Turing теперь имеет вдвое больше кэш-памяти второго уровня. То есть общий объем L2-кэша вырос до 6 МБ для TU102 (у TU104 и TU106 его поменьше — 4 МБ).
Эти архитектурные изменения привели к 50%-ному улучшению производительности шейдерных процессоров при равной тактовой частоте в таких играх, как Sniper Elite 4, Deus Ex, Rise of the Tomb Raider и других. Но это не значит, что общий рост частоты кадров будет равен 50%, так как общая производительность рендеринга в играх далеко не всегда ограничена именно скоростью вычисления шейдеров.
Также были улучшены технологии сжатия информации без потерь, экономящие видеопамять и ее пропускную способность. Архитектура Turing поддерживает новые техники сжатия — по данным Nvidia, до 50% более эффективные по сравнению с алгоритмами в семействе чипов Pascal. Вместе с применением нового типа памяти GDDR6 это дает приличный прирост эффективной ПСП, так что новые решения не должны быть ограничены возможностями памяти. А при увеличении разрешения рендеринга и повышении сложности шейдеров ПСП играет важнейшую роль в обеспечении общей высокой производительности.
К слову, о памяти. Инженеры Nvidia работали совместно с производителями для обеспечения поддержки нового типа памяти — GDDR6, и все новое семейство GeForce RTX поддерживает микросхемы этого типа, имеющие пропускную способность в 14 Гбит/с и при этом на 20% более энергоэффективные по сравнению с применяемой в топовых Pascal GDDR5X-памятью. Топовый чип TU102 имеет 384-битную шину памяти (12 штук 32-битных контроллеров), но так как один из них отключен в GeForce RTX 2080 Ti, то шина памяти у него 352-битная, и на топовую карту семейства установлено 11, а не 12 ГБ.
Сама по себе GDDR6 хоть и является совершенно новым типом памяти, но слабо отличается от уже использовавшейся ранее GDDR5X. Основное ее отличие — в еще более высокой тактовой частоте при том же напряжении в 1,35 В. А от GDDR5 новый тип отличается тем, что имеет два независимых 16-битных канала с собственными шинами команд и данных — в отличие от единого 32-битного интерфейса GDDR5 и не полностью независимых каналов в GDDR5X. Это позволяет оптимизировать передачу данных, а более узкая 16-битная шина работает эффективнее.
Характеристики GDDR6 обеспечивают высокую пропускную способность памяти, которая стала значительно выше, чем была у предыдущего поколения GPU, поддерживающего типы памяти GDDR5 и GDDR5X. Рассматриваемая сегодня GeForce RTX 2080 Ti имеет ПСП на уровне 616 ГБ/с, что выше и чем у предшественников, и чем у конкурирующей видеокарты, использующей дорогую память стандарта HBM2. В будущем характеристики памяти GDDR6 будут улучшаться, сейчас ее выпускают компании Micron (скорость от 10 до 14 Гбит/с) и Samsung (14 и 16 Гбит/с).
Другие нововведения
Добавим немного информации о других нововведениях Turing, которые будут полезны и для старых, и для новых игр. К примеру, по некоторым фичам (feature level) из Direct3D 12 чипы Pascal отставали от решений AMD и даже Intel! В частности, это касается таких возможностей, как Constant Buffer Views, Unordered Access Views и Resource Heap (возможности, облегчающие работу программистов, упрощая доступ к различным ресурсам). Так вот, по этим возможностям Direct3D feature level новые GPU компании Nvidia теперь практически не отстают от конкурентов, поддерживая уровень Tier 3 для Constant Buffer Views и Unordered Access Views и Tier 2 для resource heap.
Единственная возможность D3D12, которая есть у конкурентов, но не поддерживается в Turing — PSSpecifiedStencilRefSupported: возможность вывести из пиксельного шейдера референсное значение стенсиля, иначе его можно установить только глобально для всего вызова функции отрисовки. В некоторых старых играх стенсиль использовался для отсечения источников освещения в различных регионах экрана, и эта возможность была полезна для занесения в стенсиль маски с несколькими разными значениями, чтобы каждому источнику света отрисовываться в своем проходе со стенсил-тестом. Без PSSpecifiedStencilRefSupported эту маску приходится рисовать в несколько проходов, а так можно сделать один, вычисляя значение стенсиля непосредственно в пиксельном шейдере. Вроде бы штука полезная, но в реальности не сильно важна — проходы эти несложные, и заполнение стенсиля в несколько проходов мало на что влияет при современных GPU.
Зато с остальным все в порядке. Появилась поддержка удвоенного темпа исполнения инструкций с плавающей запятой, и в том числе в Shader Model 6.2 — новой шейдерной модели DirectX 12, которая включает нативную поддержку FP16, когда вычисления производятся именно в 16-битной точности и драйвер не имеет права использовать FP32. Предыдущие GPU игнорировали установку min precision FP16, используя FP32, когда им вздумается, а в SM 6.2 шейдер может потребовать использование именно 16-битного формата.
Кроме этого, было серьезно улучшено еще одно больное место чипов Nvidia — асинхронное исполнение шейдеров, высокой эффективностью которого отличаются решения AMD. Async compute уже неплохо работал в последних чипах семейства Pascal, но в Turing эта возможность была еще улучшена. Асинхронные вычисления в новых GPU полностью переработаны, и на одном и том же шейдерном мультипроцессоре SM могут запускать и графические, и вычислительные шейдеры, как и чипы AMD.
Но и это еще не все, чем может похвастать Turing. Многие изменения в этой архитектуре нацелены на будущее. Так, Nvidia предлагает метод, позволяющий значительно снизить зависимость от мощности CPU и одновременно с этим во много раз увеличить количество объектов в сцене. Бич API/CPU overhead давно преследует ПК-игры, и хотя он частично решался в DirectX 11 (в меньшей степени) и DirectX 12 (в несколько большей, но все равно не полностью), радикально ничего не изменилось — каждый объект сцены требует нескольких вызовов функций отрисовки (draw calls), каждый из которых требует обработки на CPU, что не дает GPU показать все свои возможности.
Слишком многое сейчас зависит от производительности центрального процессора, и даже современные многопоточные модели не всегда справляются. Кроме этого, если минимизировать «вмешательство» CPU в процесс рендеринга, то можно открыть множество новых возможностей. Конкурент Nvidia при анонсе своего семейства Vega предложил возможное решение проблем — primivtive shaders, но дело не пошло дальше заявлений. Turing предлагает аналогичное решение под названием mesh shaders — это целая новая шейдерная модель, которая ответственна сразу за всю работу над геометрией, вершинами, тесселяцией и т. д.

Mesh shading заменяет вершинные и геометрические шейдеры и тесселяцию, а весь привычный вершинный конвейер заменяется аналогом вычислительных шейдеров для геометрии, которыми можно делать все, что нужно разработчику: трансформировать вершины, создавать их или убирать, используя вершинные буферы в своих целях как угодно, создавая геометрию прямо на GPU и отправляя ее на растеризацию. Естественно, такое решение может сильно снизить зависимость от мощности CPU при рендеринге сложных сцен и позволит создавать богатые виртуальные миры с огромным количеством уникальных объектов. Такой метод также позволит использовать более эффективное отбрасывание невидимой геометрии, продвинутые техники уровня детализации (LOD — level of detail) и даже процедурную генерацию геометрии.

Но столь радикальный подход требует поддержки от API — наверное, поэтому у конкурента дело дальше заявлений не пошло. Вероятно, в Microsoft работают над добавлением этой возможности, раз она востребована уже двумя основными производителями GPU, и в какой-то из будущих версий DirectX она появится. Ну, а пока что ее можно использовать в OpenGL и Vulkan через расширения, а в DirectX 12 — при помощи специализированного NVAPI, который как раз и создан для внедрения возможностей новых GPU, еще не поддерживаемых в общепринятых API. Но так как это не универсальный для всех производителей GPU метод, то широкой поддержки mesh shaders в играх до обновления популярных графических API, скорее всего, не будет.
Еще одна интереснейшая возможность Turing называется Variable Rate Shading (VRS) — это шейдинг с переменным количеством сэмплов. Эта новая возможность дает разработчику контроль над тем, сколько выборок использовать в случае каждого из тайлов буфера размером 4×4 пикселя. То есть для каждого тайла изображения из 16 пикселей можно выбрать свое качество на этапе закраски пикселя — как меньшее, так и большее. Важно, что это не касается геометрии, так как буфер глубины и все остальное остается в полном разрешении.
Зачем это нужно? В кадре всегда есть участки, на которых легко можно понизить количество сэмплов закраски практически без потерь в качестве — к примеру, это части изображения, замыленные постэффектами типа Motion Blur или Depth of Field. А на каких-то участках можно, наоборот, увеличить качество закраски. И разработчик сможет задавать достаточное, по его мнению, качество шейдинга для разных участков кадра, что увеличит производительность и гибкость. Сейчас для подобных задач применяют так называемый checkerboard rendering, но он не универсален и ухудшает качество закраски для всего кадра, а с VRS можно делать это максимально тонко и точно.

Можно упрощать шейдинг тайлов в несколько раз, чуть ли не одну выборку для блока в 4×4 пикселя (такая возможность не показана на картинке, но она есть), а буфер глубины остается в полном разрешении, и даже при таком низком качестве шейдинга границы полигонов будут сохраняться в полном качестве, а не один на 16. К примеру, на картинке выше самые смазанные участки дороги рендерятся с экономией ресурсов вчетверо, остальные — вдвое, и лишь самые важные отрисовываются с максимальным качеством закраски. Так и в других случаях можно отрисовывать с меньшим качеством низкодетализированные поверхности и быстро движущиеся объекты, а в приложениях виртуальной реальности снижать качество закраски на периферии.
Кроме оптимизации производительности, эта технология дает и некоторые неочевидные сходу возможности, вроде почти бесплатного сглаживания геометрии. Для этого нужно отрисовывать кадр в вчетверо большем разрешении (как бы суперсэмплинг 2×2), но включить shading rate на 2×2 по всей сцене, что убирает стоимость вчетверо большей работы по закраске, но оставляет сглаживание геометрии в полном разрешении. Таким образом получается, что шейдеры исполняются лишь один раз на пиксель, но сглаживание получается как 4х MSAA практически бесплатно, поскольку основная работа GPU заключается именно в шейдинге. И это лишь один из вариантов использования VRS, наверняка программисты придумают и другие.
Нельзя не отметить и появление высокопроизводительного интерфейса NVLink второй версии, который уже используется в ускорителях высокопроизводительных вычислений Tesla. Топовый чип TU102 имеет два порта NVLink второго поколения, имеющие общую пропускную способность в 100 ГБ/с (к слову, в TU104 один такой порт, а TU106 лишен поддержки NVLink вовсе). Новый интерфейс заменяет разъемы SLI, а пропускной способности даже одного порта хватит для передачи кадрового буфера с разрешением 8К в режиме многочипового рендеринга AFR от одного GPU к другому, а передача буфера 4K-разрешения доступна на скоростях до 144 Гц. Два порта расширяют возможности SLI сразу до нескольких мониторов с разрешением 8K.
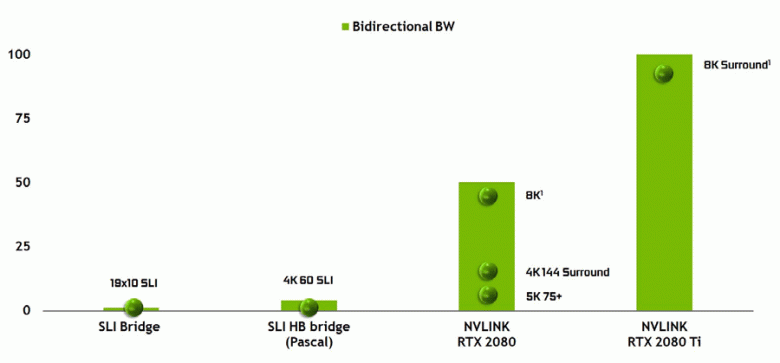
Такая высокая скорость передачи данных позволяет использовать локальную видеопамять соседнего GPU (присоединенного по NVLink, разумеется) практически как свою собственную, и это делается автоматически, без необходимости сложного программирования. Это будет весьма полезно в неграфических применениях и уже применяется в профессиональных приложениях с поддержкой аппаратной трассировки лучей (две видеокарты Quadro c 48 ГБ памяти каждая способны работать над сценой практически как единый GPU с 96 ГБ памяти, для чего ранее приходилось делать копии сцены в памяти обоих GPU), но в будущем это станет полезно и при более сложном взаимодействии многочиповых конфигураций в рамках возможностей DirectX 12. В отличие от SLI, быстрый обмен информацией по NVLink позволит организовать иные формы работы над кадром, чем AFR со всеми его недостатками.
Аппаратная поддержка трассировки лучей
Как стало известно из анонса архитектуры Turing и профессиональных решений линейки Quadro RTX на конференции SIGGraph, новые графические процессоры компании Nvidia, кроме ранее известных блоков, впервые включают также и специализированные RT-ядра, предназначенные для аппаратного ускорения трассировки лучей. Пожалуй, большая часть дополнительных транзисторов в новых GPU принадлежит именно к этим блокам аппаратной трассировки лучей, ведь количество традиционных исполнительных блоков выросло не слишком сильно, хотя и тензорные ядра немало повлияли на увеличение сложности GPU.
Nvidia сделала ставку на аппаратное ускорение трассировки при помощи специализированных блоков, и это большой шаг вперед для качественной графики в реальном времени. Мы уже публиковали большую подробную статью о трассировке лучей в реальном времени, гибридном подходе и его преимуществах, которые проявятся уже в ближайшее время. Настоятельно советуем ознакомиться, в этом материале мы расскажем о трассировке лучей лишь очень кратко.
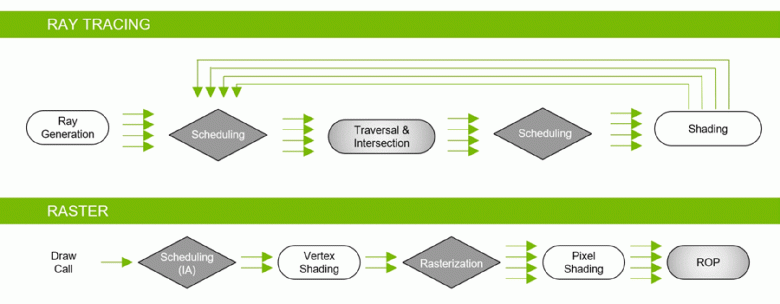
Благодаря семейству GeForce RTX уже сейчас можно использовать трассировку для некоторых эффектов: качественных мягких теней (реализовано в игре Shadow of the Tomb Raider), глобального освещения (ожидается в Metro Exodus и Enlisted), реалистичных отражений (будет в Battlefield V), а также сразу нескольких эффектов одновременно (показано на примерах Assetto Corsa Competizione, Atomic Heart и Control). При этом для GPU, не имеющих аппаратных RT-ядер в своем составе, можно использовать или привычные методы растеризации, или трассировку на вычислительных шейдерах, если это будет не слишком медленно. Вот так по-разному обрабатывают трассировку лучей архитектуры Pascal и Turing:
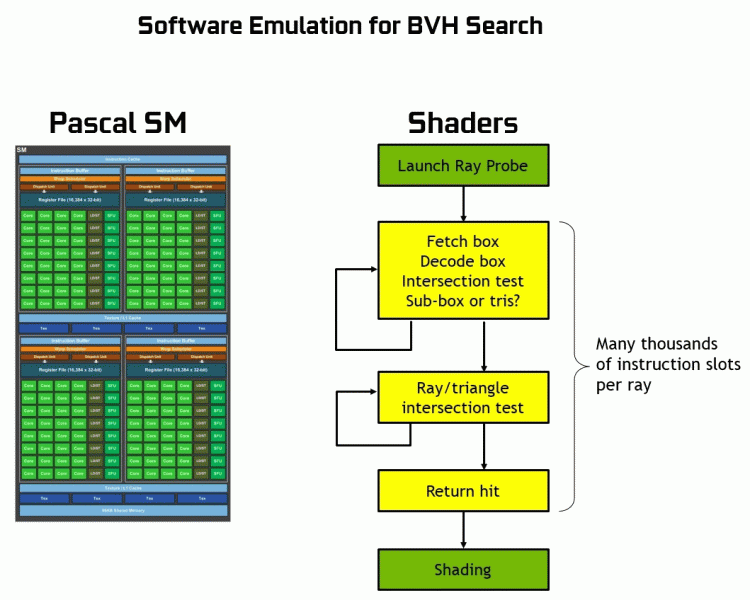
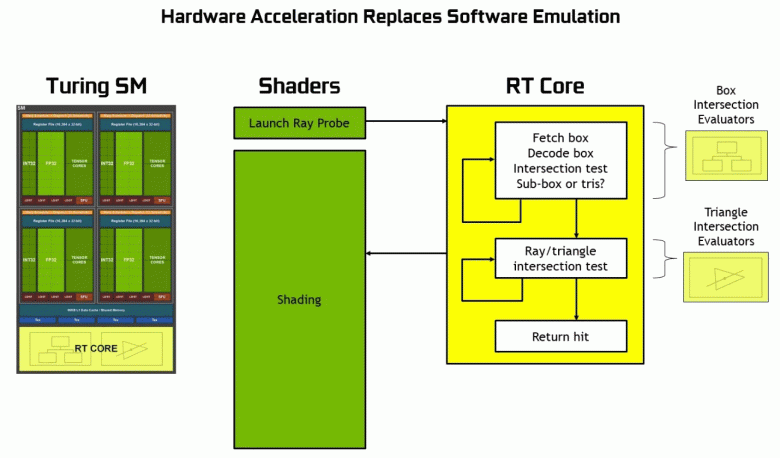
Как видите, RT-ядро полностью принимает на себя работу по определению пересечений лучей с треугольниками. Скорее всего, графические решения без RT-ядер в своем составе будут смотреться не слишком сильно в проектах с применением трассировки лучей, ведь эти ядра специализируются исключительно на расчетах пересечения луча с треугольниками и ограничивающими объемами (BVH), оптимизирующими процесс и важнейшими для ускорения процесса трассировки.
Каждый мультипроцессор в чипах Turing содержит RT-ядро, выполняющее поиск пересечений между лучами и полигонами, а чтобы не перебирать все геометрические примитивы, в Turing используется распространенный алгоритм оптимизации — иерархия ограничивающих объемов (Bounding Volume Hierarchy — BVH). Каждый полигон сцены принадлежит к одному из объемов (коробок), помогающих наиболее быстро определить точку пересечения луча с геометрическим примитивом. При работе BVH нужно рекурсивно обойти древовидную структуру таких объемов. Сложности могут возникнуть разве что для динамически изменяемой геометрии, когда придется менять и структуру BVH.
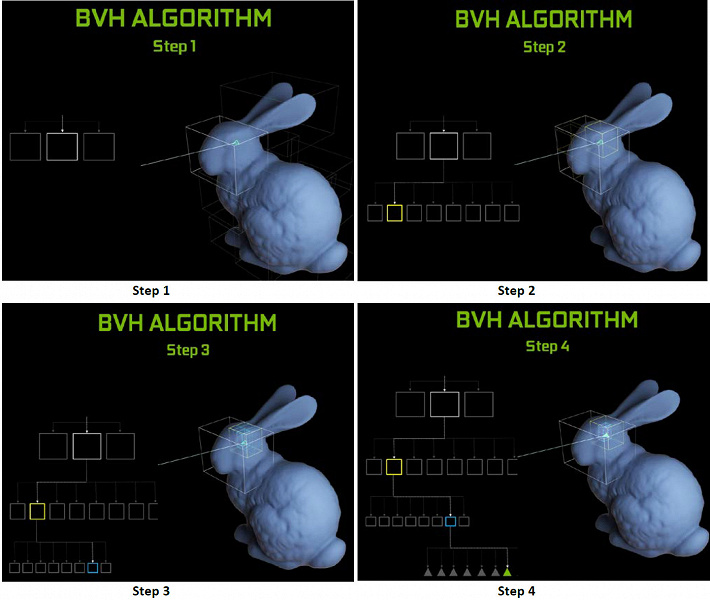
Что касается производительности новых GPU при трассировке лучей, то публике назвали цифру в 10 гигалучей в секунду для топового решения GeForce RTX 2080 Ti. Не очень понятно, много это или мало, да и оценивать производительность в количестве обсчитываемых лучей в секунду непросто, так как скорость трассировки очень сильно зависит от сложности сцены и когерентности лучей и может отличаться в десяток раз и более. В частности, слабо когерентные лучи при обсчете отражений и преломлений требуют большего времени для расчета по сравнению с когерентными основными лучами. Так что показатели эти чисто теоретические, а сравнивать разные решения нужно в реальных сценах при одинаковых условиях.
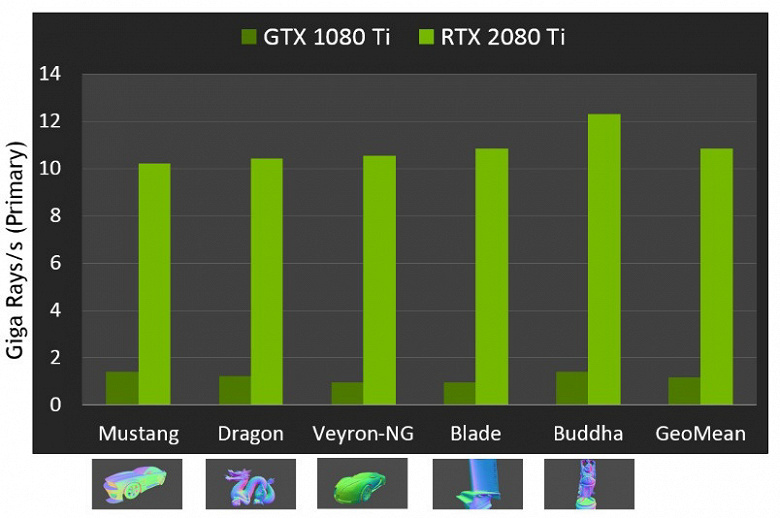
Но Nvidia сравнила новые GPU с предыдущим поколением, и в теории они оказались до 10 раз быстрее в задачах трассировки. В реальности же разница между RTX 2080 Ti и GTX 1080 Ti будет, скорее, ближе к 4–6-кратной. Но даже это — просто отличный результат, недостижимый без применения специализированных RT-ядер и ускоряющих структур типа BVH. Так как бо́льшая часть работы при трассировке выполняется на выделенных RT-ядрах, а не CUDA-ядрах, то снижение производительности при гибридном рендеринге будет заметно ниже, чем у Pascal.
Мы уже показывали вам первые демонстрационные программы с применением трассировки лучей. Некоторые из них были более зрелищными и качественными, другие впечатляли меньше. Но о потенциальных возможностях трассировки лучей не стоит судить по первым выпущенным демонстрациям, в которых намеренно выпячивают на первый план именно эти эффекты. Картинка с трассировкой лучей всегда реалистичнее в целом, но на данном этапе массы еще готовы мириться с артефактами при расчете отражений и глобального затенения в экранном пространстве, а также другими хаками растеризации.


Игровым разработчикам очень нравится трассировка, их аппетиты растут на глазах. Создатели игры Metro Exodus сначала планировали добавить в игру лишь расчет Ambient Occlusion, добавляющий теней в основном в углах между геометрией, но затем они решили внедрить уже полноценный расчет глобального освещения GI, который выглядит впечатляюще.
Кто-то скажет, что ровно так же можно предварительно рассчитать GI и/или тени и «запечь» информацию об освещении и тенях в специальные лайтмапы, но для&nbs
Полный текст статьи читайте на iXBT
