Развитие вычислений на GPU: преимущества архитектуры Fermi
Прошло всего три года со дня выхода в свет GPU c поддержкой CUDA, но за это время не только производительность видеокарт NVIDIA выросла на порядок, но и программная архитектура приобрела практически завершенный вид.
Введение ↑ ≈
После состоявшегося пару недель назад релиза новой версии CUDA SDK стала, наконец, доступной полная поддержка языка программирования высокого уровня C++ на GPU с архитектурой Fermi. Причем, сразу c поддержкой 64 бит. Это качественное, «интенсивное», улучшение, вкупе с количественным, «экстенсивным», увеличением производительности, вывело вычисления, производящиеся на GPU, на новый уровень.
Такое редко бывает в индустрии, когда происходят положительные изменения сразу в нескольких аспектах. Можно сказать, мы присутствуем при историческом моменте, который можно сравнить с выходом Intel Core 2, заменившем Pentium 4. В более ранней ретроспективе, с выходом первого Pentium. Или с выходом архитектуры Intel x86 на рынок рабочих станций.
Это даже можно отчасти сравнить с появлением самих ускорителей компьютерной графики, в первую очередь, игровой графики, которые на долгие годы изменили конфигурацию персонального компьютера. Только в этот раз облагодетельствованы были не геймеры, а прямо противоположенные персонажи. Геймеры уже пресыщены, и они все равно оказались неблагодарными. Настала пора рассмотреть реальные характерные примеры неграфического использования GPU.
Профессиональные приложения ↑ ≈
Как ни странно, первым рассмотренным неграфическим приложением будет 3D графика. А именно, программы компьютерного рендеренга. Ибо отрисовку изображения они осуществляют не средствами растеризационных блоков видеокарты, а с помощью методов в стиле трассировки лучей и фотонов, реализованных на CUDA.
Это просто рендер-плагины для популярных 3D редакторов и форматов с поддержкой GPU. Они вполне функциональны и позволяют, благодаря ускорению расчетов, оперативно получать обработанную картинку, прямо после изменения параметров освещения сцены или материалов. На маломощных системах требуется после каждого изменения запускать достаточно длительный процесс рендеренга. В первую очередь освещения, реалистичным методом. И довольствоваться при редактировании простым отображением геометрии и простейшей моделью освещения, с помощью обычных растеризационных методов.
Возможно, у GPU-рендеринга есть некоторые ограничения, которые могут быть иногда важны. Например, связанные с размером сцены и текстур, ибо объем памяти у GPU ограничен. И не всегда есть большой прирост скорости, заявленный производителем оборудования или разработчиком плагина, десятикратный и более. Тем не менее, широкий класс сцен замечательно рисуется и с большим приростом скорости. Вот рисунки, примеры рэйтрэйсинга на GPU. Картинки, с близким к фотографическому, качеством, выполнены рендером Octane Render:



Так как задачи графики прекрасно распараллеливаются на тысячи потоков (причем, алгоритм практически только читает данные из памяти: геометрию сцены и текстуры, и пишет в отдельную область памяти цвет пикселей получающийся картинки), они замечательно ложатся на архитектуру CUDA. Которая опирается на параллельное исполнение нескольких тысяч относительно независимых потоков.
Что интересно, в самой NVIDIA, в начале запуска CUDA многие не верили, что GPU может быть эффективно использован для трассировки лучей. Но теперь, в NVIDIA увлеклись новыми методами визуализации, которые имеют применение в профессиональной графике.
А вот ещё один GPU-рендер, Arion, для программ трехмерного моделирования. Тоже очень высококачественный, использующий продвинутые физические модели:




Это не фотографии и не обработанные кадры из фильма, это компьютерная графика. В разработке находятся и другие рендеры, специально для ведущих трёхмерных редакторов.
Успехи GPU в трассировке лучей интересны ещё тем, что ray-tracing — один из возможных путей развития игровой графики, притом хорошо ложащийся на неуклонный рост вычислительной мощности PC. Пусть, на данный момент, это смотрится отдаленной и нереальной перспективой по многим причинам, но GPU оказались вполне готовы и к такому повороту событий. Так что, в любом случае задачи компьютерной графики останутся прерогативой GPU. И графика послужит надежной базой для проникновения в новые области. Это важно, так как графика в любом случае обеспечит и массовость, и рынок для GPU, и прибыль для фирмы производителя.
Кстати, раз уж зашла речь об игровой графике, вот лишний пример, показывающий проблематичность внедрения трассировки лучей в играх:

Эта картинка рисуется 10 минут на системе с процессором Core i7 и видеокартой GeForce GTX 285. В тысячу раз медленнее, чем в реальном времени. Зато какое реальное освещение и блики!
Эти рендеры поддерживают и мульти-GPU конфигурации, что выгодно, так как стоимость процессоров для мультипроцессорных конфигураций и плат для них резко отличается по маркетинговым причинам от аналогичных настольных вариантов. А вот для трассировки лучей, Tesla не требуется, так как в графике можно обойтись без использования чисел double, и коррекция ошибок ECC не нужна.
Вышеуказанные программы прекрасно работают на видеокартах GT200, но выход Fermi несколько упростил реализацию трассировки. Во-первых, появились честная рекурсия и вызовы функций по их указателям. Как это может помочь? Например, если есть 100 различных шейдеров, описывающих различные материалы поверхностей, то теперь можно просто вызвать функцию с номером, соответствующим шейдеру, которая описывает данный материал. Для GT200 приходится либо писать оператор условного перехода со 100 вариантами, либо один длинный мегашейдер, описывающий все материалы. Большинство параметров его будет обращено в ноль для одного данного материала, так как они описывают какие-то другие материалы. Это не столь критично для трассировки, ибо большая часть времени тратится на расчёт пересечений лучей с объектами сцены. Но вызов отдельной функции в одну операцию удобнее и быстрее.
Второй приятный момент — иерархия кэш-памяти, появившееся в Fermi. Алгоритмы трассировки лучей часто обладают, с одной стороны, некоторой локальностью данных, ибо соседние лучи, как правило, имеют сходный путь по сцене, а с другой стороны, они не всегда используют требующуюся для оптимального быстродействия GT200 блочную загрузку данных. Когда все нити одного варпа из 32 нитей читают одновременно из одного 128-байтного блока каждая свою переменную, тогда чтение всех нитей транслируется в одно 128-байтное обращение к памяти, которое эффективно загружает шину. Если все нити варпа будут читать не одновременно или из различных блоков памяти, то транзакций будет больше, это нагрузит шину памяти и может просто убить производительность, в зависимости от того, какое в алгоритме соотношение вычислений к операциям доступа к памяти.
Но появившаяся в Fermi структура кэшей L1 и L2 смягчает это ограничение. Одна нить может загрузить 128-байтный блок, он останется в кэше и уже потом нити в произвольном порядке могут прочитать требуемые данные. Причем, нити не обязательно из того же варпа. Главное, чтобы блок был в кэше. Это просто прекрасно и, благодаря выше указанному свойству алгоритмов трассировки лучей иметь некоторую локальность данных, эти алгоритмы сильно ускоряются на Fermi. Как правило, больше номинального прироста в чистой вычислительной мощности, количества шейдеров. То есть, в 3–6 раз. Впрочем, OctaneRender показывает меньшее ускорение, так как он сильно «заточен» на архитектуру GT200 и ещё не адаптирован для Fermi.
Напомним, что L2-кэш, общий для всех мультипроцессоров, имеет размер 756 Кб и L1-кэш каждого из мультипроцессоров имеет размер 16–48 Кб, в зависимости от конфигурации 64 Кб локальной памяти. Она распределяется между кэшем и общей памятью блока из множества нитей.
Рейтрейсерная CUDA-программа автора статьи, даже без оптимизации, тоже показала сверхлинейный прирост скорости, относительно прошлого поколения.
А вот чипы AMD Radeon не так хорошо приспособлены для трассировки лучей, не самому удобному неграфическому применению GPU. Там нет кэша, указателей на функции и виртуальных функций и существенное падение производительности относительно теоретического максимума при работе с программами с большим количеством ветвлений. К коим относится большинство алгоритмов в стиле трассировки лучей.
Проблемы пользовательских приложений ↑ ≈
Если GPU так хорошо показали себя в требовательных задачах реалистичного рендеренга, которые, кстати, часто используют для тестирования настольных PC, то что же мешает широкому использованию GPU в других пользовательских приложениях? На самом деле, особенности архитектуры GPU, удобство или неудобство программирования, не имеют для данного вопроса решающего значения. Производителям массового софта просто не выгодно специально оптимизировать программы для части конфигураций. А массовых приложений, так же требующих вычислительную мощность, как трехмерные игры в эпоху до видеоускорителей, сейчас просто нет. Это напоминает историю с оптимизацией для Pentium 4. Только полная доминация в некоторый момент рынка, поноженная на огромный авторитет Intel, заставила производителей софта учитывать особенности данного процессора. А так же огромные вливания в программу поддержки разработчиков. И то, очень скоро, менее привередливая к оптимизации консервативная универсальная архитектура Core сменила Netburst. Отчасти из-за того, что производители софта не проявили энтузиазма по поводу развития технологии Hyper-threading, главной фишки архитектуры Netburst. Видно, как медленно росло и растет число поддерживающих многопоточность приложений и игр. Только недавно высокотехнологичные движки игр стали реально использовать более одного ядра, хотя первые «бытовые» двуядерные процессоры вышли еще в 2005 году. Ведь производители CPU до сих пор успешно выпускают двуядерные модели, а производители софта думают, зачем использовать 4 ядра, если они только у половины-трети пользователей? Сделаем на основе минимума, который есть у всех, благо этот минимум весьма неплох по абсолютной производительности и ещё недавно был совсем недостижимым.
А вот в профессиональных программах для рабочих станций мультипоточность появилась гораздо раньше и распространилась куда быстрее. Такая же точно логика работает в отношении GPU.
Перейдем к примерам. Типичная область применения CUDA, в которой можно ожидать особенно высокого прироста производительности, это обработка видео. Есть программа Badaboom, которая быстро конвертирует видео в разные форматы, в первую очередь, предназначенные для мобильных устройств. Но вот на GeForce 470–480 программа не показывает никакого прироста, потому что она не работает на Fermi. Она оказалась из тех CUDA-программ, которые надо специально адаптировать для Fermi. Причин может быть две, критическая часть могла быть написана на ассемблере GT200 или, более вероятно, она стала выдавать ошибки на Fermi. В новой архитектуре появилась аппаратная проверка корректности адресов в локальной памяти мультипроцессора и глючные программы, вместо того, чтобы незаметно сбоить, не всегда видимым для пользователя образом, стали с треском вылетать при неправильном доступе к памяти. Когда доступ осуществляется к невыделенному участку памяти.
И фирма производитель не стала оперативно исправлять эти недоделки. Вот что она ответила пользователям, практически дословный перевод:
»…мы сконцентрировались на нашей линейке enterprise-продуктов и бросили всех наших GPU-программистов на это направление… мы сначала планируем интегрировать обновленную версию движка кодирования в наши enterprise-решения… поддержка в настольных приложениях планируется на конец года…».
Да, конечно, пользователей Fermi ещё мало, всего несколько сот тысяч, когда наберется целая армия, тогда и будет самое время что-то выпустить и фирма обещает райские сады пользователям Fermi в плане производительности будущей версии. Тут, несомненно, важную роль сыграл высокий процент нелицензионного софта. Причем, эта фирма имеет связи с самой NVIDIA, если вообще не была основана при её участии и они успешно поставляют решения на основе GPU для соответствующих серверов. Что уж говорить о других девелоперах.
Ещё один типичный пример из той же области обработки видео — программа vReveal, которая улучшает качество видео, например, снятого на камеру мобильного телефона и т.п. Она успешно использует CUDA.
Но как она появилась? Фирма MotionDSP, производитель vReveal, специализируется на программах обработки видео потоков с беспилотных летательных аппаратов. Там требуется почти то же самое, что и в пользовательской программе, улучшение качества изображения, избавление от шумов, стабилизация изображения. Данная технология имеет реальный стратегический характер и уже применяется. В беспилотнике стоит промышленный вариант обычного игрового GPU, который в режиме реального времени улучшает качество изображения с камеры самолета. Это главная миссия фирмы, а vReveal — побочный продукт. Впрочем, забегая вперед, в медицине GPU тоже нашли свое место.

А вот противоположенный пример. Одним из ресурсоемких приложений для PC является популярный музыкальный редактор FLStudio. Благодаря большой популярности его даже называют непрофессиональным. Разработчики FL пишут на своём сайте, что если хотя бы один из десяти пользователей FL регистрировал и покупал продукт, они могли бы добавлять плагины музыкальных инструментов в два раза быстрее. Хотя многие из плагинов могли бы теоретически быть ускорены с помощью CUDA, а для Fermi уж точно, и синтетические инструменты приобрели бы улучшенное звучание, использование CUDA вряд ли стоит высоко в списке приоритетов программистов FL.
И ещё одна проблема музыкальных редакторов — большая база достаточно критического к производительности кода. Рендер трассировки лучей менее объёмен, а остальные функции 3D редакторов существенно менее ресурсоемки. А в случае музыки, надо переводить на CUDA множество разнообразных плагинов. Тем не менее, в будущем должен появится музыкальный редактор для CUDA.
Если бы сейчас, в каждом PC стоял, условно говоря, двух- или четырёхъядерный процессор частотой 3 ГГц и графический чип класса Fermi, то множество программ поддерживало бы GPU уже сейчас. В каком-то смысле, тогда компьютер напоминал бы приставку с её плюсами в виде постоянства железа и, соответственно, удобства для разработчика. Но, на данный момент, по мнению некоторых разработчиков, настольные системы превратились в какую-то помойку, игры в первую очередь идут для приставок и так далее.
Возвращаясь к профессиональному софту, ещё один успешный пример использования CUDA — Adobe Premier, и снова софт для обработки видео. С помощью GPU можно в режиме реального времени применять к видео сразу несколько фильтров и регулировать параметры картинки.
Работа с видео — идеальная область для применения GPU, как можно легко понять из описания архитектуры CUDA и не очень трудоемко реализовать несколько ключевых алгоритмов и кодеков. Так что обычным пользователям, которые активно работают с видео, повезло. И неслучайно, что наиболее яркие примеры популярных приложений, получающих поддержку CUDA, происходят из этой области.
Научные вычисления ↑ ≈
А вот кому действительно повезло с CUDA, так это большому количеству ученых. Причем повезло дважды. Во-первых, они получили новый объект для исследования: проблему параллелизации алгоритма на множество потоков с целью адаптации для GPU. Это ведь сама по себе научная задача, какие алгоритмы и методы можно успешно распараллелить и провести на GPU. Ученые любят подобные задачи. На эту тему было защищено множество диссертаций и выпущено множество научных исследований. Во-вторых, собственно возможность ускорить свои вычисления путем перевода их на GPU.
Научное сообщество, в основном, само пишет для себя программы, а не покупает или берет их где-то на стороне. Многие используют собственные алгоритмы, или хорошо известные, или популярные алгоритмы с собственными модификациями. Допустим, университет или научная лаборатория имеют небольшой кластер для своих расчетов и тогда очень легко закупить GPU и запустить модифицированную версию собственной программы.
Очень многие так и сделали и получили большой прирост скорости. Процесс ускорился с выходом архитектуры Fermi, в котором появилась полноскоростная поддержка чисел двойной точности. Впрочем, в некоторых областях науки, молекулярной или электродинамики например, часто достаточно вещественных чисел одинарной точности. И, в этих сферах, вычисления на GPU достигли наибольшего прогресса, что выражено, например, в наибольшем количестве научных работ и результатов.
Правда, точное значение прироста в научных программах трудно измерить, ибо, как правило, перевод на CUDA сопровождается некоторой оптимизацией программы. Допустим, программа плохо поддерживала многоядерность и не использовала SSE или SSE2. А с переводом на CUDA, она стала поддерживать многопоточность и векторность. Так получаются заявленные многими исследователями приросты в 100 раз и больше от использования GPU. С одной стороны нереально, с другой же, многие задачи на CUDA программировать проще, чем в инструкциях SSE с использованием почти что ассемблера, так как CUDA C — это язык программирования высокого уровня. И в GPU L1 кэш программируемый, что во многих случаях удобнее для написания эффективной программы, чем автоматический кэш CPU, который сам загружает, что хочет и надо специально следить, чтобы он загружал то, что нужно. А использование SSE и жесткое слежение за кэшем абсолютно необходимы, чтобы извлечь из CPU близкую к максимальной производительность. А если производительность CPU далека от максимума, то он будет очень блёкло смотреться, по сравнению с эффективной CUDA-программой.
Таким образом, при некоторой одинаковой величине трудозатрат на написание CPU- и CUDA-программы, CUDA-программа будет работать в 100 раз быстрее. В этом смысле прирост на два порядка реален, хотя разница между полностью оптимизированными реализациями будет ниже.
Процессоры предназначены для быстрого исполнения любого кода и, приобретая в универсальности, они теряют в возможностях легкой оптимизации. Для того, чтобы оптимизировать программу на CPU, желательно использовать программы профилирования, типа vtune, которые сложны сами по себе. И это требует квалификации и очень четкого детального знания железа, а при программировании на CUDA главное — придерживаться всего нескольких четких правил. И алгоритмическая оптимизация более привлекательна для ученых, чем копание в железе. Впрочем, покопаться c использованием профайлера можно и в GPU, но вот если сравнить посредственно оптимизированный код для CPU просто с грамотным CUDA-кодом, то прирост вполне может быть в 100 раз. Если программу неудобно векторизировать под SSE из-за мелких ветвлений или сложного шаблона доступа к данным в итерациях цикла, но она подходит для CUDA, то также можно ожидать прироста в десятки раз и относительно эффективной реализации для CPU. Ещё один возможный вариант, когда получается большой выигрыш видеокарты над оптимизированной CPU-реализацией, это когда на CPU программа ограничена пропускной способностью памяти или кэша первого уровня. У GPU выше пропускная способность памяти и суммарная пропускная способность программируемого кэша. Тогда GPU просто перерабатывает больше данных в единицу времени.
Тем не менее, есть задачи, имеющие большое количество приложений в различных областях науки, для которых существуют общепризнанные эффективные CPU-реализации и их скорость можно сравнить с CUDA-вариантами.
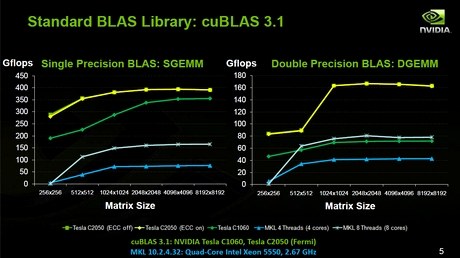
Вот прямое сравнение классической задачи перемножения матриц одинарной и двойной точности, CUDA-реализация против Intel math kernel library, оптимизированной инженерами Intel. Видно, что при использовании чисел одинарной точности и архитектура GT200, и новая, выигрывают в несколько раз. А при двойной, только новая.
Необходимо отметить, что эта задача на самом деле благоволит CPU, она хорошо и легко ложится на все векторные инструкции CPU и её оптимизируют для CPU уже несколько десятков лет. Это позволило почти достичь теоретического максимума производительности. Версия для GPU ещё оптимизируется, собственно железо появилось несколько месяцев назад. Есть сообщения о более высоких результатах в данной задаче.
А вот следующий результат на задачах, которые меньше дружат с SSE:

Прирост большой, но важнее, что его относительно легко получить. Названия научных задач мало что скажут не специалисту, но удивительно, GPU даже быстрее сортирует (Radix sort). И это вполне классическая задача.
И ещё одна типичная задача, преобразования Фурье:

Эта задача больше использует возможности GPU и прирост больше, чем в случае приятного для CPU перемножения матриц. Это тоже прямое честное сравнение на известной популярной задаче, имеющей оптимизированную CPU-реализацию.
Для типичных задач сферы HPC, а именно работы с матрицами, появилось несколько CUDA-оптимизированных библиотек. Они не только умеют перемножать матрицы, но и решать задачи вроде нахождения собственных значений матрицы и LU разложения матрицы. Например, CULA — полукоммерческая библиотека, свободная MAGMA.
CUDA уже нашла свое применение в различных областях науки. И на недавно прошедшей GPU Technology Conference абсолютное большинство докладов было на темы научно-технического использования CUDA. Перечисление названий исследований заняло бы слишком много места, ограничимся только перечислением тем: численные методы, астрономия и астрофизика, обработка звука, облачные вычисления, механика жидкостей, компьютерное зрение, энергетика, финансовая математика, медицина, искусственный интеллект, биология, молекулярная динамика, квантовая химия. И по каждой теме иногда десятки результатов. Обратите также внимание на список участников!
Как отмечается в некоторых докладах, нововведения в архитектуре Fermi позволили расширить область применения GPU и перевести на GPU довольно сложные алгоритмы. Впрочем, большая часть докладов ещё основывалась на прежней архитектуре, исследователи ещё не до конца распробовали все новые возможности.
Одним из интересных приложений CUDA стало использование в проектировании и моделировании работоспособности компьютерных чипов. Исследователи все же нашли способ параллелизации анализа микросхем и ускорения расчетов. Теперь это использует сама NVIDIA для разработки новых чипов. Быть может, это позволит улучшить дизайн новых GPU и избежать ошибок производства, приведших к задержке выпуска Fermi.
А как же обычные пользователи и геймеры? Неужели для них совсем ничего нет?
CUDA в играх ↑ ≈
Радикально улучшенная физика в играх — вот что может предложить GPU уже сейчас. А именно, не просто расчет столкновений объектов, а симуляция сложных явлений и процессов. Типичные примеры: движение воды и колыхание ткани.
Например, море. Допустим, герой игры идет по берегу. Мало нарисовать воду, надо рассчитать, как волны накатываются на берег. Каждый раз они это делают по-разному. Вообще, это сложный физический процесс и чем больше мощности будет, тем натуральнее он будет выглядеть. Дело кончится тем, что в играх отрисовка самой поверхности воды будет занимать существенно меньше времени, чем расчет её движения. А в воду ещё можно что-то бросить. Это неисчерпаемая тема. И море возможностей применения GPU для физических симуляций.
Вот пример из CUDA SDK для GT200, расчет простой модели движения волн. Тем не менее, это физическая модель, в ней рождаются волны, это не просто колебание воды по закону синуса:

А вот уже более продвинутая демка для Fermi на тему воды, с последней GTC:
Когда это будет? Когда достаточно распространятся мощные видеокарты с поддержкой DirectX11. Причем, в отличие от трассировки лучей, видеокарты ATI/AMD тут более конкурентны, так как используемые математические уравнения лучше поддаются векторизации и элиминации ветвлений. Это плюс для всех геймеров, более широкая поддержка сильнее подтолкнет разработчиков к использованию GPU.
Улучшения в архитектуре Fermi ↑ ≈
В недалеком будущем ожидается появление ещё большего количества приложений для GPU. Залогом этому являются новые возможности в Fermi, а именно поддержка возможностей C++. В первую очередь, работа со сложными структурами данных. На GT200 трудно организовать внутренний менеджер памяти и выделение данных по мере необходимости в процессе вычислений. Как правило, приходилось всю память выделять при запуске программы. Трудность заключалась в том, что различные нити могли общаться только через медленную глобальную память и если одна нить выделяла из некоторого общего пула свой кусок памяти, она должна была установить соответствующий счетчик, расположенный в медленной глобальной видеопамяти и другие нити, при выделении памяти, должны были его считывать. Причем, все операции должны были быть атомарными, то есть в один момент только одна нить имела доступ к переменной. Из-за высокой латентности памяти, это было невероятно медленно.
Но появление общего L2-кэша радикально, в десятки раз, ускорило атомарные операции с памятью, что позволяет организовать достаточно быстрый внутренний менеджер памяти, чтобы выделять память каждой нити в процессе работы. И, соответственно, реализовать функции языка программирования C для работы с памятью, malloc, free. В данном случае, использующий динамические структуры данных алгоритм тоже получает ускорение на порядок.
В Fermi также улучшен доступ к глобальной памяти. В предыдущей архитектуре глобальная видеопамять была разделена на 6 банков и желательно было, чтобы запросы на чтение, в отдельный момент времени, соответствовали различным банкам. Это требовалось для того, чтобы запросы могли быть исполнены параллельно с максимальной скоростью. Сейчас это ограничение снято. Так же ускорен доступ к локальной памяти мультипроцессора, которая тоже разделена на банки.
Появление настоящих функций с рекурсией позволяет легко запрограммировать все, что угодно. Таким образом, позволяя перенести больше расчетов на GPU и сэкономить на (относительно) медленном трафике с оперативной памятью по шине PCI Express. Причем, даже ту часть программы, которая в принципе не очень дружелюбна для архитектуры GPU. Пусть она будет работать медленней внутри GPU, но уменьшение числа операций обмена по шине вполне может окупить себя. Ускорение других частей программы позволит в целом добиться прироста.
Проблема передачи данных в GPU — одно из основных препятствий при переводе программы на GPU, и любой сдвиг в этом вопросе значительно расширяет множество портируемых программ. С реализацией C++ на GPU стало возможно легко написать почти любую программу и, если она хорошо распараллеливается на тысячи нитей, то с высокой вероятностью будет работать значительно быстрее, чем на CPU.
Заключение ↑ ≈
На этот раз волна инноваций в компьютерной сфере пока обходит стороной сектор персональных пользовательских систем. Новая идеология: если вам нужно работать с задачей, требующей интенсивных вычислений, можете взять GPU и работать с ним сами. Благо, теперь на Fermi можно запрограммировать практически всё, что разбивается на тысячу потоков. Или целенаправленно попросить некоторую фирму предоставить вам решение с поддержкой GPU. В выигрыше от CUDA те, для кого время вычисления — действительно деньги. Обычные же «пользователи компьютера» будут пока что довольствоваться отдельными приложениями, которые произошли из сферы рабочих станций, и ждать распространения мощных GPU, новых игр и программ.
Ссылки ↑ ≈
Полный текст статьи читайте на nvWorld.ru
