Новые гибкие платформы решили проблему нехватки процессоров и памяти
Гиперконвергенция — что это и зачем
Первые серверы Cisco UCS появились на рынке в конце 2009 г., когда основным трендом была консолидация вычислительных ресурсов в ЦОД и активно внедрялись технологии виртуализации. Основная задача, на решение которой были тогда брошены все силы, заключалась в оптимизации подключений серверов к сетям (LAN, SAN, управления) и упрощении настройки пула серверов, выполняющих однотипные задачи. Решение получилось настолько мощным и элегантным, что всего за 5 лет блейд-решения Cisco UCS вышли на второе место в мире по объему продаж (это на полностью новом для компании рынке, на котором многие игроки присутствовали на тот момент более 10 лет!). Немалую популярность серверным решениям от Cisco обеспечил конвергентный подход, при котором в рамках одного инфраструктурного «кубика» объединялись серверы Cisco UCS, система хранения Netapp и универсальные коммутаторы для ЦОД семейства Nexus 5000. Такое совместное решение получило название FlexPod, оно и сегодня не теряет своей популярности, пережив смену пяти поколений серверов UCS и несколько поколений дисковых массивов NetApp.
Основное преимущество, за которое заказчики Cisco полюбили конвергентные решения (а на текущий момент их существует около десятка, с разными производителями дисковых массивов) — это простота, надежность и предсказуемость в эксплуатации. По данным одного из исследований компании IDC от 2016 г., когда конвергентные системы еще учитывались отдельно, более 70% продаваемых конвергентных решений для ЦОД были построены на серверах Cisco UCS.
Но прогресс не стоит на месте, и последние несколько лет рынок начал завоевывать новый подход к построению ИТ-инфраструктур — гиперконвергенция. Новое поколение молодых компаний предложило подход, при котором внешняя система хранения не нужна вообще. И хранение и обработка данных происходят на одних и тех же серверах, заполненных дисками, процессорами и оперативной памятью. Отказоустойчивость обеспечивается хранением нескольких копий одних и тех же данных на разных серверах, поэтому не страшно, если один их узлов выйдет из строя, данные не пропадут и виртуальная машина может быть перезапущена на соседнем сервере. Новый подход поначалу настороженно воспринимался традиционными производителями серверов (к числу которых к концу 2015 г. компания Cisco могла себя уверенно причислять). Однако заказчикам гиперконвергенция понравилась, в первую очередь за простоту внедрения и расширения. О производительности и удобстве эксплуатации тогда еще мало кто думал, предлагаемые на тот момент решения проигрывали по этим параметрам конвергентным аналогам. Компания Cisco вышла на рынок гиперконвергентных решений с продуктом Cisco Hyperflex в 2016 г. через партнерство с компанией SpringPath, производителя самой продвинутой на тот момент объектно-ориентированной программно-определяемой системы хранения. И тут выяснилось, что все преимущества аппаратной платформы Cisco UCS позволяют получить существенный выигрыш в производительности и простоте эксплуатации гиперконвергентных решений. Накопленный за два с небольшим года опыт продаж Hyperflex и более чем 3,5 тыс. заказчиков по всему миру свидетельствуют о зрелости этого подхода. Давайте разберемся, что же собой представляет Cisco Hyperflex и для каких задач его нужно применять уже сегодня.
Технологический обзор. А что нового?
Про внутреннее устройство платформы Cisco Hyperflex уже сказано немало, отметим лишь, что система состоит из двух обязательных компонентов и одного опционального:
Первый — кластер данных (Data cluster, обязательный компонент) — это набор узлов, обеспечивающих хранение данных и запуск виртуальных машин. Узлы строятся на базе серверов C220 и C240 и представляют собой фиксированные конфигурации указанных серверов с префиксом HX. Единственными параметрами, которые можно менять, являются процессоры, память и диски для хранения данных, то есть все, что определяет «вычислительные ресурсы» кластера. Минимальное количество таких узлов в рамках одного кластера данных — три. Начиная с версии HX Data platform 4.0, выход которой ожидается в апреле 2019 г., анонсировано уменьшение минимальной конфигурации кластера Hyperflex Edge до двух узлов.
Второй — вычислительная фабрика (Fabric interconnect, обязательный компонент, кроме конфигурации Hyperflex Edge) — это пара специализированных устройств, выполняющих функции сетевого ядра системы и, одновременно, модуля управления серверами и внешними подключениями. Это ключевой элемент инфраструктуры Cisco UCS, благодаря фабрике все серверы UCS, сколько бы их ни было, настраиваются по единому шаблону, в один клик мышки или один вызов API функции (да-да, управление аппаратной платформой UCS возможно через открытый API) и полностью автоматически. Более того, система сама следит за тем, чтобы все серверы в кластере имели идентичные настройки, сама по команде администратора в автоматизированном режиме обновляет прошивки и так далее. С Fabric Interconnect весь кластер серверов становится единым объектом управления, таких возможностей на сегодняшний день нет ни у одного производителя серверных решений. Сегодня доступны два семейства Fabric Interconnect 6300 серии с портами 40 Гбит/с и 6400 серии с портами 10/25 Гбит/с. Оба семейства имеют модели в портами FC для подключения к сетями SAN, это дает возможность использовать для хранения данных внешние дисковые массивы тоже.
Третий — вычислительные узлы (Compute-only nodes, необязательный компонент). Часто при расширении гиперконвергентной системы возникает ситуация, когда дискового пространства уже достаточно, а вот процессоров и памяти под текущие задачи не хватает. Бывает и наоборот, но эту проблему легко решить добавлением дисков в серверы или, если они заполнены — внешнего дискового массива к вычислительной фабрике. На случай нехватки в кластере вычислительных ресурсов предусмотрен режим расширения через добавление вычислительных узлов. В качестве таких узлов могут выступать любые серверы Cisco UCS, подключенные к фабрике, неважно — в стоечном или блейд-исполнении. Кроме гибкости в планировании ресурсов, основным преимуществом данного подхода является возможность дать «вторую жизнь» серверам, работавшим в традиционной, конвергентной системе, после того, как их вычислительная нагрузка мигрировала на Hyperflex. Вторым популярным сценарием является подключение в кластер 4-процессорного сервера C480, в который можно установить до шести графических ускорителей (GPU) для «тяжелых» VDI-решений.
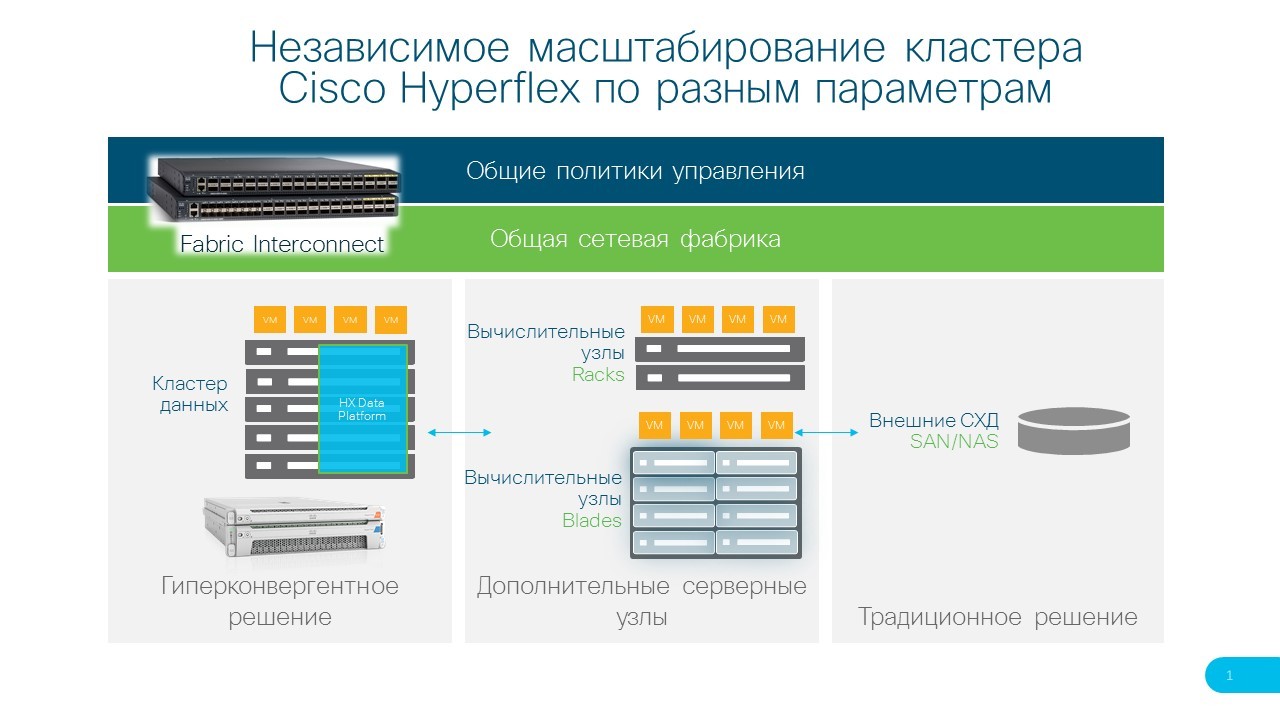
Общая схема кластера Hyperflex с обозначением всех указанных компонентов
Важным свойством платформы Hyperflex является то, что без изменения архитектурного подхода и без перепроектирования, на этой платформе можно строить кластера виртуализации от трех до нескольких десятков серверов. Все необходимые процедуры по настройке нового сервера и включения его в кластер полностью автоматизированы, пользователю достаточно только включить сервер и подтвердить системе свое желание на ввод его в состав кластера. Это открывает перед системой самый широкий диапазон применений — от локальных серверных в удаленных офисах, складах, магазинах, до центральных дата-центров с основными сервисами компании. И все это — на базе единой платформы, единых принципах управления, автоматизации и, что немаловажно, — на базе решений единого вендора. Последний факт дает еще одно преимущество — техническая поддержка Cisco Hyperflex целиком и полностью обеспечивается компанией Cisco по схеме «единого окна». Даже если проблема будет связана с функционированием платформы виртуализации (на сегодняшний день поддерживаются VMware, Hyper-V и Docker), решением этой проблемы для заказчика будет заниматься техническая поддержка Cisco.
Для каких задач эта система?
Давайте рассмотрим, под какие задачи позиционируется сегодня Cisco Hyperflex. Изначально гиперконвергентные системы лучше всего показывали себя на задачах виртуализации рабочих мест (VDI). Это логично, учитывая архитектуру подсистемы хранения — множество отдельных дисков, распределенных по серверам. Если нагрузок тоже много и каждая из них сама по себе небольшая — получаем идеальное равномерное распределение операций ввода-вывода. Но инженеры Cisco пошли дальше! Основным фактором, ограничивающим производительность гиперконвергентной платформы является сетевое ядро. Ведь для обеспечения отказоустойчивости данных, как мы помним, используется хранение одного и того же блока данных на нескольких серверах. Поэтому при записи система не имеет права сказать приложению, что запись завершена, пока данные реально не будут скопированы на один или два сервера. А раз копирование производится по сети — сеть становится узким местом. В Cisco Hyperflex сетевое ядро построено, как мы помним, на Fabric Interconnect, устройствах, имеющих необлокируемые порты с самой низкой, и главное, предсказуемой задержкой среди подобных систем. Поэтому разработчики платформы HX Data Platform приняли решение писать данные сразу по сети на необходимое количество серверов, задействуя, таким образом, все доступные диски кластера для хранения данных всех виртуальных машин. Такое решение имеет еще одно важное преимущество — при отказе одного из узлов, не нужно отслеживать, где лежат резервные данные виртуальных машин, чтобы обеспечить им большую производительность, можно запустить их на любом оставшемся сервере и никаких проблем с производительностью машины не будет. Общая производительность кластера также «не проседает» — это позволяет использовать систему для бизнес-критичных нагрузок.
Все эти архитектурные особенности привели к тому, что система Cisco Hyperflex достаточно быстро перешла из сегмента «платформа для VDI» в сегмент платформ для любых виртуализированных нагрузок. Появление систем на базе твердотельных накопителей только ускорили этот переход. Если до появления All flash-систем максимальный размер виртуальных машин, которые заказчики запускали на Hyperflex, не превышал 2 ТБ (размер единичного диска), то на All flash-системах отлично работают базы данных Oracle и MS SQL до 10 ТБ. Подтверждением тому являются документы CVD (Cisco Validated Design, типовые дизайны Cisco), описывающие архитектуру таких решений.
Также Cisco Hyperflex является единственной гиперконвергентной платформой, сертифицированной одновременно на три основных компонента ландшафта SAP — Application, Data Hub и HANA.
Отдельно нужно сказать про поддержку контейнерной инфраструктуры — в мае 2018 г. компанией Cisco был выпущен продукт Cisco Container Platform (CCP), созданный в партнерстве с компанией Google. Это, по сути, готовая сборка кластера Kubernetes с контейнерной виртуализацией Docker. Container Platform полностью автоматизировано устанавливается на Cisco Hyperflex и включен в программу технической поддержки компании Cisco. Таким образом, ИТ-департамент получает возможность создать готовую платформу под контейнерную виртуализацию и брать на поддержку разработанные в компании сервисы без необходимости развивать у себя эту экспертизу.
Подытоживая сказанное, нужно отметить, что платформа Cisco Hyperflex представляет собой принципиально новое универсальное решение для задач построения вычислительной инфраструктуры. Решение, которое на единых принципах, с единым интерфейсом управления может масштабироваться от двух до нескольких десятков серверов и поддерживать широкий круг приложений, от базовой инфраструктурной нагрузки до среднего размера СУБД, ландшафта SAP, различных самописных приложений, алгоритмов машинного обучения и так далее.
А что с отказоустойчивостью?
Hyperflex может использоваться для самого широкого круга задач, а потому возникает вопрос — как обеспечивается отказоустойчивость решения, особенно если речь идет о критически важных сервисах?
Защита данных внутри кластера от потери одного из узлов обеспечивается хранением нескольких копий одних и тех же блоков данных. В Cisco Hyperflex может храниться две или три копии данных, это задается настройками кластера при его создании. В зависимости от этого, кластер может «пережить» полную потерю одного или двух узлов. Дополнительно существует возможность задавать «домены отказа» — эта настройка актуальна для кластеров большого размера — в десятки узлов. Если ее указать и, например, разнести серверы, находящиеся в трех разных стойках по трем доменам, то внутри каждой стойки никогда не будут храниться все копии данных. Поэтому, даже если вся стойка выйдет из строя целиком — например, в случае обрыва сетевых кабелей или выключения обоих лучей питания, — копия данных гарантированно будет доступна в оставшихся рабочими стойках.
Отдельно следует сказать об объеме необходимого для хранения данных дискового пространства. Поскольку для обеспечения отказоустойчивости система хранит несколько копий данных, нужен какой-то механизм, который бы оптимизировал дисковое пространство, иначе объем полезных данных будет в 2–3 раза меньше, чем «сырая» емкость дисковых накопителей. Для этих целей в традиционных системах хранения давно придумали использовать дедупликацию и компрессию данных. В Hyperflex также встроены эти механизмы, причем реализованы они на архитектурном уровне и встроены в общие процессы работы с данными. Этот механизм никак не нужно включать, он работает по умолчанию даже в самых младших моделях, и он не требует отдельного лицензирования — все уже включено в стоимость системы. Все данные, записываемые на диски серверов сначала дедуплицируются, то есть при совпадении двух и более блоков данных хранится только одна копия. Затем дедуплицированные данные дополнительно еще и сжимаются. Суммарно по статистике это дает экономию от 40% до 60% места на данных общего характера, но для отдельных категорий, например, дисков виртуальных десктопов, может достигаться кратная экономия дискового пространства.
Следующим уровнем защиты от сбоев кластера Hyperflex является репликация данных на удаленный кластер. Начиная с версии 3.5 доступны два режима репликации — синхронный и асинхронный. Оба этих режима могут работать по обычной IP-сети, для них не требуется ни сеть SAN, ни «темная оптика». Единственным ограничением синхронного режима репликации является скорость канала — 10G и длительность задержек между кластерами — не более 5 мс. Оба режима очень просты в настройке, выполняются из единого интерфейса и позволяют гибко контролировать, какие виртуальные машины будут реплицироваться между кластерами. Особое внимание нужно обратить на то, что контроль осуществляется именно на уровне виртуальных машин, а не дисковых разделов — в этом ключевое отличие от режима репликации традиционных конвергентных решений. Поскольку Hyperflex на удаленной площадке получает информацию о виртуальной машине, процесс восстановления тоже предельно прост — нужно просто запустить виртуальную машину на удаленной площадке. Не требуется никаких скриптов и кластерного ПО. В асинхронном режиме копирование производится с небольшой задержкой, которая зависит от пропускной способности канала и интенсивности ввода-вывода виртуальной машины. В синхронном режиме (он еще называется растянутый кластер) на обоих узлах хранятся полностью идентичные копии виртуальных машин.
Следующим после репликации данных уровнем защиты традиционно является резервное копирование и здесь в Cisco Hyperflex также есть, о чем поговорить. Во-первых, система имеет встроенный механизм создания мгновенных копий данных диска любой виртуальной машины. Этот механизм основан на работе с указателями на блоки данных, а значит работает очень быстро. Во-вторых, многие продукты для реализации резервного копирования имеют встроенную интеграцию с механизмом мгновенных копий Hyperflex, и при использовании этого механизма, окно резервного копирования существенно (в разы) сокращается по сравнению со стандартным режимом. В число таких продуктов входят решения по резервному копированию от Veeam, CommVault, Cohesity. Со всеми этими решениями у Cisco также есть типовые дизайны, которые позволяют значительно сократить время реализации системы и избежать распространенных ошибок. Также все эти решения можно приобрести через прайс-лист Cisco, чтобы получить законченное решение от одного поставщика.
Используя все описанные выше механизмы, уже сегодня с Cisco Hyperflex можно построить современную надежную платформу виртуализации с любым необходимым уровнем отказоустойчивости.
Как внедрять гиперконвергенцию
После прочтения обо всех плюсах гиперконвергенции у многих читателей может появиться мысль: «Прекрасно, но у меня ведь есть традиционная система, что мне делать с ней?». Развитие любой системы должно учитывать инвестиции, сделанные в прошлом, и для перехода на гиперконвергентную платформу должны быть какие-то основания. Самое логичное — внедрение новых сервисов или вывод из промышленной эксплуатации устаревшего оборудования. В обоих случаях заказчик получает входные данные для расчетов — требуемый объем вычислительных мощностей, выраженный в процессорах, памяти и дисковом пространстве. В последнее время часто нехватка даже одного из этих параметров, например, дискового пространства, может привести к старту проекта по переходу на гиперконвергентную платформу. Всегда имеет смысл сравнить стоимость «апгрейда» традиционного дискового массива со стоимостью приобретения гиперконвергентной системы. И если цена не отличается более чем на 10–15%, то переход на Cisco Hyperflex однозначно выгоднее в долгосрочной перспективе, так как позволяет значительно упростить операционные затраты на поддержку в ближайшие 3–5 лет.
Вторым шагом необходимо определить, какие компоненты системы и в какой конфигурации нужно закупить, чтобы построить гиперконвергентную платформу. И тут, конечно, в выигрыше окажутся заказчики, которые уже используют серверную фабрику Cisco UCS. Ведь при наличии Fabric Interconnect их не нужно закупать отдельно — можно использовать существующие при условии наличия свободных портов. В этом случае можно просто купить минимум три узла Hyperflex и приступать к построению кластера. И главное — в этом случае можно рассчитывать в будущем использовать имеющиеся узлы в качестве вычислительных (Compute only) узлов гиперфлекса, то есть существующие инвестиции не пропадают. Да и существующий дисковый массив тоже можно подключить к кластеру, как описано выше и использовать для хранения архивных копий или другой нагрузки. Если же на текущий момент серверов Cisco UCS у заказчика нет, нужно закупать всю инфраструктуру целиком, включая Fabric Interconnect, но, во-первых, в любой другой платформе все равно будут требоваться коммутаторы и эту статью расходов все равно нужно учитывать, а во-вторых, по данным компании IDC (исследование от 2016 г.) переход на фабрику Cisco UCS в горизонте трех лет сокращает совокупную стоимость владения серверной инфраструктурой на 46%, поэтому эта инвестиция в развитие очень быстро окупится.
Компания Cisco надеется, что после прочтения этой статьи у вас не осталось сомнений, что гиперконвергенция — это прорывная технология, и опыт последних лет показывает, что за ней будущее. Системы Cisco Hyperflex, несмотря на свою относительную молодость, являются зрелым, апробированным решением, доказавшим свою надежность в инфраструктуре 3,5 тыс. заказчиков по всему миру.
Короткая ссылка на материал: http://cnews.ru/link/a13391
Полный текст статьи читайте на CNews
