Конференция Nvidia GTC 2017: технологии искусственного интеллекта
Технологии искусственного интеллекта
Содержание

Введение
Все знают, что компания Nvidia вот уже несколько лет занимается далеко не только традиционным для них рынком игровых графических процессоров, они постоянно пробуют другие рынки, открывая новые ниши. Не все их начинания были успешными, в мобильных устройствах дела толком так и не пошли, зато в сфере профессиональных графических и вычислительных решений дела компании продвигаются отменно. Более того, если в сегменте профессиональной графики их успехи известны давно, то на рынки процессоров для высокопроизводительных вычислений и автомобильных систем они вышли сравнительно недавно и уже имеют некоторый успех.
Например, если посмотреть на ежеквартальные финансовые отчеты Nvidia на протяжении пары последних лет (в таблице ниже приведены финансовые годы, отличающиеся от календарных), то можно отчетливо увидеть несколько интересных трендов. Так, несмотря на все сложности индустрии ПК, конкретно игрового применения они практически не касаются, и компания смогла значительно увеличить выручку в этой сфере за последние кварталы, а ведь именно ПК-игроки в основном и оплачивают разработки и в других сферах деятельности Nvidia, как минимум частично.
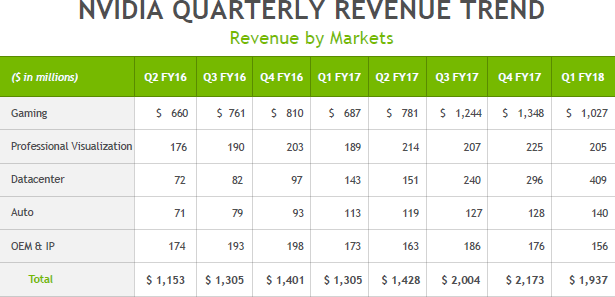
Но самое интересное в таблице совсем в других строчках. Если доходы от поставок профессиональных графических решений за пару лет практически не изменились, то в сфере автомобильных решений есть хоть и не огромный, но все же очень приличный двукратный рост за два года. Но самое важное кроется в строке Datacenter, которая и обозначает получающие все большее распространения решения для высокопроизводительных вычислений: серверов, дата-центров и т. д. Именно в этой сфере продажи выросли за два с небольшим года более чем в пять раз! Неудивительно, что Nvidia прикладывает большое количество сил для того, чтобы тренд продолжался. А пройдет несколько лет, и игровые решения компании и вовсе уступят первенство серьезным вычислительным задачам. Хотя ПК-игрокам в любом случае большой почет за то, что они оплачивают технический прогресс.
Кстати, а что такое высокопроизводительные вычисления вообще? К примеру, искусственный интеллект (ИИ), мощность которого растет в полтора-два раза каждый год, что позволяет разработчикам различных программно-аппаратных решений входить в различные сферы деятельности. Так, нейросети и прочие системы искусственного интеллекта, которым ранее тупо не хватало вычислительной производительности, уже сейчас умеют: полностью автономно пилотировать автомобили (этим сейчас занимаются практически все, начиная с Tesla), распознавать речь и быть интеллектуальными помощниками на мобильных устройствах (Siri, Cortana, Google Assistant, Bixby и другие), распознавать объекты на фото и видео и описывать их лучше человека, распознавать лица, увеличивать разрешение изображений (почти как в старых кинофильмах о спецслужбах), копировать голоса (стартап Lyrebird), играть во многие логические игры (шахматы и го) лучше человека, писать какие-никакие стихи, музыку, тексты (робот от стартапа Keywee пишет статьи и новости для издательств BBC, CNN, The New York Times, AOL и Forbes), рисовать картины на основе стилей существующих художников (Prisma), делать видеомонтаж (банальный Ассистент Google Photo на современном смартфоне делает из нескольких фотографий и видео один ролик — неидеально, но вполне приемлемо), приложение Google Now умеет подсказывать человеку то, что ему может пригодиться: расписание транспорта, прогноз погоды и т. д., помогать искать лекарства от болезней (очень много компаний), бороться со старением, помогать распознавать различные болезни, вроде различных видов рака, помогать при разработке нефтяных месторождений (поиск оптимальных мест для бурения), и многое-многое другое.
Взрывного роста от применения ИИ можно ожидать от любой из этих сфер, та же медицина вскоре должна сделать большой рывок в повышении эффективности и точности диагностики с применением систем обработки и систематизации анализов, использующих искусственный интеллект. Давно известно, что установка правильного диагноза является важнейшей задачей, да и при лечении системы ИИ применяться будут. Одна из североамериканских компаний уже получила одобрение контролирующих органов на использование подобной системы с применением искусственного интеллекта для расшифровки результатов обследований сердечно-сосудистой системы, и это только начало.
Уже сейчас во многих областях ИИ выполняет задачи лучше и/или быстрее человека, и это будет лишь усугубляться. Если добавить к указанному выше и различных роботов, то можно добавить к списку кучу умений, которые приведут к тому, что масса профессий и занятий человека просто отомрет, начиная с тех самых дальнобойщиков (этого бы им уже нужно начинать опасаться, а не взимания оплаты при доставке грузов) и таксистов — компаниям типа Uber в не таком уж и далеком будущем они просто не понадобятся! Туда же отправятся актеры с операторами и монтажерами, и многие-многие другие. Бухгалтеры, экономисты, журналисты… Да много кто. Конечно, для всего этого понадобится время, но кое-что из описанного выше мы имеем шанс увидеть еще при нашей жизни. И уже сейчас нужно готовиться ко всему этому. Даже если вы повар, к примеру, и относительно спокойны за ваше будущее — это совсем не значит, что о нем не нужно позаботиться. Например, придумав, как применять искусственный интеллект в своей работе.
Вычислительная мощность современных вычислительных систем растет, и если раньше содержать нейронные сети было слишком дорого или вообще невозможно, сейчас глубокое обучение и нейронные сети для решения своих задач могут позволить себе даже небольшие компании. Рост вычислительных возможностей дает возможность применять нейросети во все большем круге применений. И эксперты действительно прогнозируют планомерный рост внедрения решений с применением систем искусственного интеллекта в широком спектре отраслей промышленности. По мнению аналитиков компании IDC, использование технологий на основе искусственного интеллекта через пять лет принесет 47 миллиардов долларов дохода — по сравнению с 8 миллиардами долларов в 2016 году.
Посмотрите еще раз на табличку с финансовыми показателями компании Nvidia, где доход с HPC-рынка пока еще более чем вдвое уступает игровым решениям. Вероятно, уже через несколько лет все перевернется с ног на голову. Конечно, не они одни будут получать дивиденды с этого рынка, который гранды не отдадут им просто так, но у Nvidia сейчас на нем очень неплохие позиции и явно виден их большой потенциал. Конечно, большой куш им вовсе не обеспечен, так как существует полно конкурентов, обладающих большим капиталом и опытом в этой сфере. Однако именно Nvidia вовремя вскочила на этот поезд одной из первых, у них есть действительно отличное аппаратное и программное обеспечение, и компания продолжает улучшать свое положение, развивая связи с разработчиками по всему миру.
Как сами видите, интерес к вычислительным применениям когда-то исключительно графических процессоров в последние годы значительно вырос, и сейчас решения компании Nvidia, основанные на их вычислительных архитектурах, успешно применяются во многих сферах. Еще много лет назад компания организовала собственное мероприятие, посвященное применению их решений в широком наборе задач — GPU Technology Conference. В этом году очередная ежегодная конференция в Калифорнии проходила не в привычном марте, а в мае, но все так же традиционно в городе Сан-Хосе — сердце Кремниевой Долины.
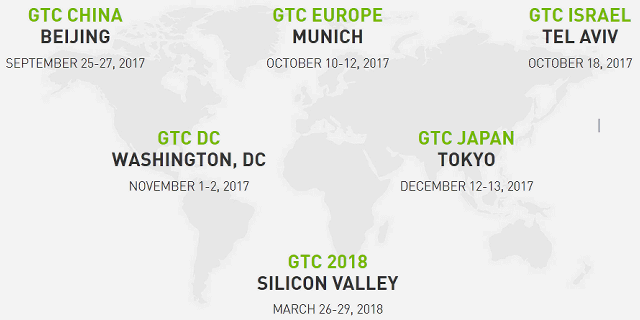
И даже больше того — технологическая конференция GTC сейчас проходит несколько раз в год в разных городах мира, в том числе в Китае, Европе, Израиле, Японии и паре городов США (Сан-Хосе и Вашингтон). В калифорнийской части GTC этого года участвовало 7000 человек (крупнейшие компании из разных сфер деятельности, AI-стартапы, разработчики программного обеспечения, инвесторы, пресса, аналитики и многие другие), было проведено 600 технических сессий и 310 сессий, посвященных именно искусственному интеллекту, расположено 150 стендов, 178 постеров и 67 лабораторий по технологиям глубокого обучения. GTC давно стала главным мероприятием для компании, и именно тут делаются главные анонсы Nvidia, а также становится понятно, к чему это все приведет через несколько лет. Вот об этом мы сегодня и поговорим.
Новая вычислительная архитектура Volta
В рамках ключевого выступления главы компании Дженсена Хуанга, им было сделано несколько самых важных анонсов, в том числе представлена новая архитектура графических процессоров Nvidia Volta, а также серия аппаратно-программных решений на их основе, которые ускорят и упростят работу с различного рода вычислениями, а особенно — искусственным интеллектом (в частности — глубоким обучением). Дженсен не разочаровывает публику на GTC, его выступления всегда интересны и многогранны. Неудивительно, что разговор с самого начала зашел о революции, которая происходит благодаря быстрому развитию искусственного интеллекта (ИИ).
Nvidia как бы подстраивает закон Мура под себя, оценивая рост производительности систем, включающих вычисления на GPU. Если процессоры общего назначения ранее обеспечивали требуемый 1,5-кратный рост производительности, то в последние годы он снизился до +10% в год (речь об однопоточной производительности, конечно же), что не может удовлетворить индустрию. Но если учитывать прирост в скорости, даваемый графическими процессорами, то в целом полуторакратное ускорение в год вполне достижимо на практике и сейчас. А к 2025 году ожидается и тысячекратный прирост, а ведь это время настанет всего лишь через несколько лет.
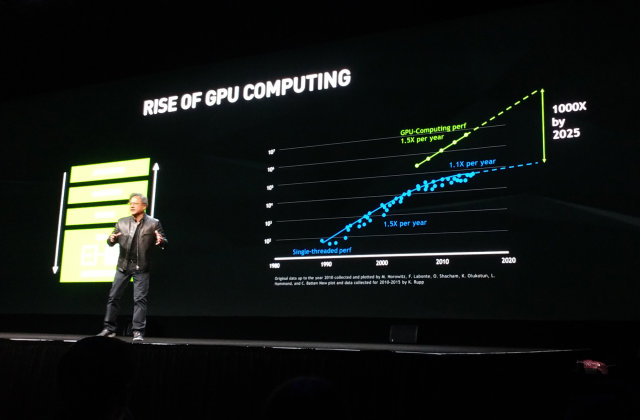
За прошедшие годы вычислениями на графических процессорах производства Nvidia заинтересовались уже более полумиллиона разработчиков (это более чем в 10 раз больше, чем всего пять лет назад), число участников конференции GTC выросло втрое до 7000 человек, а число загрузок среды разработки CUDA за прошедший год составило более миллиона раз. И многие из существующих разработчиков используют мощь GPU именно для имитации искусственного интеллекта.
Круг задач, в которых применяется ИИ, весьма обширен: сложный поиск, распознавание изображений и голоса, роботизация, автопилотируемые самолеты и автомобили, медицина, перевод с разных языков и многое-многое другое. Инвестиции в ИИ-стартапы достигли пяти миллиардов долларов в прошлом году, а количество обучающихся по соответствующим программам выросло в сотни раз. Компания Nvidia уже некоторое время очень плотно занимается задачами, связанными с ИИ и машинным обучением, они выпускают множество аппаратных и программных решений для этих сфер применения. И сложность задач, поставленных перед ними, постоянно растет, каждый год требуя вдвое, а то и втрое-вчетверо большей общей производительности.
Именно поэтому индустрии высокопроизводительных вычислений потребовался даже еще больший скачок, чем привычные 1,5 раза ускорения в год. Также на всю индустрию повлияли и анонсы специализированных решений для машинного обучения, вроде Tensor Processing Unit (TPU) от Google, вторая версия которого была объявлена чуть позднее. Вот и Nvidia решила не отставать, представив новое поколение вычислительной архитектуры Volta, в который вошли специализированные блоки, которые и обеспечили пятикратное преимущество по скорости по сравнению с Pascal в задачах глубокого обучения.

Для понимания сложности задачи, Дженсен привел такие данные: в процессе разработки архитектуры Volta и первого вычислительного процессора на его основе, получившего название Tesla V100, было потрачено три миллиарда долларов. Новый GPU включает более чем 21 млрд. транзисторов, объединяя ранее известные нам ядра CUDA и новые специализированные ядра Tensor core, обеспечивающие производительность в задачах обучения и инференса нейронных сетей, идентичную сотне CPU!
При огромной площади кристалла в 815 мм² неудивительно, что даже использование самого передового 12-нанометрового FFN-техпроцесса компании TSMC позволило сделать его лишь на самой грани нынешних возможностей фотолитографии. Чип получился очень большой и дорогой во всем, и инженерная команда Nvidia в лице Джона Албена (Jonah Alben), старшего вице-президента по проектированию GPU, благодарна Дженсену за то, что он дал им возможность поработать над столь сложным и многообещающим проектом.
Всего в графический процессор входит 5120 вычислительных ядер CUDA и 640 новых специализированных тензор-ядер (Tensor core), созданных для ускорения работы искусственного интеллекта. Для этого GPU поддерживает новые инструкции и форматы данных, удобные для обработки массивов матриц 4×4 следующим образом: D[FP32] = A[FP16] * B[FP16] + C[FP32]. Ядра считывают два значения с FP16-точностью, упакованные в один регистр, их перемножение осуществляется с FP32-точностью, результат суммируется с FP32-значением и записывается с 32-битной же точностью. Для задач глубокого обучения такой точности вполне достаточно, а может, эта возможность и в других задачах пригодится.

В итоге новое решение Tesla V100 имеет производительность в 1,5 раза выше в традиционных высокопроизводительных вычислениях по сравнению с Tesla P100 на архитектуре Pascal, а в задачах глубокого обучения, где включаются в работу тензор-ядра, прирост скорости составляет от 6 до 12 раз в зависимости от задачи! Об этом же говорят пиковые цифры производительности: 30 FP16 TFLOPS (удвоенная скорость вычислений с половинной точностью никуда не делась) или 15 FP32 TFLOPS или 7,5 FP64 TFLOPS или 120 новых тензор-TFLOPS. Возвращаясь к закону Мура, Nvidia заявляет, что эти цифры вчетверо больше тех, что он предсказывал.
Кроме этого, первый GPU архитектуры Volta отличается применением 16 ГБ высокоскоростной HBM2-памяти, разработанной совместно с Samsung, имеющей пропускную способность в ПСП 900 ГБ/с — на 50% выше, по сравнению с предыдущим поколением. А для связи между графическими процессорами и между графическим и центральным процессорами применяется высокоскоростной интерфейс NVLink нового поколения, отличающийся вдвое увеличенной пропускной способностью по сравнению с предыдущим поколением — 300 ГБ/с.

Если говорить об архитектурных изменениях в традиционных ядрах, то и тут они есть. Декодеры и планировщик запускают по одной инструкции и одному варпу за каждый такт, и всего выполняется вдвое больше инструкций и варпов на каждый мультипроцессор за такт, по сравнению с Pascal. Новая архитектура позволяет чередовать два варпа на различных исполнительных устройствах. Так, GP100 не умеет выполнять FP32 и INT32 инструкции одновременно, а мультипроцессоры GV100 включают отдельные FP32 и INT32 ядра, позволяющие одновременное исполнение таких операций на полной скорости, что увеличивает общую эффективность GPU.
Специалисты компании говорят, что одно из самых больших изменений в Volta — новые планировщики потоков и декодеры (dispatch unit), а соответственно и алгоритмы управления потоками и варпами, которые стали более эффективными. Также в новом GPU есть L1-кэш объемом в 128 КБ, обладающий низкими задержками и большой пропускной способностью, который упростит исполнение задач, по каким-либо причинам не использующих разделяемую память.
Скажем пару слов о 12-нанометровом FFN-техпроцессе TSMC. Это действительно самый продвинутый техпроцесс тайваньской компании, подходящий для производства таких больших и сложных чипов, как GV100. Единственный момент, который нужно иметь в виду — по сути, это уменьшенная версия известного техпроцесса 16 нм FinFET, уже четвертый вариант этой технологии с улучшенными характеристиками, но отличающийся не столь разительно, как цифры 12 и 16. TSMC просто решила назвать его совершенно иначе — для того, чтобы было легче конкурировать с компаниями Samsung и Globalfoundries, которые предлагают техпроцесс 14 нм. Но, по сути, эти цифры давно не говорят ничего особо конкретного о реальных качествах техпроцесса и могут «гулять» туда-сюда в зависимости от желания производителя.
В любом случае, первое решение на архитектуре Volta является самым сложным и мощным чипом в индустрии, и оно производится по одной из лучших имеющихся на рынке технологий. Интересно, что электрически и физически новый чип совместим со старым — это сделано для ускорения производства и внедрения новинки, ведь можно использовать те же системные платы, системы питания и так далее.

Кстати, для осуществления inference в задачах глубокого обучения, Nvidia выпустила специальную версию ускорителя — более компактную и потребляющую лишь 150 Вт, но обеспечивающую в 15–25 раз большую производительность в таких задачах, по сравнению с CPU от Intel семейства Skylake. В итоге, вместо 500 узлов на базе CPU можно использовать лишь 33 узла на основе GPU, хотя это и будет специализированное решение.
Пока что мы говорили лишь об аппаратной части, а ведь для современных вычислителей программная часть чуть ли не еще важнее. Оптимизированное для Volta программное обеспечение включает новую версию CUDA и ведущие фреймворки и приложения для ускорения ИИ. Программная поддержка Volta будет внедрена в следующие версии фреймворков глубокого обучения: Caffe 2, Microsoft Cognitive Toolkit, MXNet и TensorFlow, что даст возможность быстрого получения высокой производительности, которую может обеспечить Volta. Вот лишь несколько примеров сравнения V100 с P100 в некоторых задачах, использующих эти фреймворки:
Явно видно преимущество новой архитектуры в несколько раз, пусть и не 12 и даже не всегда 4–6 раз, но оно ощутимое. Также на GTC был анонсирован TensorRT для TensorFlow — оптимизированный для GPU компилятор для задач глубокого обучения, который может импортировать модели из Caffe и TensorFlow.
Если сравнивать скорость и задержки inference для нейросети ResNet-50, то Tesla V100 обеспечивает в разы лучшую скорость обработки изображений с несколько меньшей задержкой, не говоря уже о центральных процессорах или более старых GPU, сравнение с которыми новый GPU выигрывает с треском.

Представленная вычислительная архитектура получила поддержку CUDA 9 — новой версии широко известной программной платформы для вычислений на GPU. Девятая версия пакета полностью поддерживает архитектуру Volta, включая ускоритель вычислений Tesla V100, а также дает начальную поддержку специализированных тензор-ядер в API, которая обеспечивает огромный прирост при матричных операциях со смешанной точностью вычислений, распространенных в задачах глубокого обучения. Из других изменений в девятой версии отметим ускоренные библиотеки линейной алгебры, обработки изображений, FFT и других, улучшения в программной модели, поддержке унифицированной памяти, компиляторе и утилитах для разработчиков.
На данный момент, архитектура Nvidia Volta — это самая современная и продвинутая вычислительная (графическая) архитектура, которая призвана ускорить не только высокопроизводительные и графические вычисления, но и вычисления в сфере искусственного интеллекта. Благодаря объединению CUDA ядер и новых тензор-ядер, всего один сервер на базе Tesla V100 может заменить сотни центральных процессоров в специализированных высокопроизводительных вычислениях. Неудивительно, что такими решениями уже заинтересовались такие компании, как Amazon, Baidu, Facebook, Google, Microsoft, Oak Ridge National Laboratory, Tencent и многие другие.
По сравнению с Pascal, новые решения Volta должны обеспечить еще большую энергоэффективность в обычных задачах, плюс серьезно вырваться вперед там, где применимы специализированные тензор-ядра (хотя это и не только глубокое обучение, но и другие операции с матрицами, но все же, эти ядра предназначены в первую очередь именно для задач обучения и инференса). Еще подробнее о вычислительной архитектуре Volta мы расскажем вам в отдельном материале, а далее переходим к другим интересным анонсам и событиям конференции.
Другие анонсы с ключевого выступления Дженсена Хуанга
Кроме новой вычислительной архитектуры Volta и ускорителя Tesla V100 на его основе, Дженсеном также была анонсирована и новая линейка суперкомпьютерных систем с искусственным интеллектом — Nvidia DGX, базирующаяся на этом же процессоре.
И предыдущая серия устройств DGX отличалась довольно высокой производительностью, а уж новые решения на базе Tesla V100, которые используют полностью оптимизированное для задач искусственного интеллекта аппаратное и программное обеспечение, включая специализированные тензор-ядра, и вовсе дают в задачах глубокого обучения производительность примерно втрое выше, чем у предыдущего поколения DGX (по оценке самой Nvidia), что соответствует мощности примерно 800 универсальных процессоров — и все это в одной системе!

Новые системы DGX-1, в состав которых включено восемь Tesla V100 на GPU архитектуры Volta, обеспечивают заметно большее количество выполняемых операций в секунду — 960 специализированных тензор TFLOPS. То есть, вместо 8 дней расчетов на Titan X, разработчикам будет достаточно 8 часов, а это — огромная разница! Заказать новые решения можно уже сейчас и их стоимость составляет $149000.

Также Дженсен сразу же представил и DGX Station — персональное решение с четырьмя ускорителями Tesla V100, соединенными по NVLink, обеспечивающими 480 тензор TFLOPS. Это решение имеет три видеовыхода DisplayPort, блок питания мощностью 1500 Вт и водяное охлаждение. Оно, в свою очередь, будет предлагаться на рынке за $69000.

Кроме этих готовых аппаратных решений, Дженсен анонсировал облачную платформу Nvidia GPU Cloud (NGC). Эта облачная платформа предоставляет разработчикам удобный доступ к полноценному программному набору инструментов для внедрения систем искусственного интеллекта при помощи ПК, систем DGX или облака. Благодаря NGC, разработчики смогут легко и просто получить доступ к новейшим версиям оптимизированных фреймворков и самым современным ускорителям вычислений.
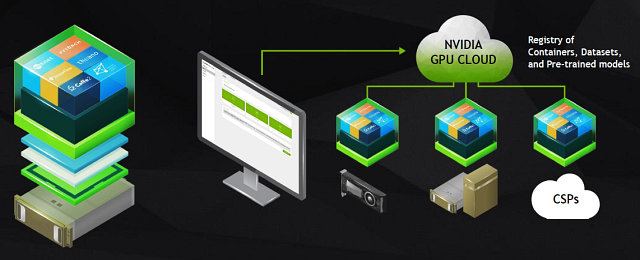
Эта система выгодна тем, что она полностью оптимизирована для решений Nvidia, все ПО в ней обновлено, протестировано и поддерживается самой компанией Nvidia. Предварительный доступ к облачной платформе будет доступен уже в июле.
И еще одним анонсом компании, связанным с системами DGX, стало объявление о партнерстве с компанией SAP. Сотрудничество двух компаний в сфере ускорения вычислений и глубокого обучения помогло компании SAP создать приложения для анализа видеоданных и отслеживания воздействия бренда, для анализа неструктурированной информации в жалобах клиентов, с целью направить их тем сотрудникам, кто способен их разрешить.
Так, проект SAP Brand Impact, использующий программные и аппаратные решения Nvidia, предназначенные для глубокого обучения, измеряет атрибуты бренда (размер и продолжительность показа логотипов компании) в видеороликах почти в реальном времени. Столь эффективный и быстрый анализ видеоконтента стал возможен благодаря использованию для этого анализа возможностей нейросетей, обученных при помощи Nvidia DGX-1 и TensorRT.
Первым делом — автопилоты
Тема автопилотируемых автомобилей развивается очень активно в последнее время, все знают и разработки Tesla, которые уже колесят по дорогам, особенно в Калифорнии, и решения других компаний, спешащих успеть на автопилотируемый поезд. Практически каждый автопроизводитель и поставщик соответствующих компонентов для автомобилей ведет разработки по автоматизации процесса управления автомобилем, а некоторые отраслевые лидеры объявили о создании альянсов в этом непростом деле: Daimler и Bosch или BMW, Intel, Mobileye и Delphi, которые займутся созданием платформы для автопилотируемых автомобилей для немецкой компании.
Высокая стоимость и сложность разработки новых технологий в сфере автопилотов заставляет участников рынка объединяться, и вполне вероятно, что количество глобальных платформ не будет слишком большим. Та же BMW планирует не просто сама использовать в своих автомобилях созданную альянсом платформу, но и лицензировать эти разработки сторонним компаниям, как и другие альянсы — те же Baidu с Volvo. Именно поэтому сотрудничество с разными автопроизводителями важно и для Nvidia, тут нужно не упустить момент.
На GTC было показано несколько таких вариантов с использованием самых современных решений Nvidia с применением искусственного интеллекта, в котором они уже собаку съели, что называется. Так, уже во время своего ключевого выступления, бессменный глава компании Дженсен Хуанг рассказал о некоторых достижениях компании по разработке автопилотов и представил новую вычислительную архитектуру, на которой будет основано будущее решение для автономных автомобилей — Drive PX Xavier.

DRIVE PX Xavier — это полноценное решение для автомобилей, использующее новую систему-на-чипе Xavier, включающую кастомный CPU с ARM64-ядрами, 512-ядерный графический процессор на основе архитектуры Volta и новые тензор-ядра, о которых мы уже писали. Они специально предназначены для задач искусственного интеллекта (в частности — глубокого обучения), и обеспечат приличный прирост производительности именно в таких применениях, выведя возможности автопилотирования на новый уровень.
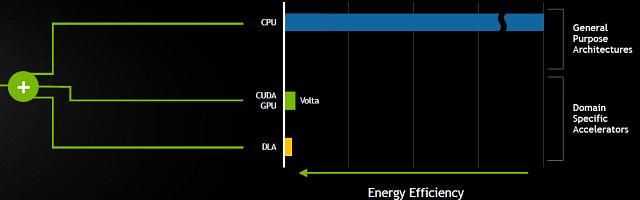
Новый DRIVE PX обеспечивает скорость вычислений до 30 млрд. операций глубокого обучения в секунду (30 TOPS DL) при потреблении до 30 Вт, но самое интересное в Xavier — Deep Learning Accelerator (DLA). Это специализированный ускоритель операций глубокого обучения, весьма энергоэффективный, но самое главное — его программная часть будет иметь открытый исходный код. Ранний доступ для автопроизводителей обещан уже в июле, а для всех остальных — в сентябре.
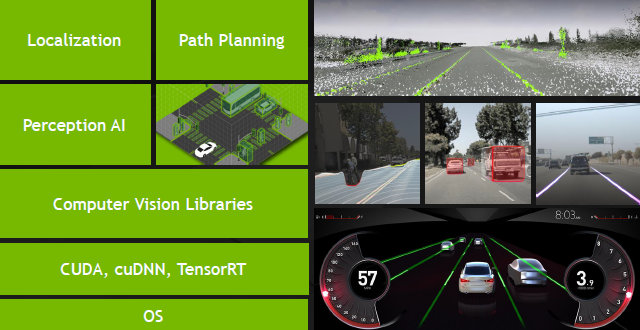
Решения Nvidia для автомобилей отличаются своей полнотой, они включают в себя и отличные аппаратные возможности, и полный программный стек, начиная от операционной системы, продолжая библиотеками: CUDA, cuDNN, TensorRT, компьютерное зрение и заканчивая готовыми решениями по построению маршрутов, распознаванию объектов и т. д. DRIVE PX умеет сканировать дорогу, отслеживать динамические и статические объекты (автомобили, знаки и другие), запоминать маршрут и помогать в пилотировании. Также поддерживается функция Guardian Angel (Ангел-Хранитель), которая будет помогать экстренно оттормаживаться в случае внезапной опасности — к примеру, большого черного джипа, завершающего проезд перекрестка на «темно-оранжевый».
Неудивительно, что столь обширные возможности не остаются без внимания со стороны автопроизводителей. Мы уже знаем о некоторых компаниях, сотрудничающих с Nvidia в этом деле, а на GTC 2017 президентом компании Nvidia Дженсеном Хуангом было объявлено о том, что компания Toyota, известная высокими стандартами безопасности на дорогах, выбрала именно DRIVE PX для использования в своих будущих автономных автомобилях. Для Nvidia это важно в том числе и потому, что этот анонс может открыть азиатский авторынок для их решений.

Toyota уже начала внедрение автомобильной платформы Nvidia PX с поддержкой искусственного интеллекта в свои системы автономного вождения, которые должны выйти на рынок в ближайшие годы. Инженеры двух компаний уже работают над созданием качественного программного обеспечения, основанного на высокопроизводительной платформе Nvidia с применением ИИ, что позволит обрабатывать и принимать во внимание огромные объемы данных, получаемые с различных датчиков, чтобы справляться с полностью автономным пилотированием при любых ситуациях на дороге.
Для решения задач подобной вычислительной сложности, в прототипах автопилотируемых автомобилей часто используют мощные компьютеры, занимающие весь багажник, а платформа Nvidia DRIVE PX, основанная на процессоре нового поколения Xavier, способна дать те же возможности, обладая низким потреблением энергии в 30 Вт и компактными размерами, легко помещаясь даже в руке. Вот пример от самой Nvidia с DRIVE PX, занимающим малую часть багажника:

Таким образом, Toyota присоединилась к другим производителям легковых и грузовых автомобилей, которые разрабатывают системы автопилотирования на основе технологий Nvidia с использованием искусственного интеллекта. Среди этих компаний есть хорошо известные имена: Tesla, Audi, Volvo и Paccar — американская компания, третий по величине производитель тяжелых грузовиков в мире, известная по маркам Peterbilt, Kenworth, DAF и другим. К слову, они также были представлены на выставке:

Этот огромный грузовик Peterbilt затащили в выставочный зал для того, чтобы показать рабочий концепт автопилотируемого грузового автомобиля, соответствующего возможностям SAE Level 4, который использует решение Nvidia DRIVE PX 2, основанное на натренированных нейросетях. При наличии около 300 миллионов грузовиков по всему миру, проезжающих более 1,2 триллиона миль в год, применение автопилотов вместо дальнобойщиков может увеличить безопасность и сократить издержки.
В холле и выставочном центре GTC вообще было представлено много различных автомобилей, так или иначе использующих решения компании. Выставка самой Nvidia включала уже известный нам проект BB8 — самопилотируемый автомобиль для тестирования различных технологий компании с использованием самообучаемых нейросетей.

В дополнение к технологии PilotNet, которая использует нейросеть для управления автомобилем, тут применяются другие технологии: LaneNet — для определения полос и другой дорожной разметки, DriveNet — для распознавания движущихся и статичных объектов (автомобилей, пешеходов и знаков) и OpenRoadNet — для определения возможного маршрута автомобиля, в зависимости от дорожных условий. Все эти технологии на основе нейросетей работают в BB8 совместно, чтобы обеспечить безопасное передвижение в любых условиях.
Также на GTC 2017 были представлены автопилотируемые автомобили от Udacity, AutonomouStuff и Audi. Последняя компания уже показывала свое решение на CES 2017, этот концепт Audi Q7 включает в себя все возможности и технологии глубокого обучения Nvidia, известные по их собственному решению BB8.

Автомобиль от AutonomouStuff также использует решение на основе DRIVE PX 2, включающее в себя этот ИИ-суперкомпьютер и технологии Nvidia DriveWorks. А компания Udacity, также показывавшая собственный автопилотируемый автомобиль, представила еще и сессии для онлайн-обучения инженеров, занимающихся автопилотами — Self-Driving Car Engineer Nanodegree. Этот курс полностью покрывает тематику автопилотов, включая возможности глубокого обучения и компьютерного зрения, а также применение различных сенсоров.
Помимо выставочных автомобилей, на GTC было представлено более 50 технических сессий, посвященных автопилотируемым автомобилям и раскрывающих темы от роли глубокого обучения в автоспорте до применения высококачественных карт в целях облегчения задач автономного вождения. Выступали на конференции и известные в индустрии специалисты, такие как Raquel Urtasun из команды Uber по разработке ИИ для автономных автомобилей, а спикеры из Argo AI/Ford и Mercedes Benz рассказали о том, как большие автопроизводители работают над системами автопилотов.
Да и сама компания Nvidia провела несколько сессий по внедрению различных облачных и других технологий в автопилотируемые транспортные средства, выделив возможности DRIVE PX 2, открытой вычислительной платформы для автомобилей и показав несколько демонстраций по применению приложений, утилит и библиотек из DriveWorks SDK.
Была на конференции и специальная лаборатория, где показывали как можно интегрировать различные типы сенсоров и использовать их в модулях DriveWorks при написании собственного кода. Эти демонстрации показывали открытость и легкость использования DriveWorks в целом, а также раскрывали возможности отдельных техник с применением вычислительно-интенсивных алгоритмов для определения объектов и планирования маршрута. В общем, автомобильной теме была посвящена очень большая часть GTC.
Также на ключевом выступлении Дженсена была показана еще одна интересная технология, которая может изменить подход к разработке автомобилей — Project Holodeck. Это фотореалистичное окружение в виртуальной реальности, предназначенное для совместной работы нескольких сотрудников. VR-среда Holodeck позволяет видеть, слышать и осязать объекты в виртуальной реальности, позволяет импортировать качественные модели высокого разрешения для совместной работы вместе с коллегами.

Для демонстрации работы технологии Nvidia воспользовалась помощью со стороны Christian von Koenigsegg, основателя известной компании Koenigsegg Automotive AB из Швеции, производящей суперкары. Он присоединился к выступлению Дженсена при помощи VR-среды Holodeck и показал, как можно было бы использовать ее в разработке полностью карбонового кузова суперкара Koenigsegg Regera.
При помощи этой технологии в реальном времени можно рассмотреть в деталях то, как будет выглядеть та или иная часть автомобиля, при этом качество изображения обеспечивается фотореалистичное. К примеру, можно подготовить несколько вариантов одной детали в виртуальном пространстве и выбирать один из них, наблюдая в VR как они будут выглядеть уже в реальности. Среда Holodeck также отличается качественными интерактивными взаимоде
Полный текст статьи читайте на iXBT
