Игровые видеокарты Nvidia GeForce RTX: первые мысли и впечатления
Вводная нашего эксперимента
Для начала — что это такое вы читаете, и о чем дальше пойдет речь. Нет, это не обзор видеокарт и нет, это даже не обзор новой графической архитектуры. А экспериментальный формат — просто рандомные мысли по теме, которые посещали автора во время многочисленных горячих обсуждений в форумах и соцсетях после анонса новой линейки видеокарт от Nvidia. Полноценный обзор обязательно появится на нашем сайте, но он будет готов ровно тогда, когда будет готов. Несколько дней еще придется подождать.
Ну, а теперь давайте рассусоливать рассуждать. Напомню, что компания Nvidia анонсировала игровые решения линейки GeForce RTX еще в августе, на игровой выставке Gamescom в Кельне. Созданы они на основе новой архитектуры Turing, представленной еще чуть ранее — на SIGGRAPH 2018. А сегодня настал тот день, когда можно публично раскрывать все известные нам подробности о новых архитектуре и видеокартах от калифорнийской компании.
Если кто-то еще не в курсе, то новых моделей GeForce RTX пока что объявлено три штуки: RTX 2070, RTX 2080 и RTX 2080 Ti, они основаны на трех графических процессорах: TU106, TU104 и TU102, соответственно. Да, Nvidia поменяла систему наименований как самих видеокарт (RTX — от ray tracing, т.е. трассировка лучей), так и видеочипов (TU — Turing), но мы сегодня не будем шутить на тему Ту-104, ведь других поводов для обсуждения у нас предостаточно.

Любопытно, что младшая модель GeForce RTX 2070 основана на TU106, а не TU104, как многие предполагали — к слову, это единственная видеокарта новой линейки, имеющая полноценный чип без урезания по количеству исполнительных блоков. Она же и выйдет позже двух других видеокарт, так как TU106 подготовили к производству несколько позже старших чипов. Мы не будем сегодня подробно останавливаться на количественных характеристиках, оставив это полноценному обзору новинок, но рассмотрим разницу между чипами по сложности.
Применяемая модификация TU102 по количеству блоков ровно вдвое больше, чем TU106, средний чип TU104 содержит четыре блока TPC на кластер GPC, а TU102 и TU106 имеют по 6 блоков TPC на каждый GPC. Но сейчас для нас важнее сложность и размеры графических процессоров (почему — поймете далее, когда речь пойдет о ценах). TU106, лежащий в основе GeForce RTX 2070, имеет 10,6 млрд. транзисторов и площадь 445 мм2, что более чем на сотню миллиметров больше, чем у GP104 на архитектуре Pascal (7,2 млрд. и 314 мм2). То же самое касается и других решений, модель GeForce RTX 2080 Ti основана на слегка урезанной версии TU102, имеющей площадь 754 мм2 и 18,6 млрд. транзисторов (против 610 мм2 и 15,3 млрд. у GP100), GeForce RTX 2080 базируется на урезанном TU104 с площадью 545 мм2 и 13,6 млрд.транзисторов (сравните с 471 мм2 и 12 млрд. у GP102).
То есть, по сложности чипов Nvidia как бы сдвинула линейку на шаг: TU102 скорее соответствует гипотетически предполагаемому чипу с индексом 100, TU104 больше похож на «TU102» и TU106 — на «TU104». Это если смотреть по семейству Pascal, которое, к слову, производилось по 16 нм техпроцессу на TSMC, а все новые графические процессоры — на… гм… более новом 12 нм у тех же тайваньцев.
Но по размерам чипов этого изменения не очень хорошо видно потому, что техпроцессы очень близки по характеристикам, несмотря на свои вроде бы разные наименования — информация о них на сайте TSMC даже размещена на одной странице. Так что большого преимущества по себестоимости производства быть не должно, но площадь всех GPU то заметно возросла… Запомните эту информацию и проистекающий из нее логический вывод — они еще пригодятся нам в конце материала.
Аппаратная трассировка лучей — благо или блажь?
Так откуда же взялись все эти «лишние» транзисторы в новых GPU, ведь количество основных исполнительных блоков (CUDA-ядра) выросло не так уж сильно? Как стало известно еще из анонса архитектуры Turing и профессиональных решений линейки Quadro RTX на SIGGRAPH, новые графические процессоры от Nvidia, кроме ранее известных блоков, впервые включают также и специализированные RT-ядра, предназначенные для аппаратного ускорения трассировки лучей. Переоценить их появление в видеокартах невозможно, это большой шаг вперед для качественной графики в реальном времени. Мы уже написали для вас подробнейшую статью о трассировке лучей и ее преимуществах, которые проявятся уже в ближайшие годы. Если вас интересует эта тема, то настоятельно советуем ознакомиться.
Если совсем вкратце, то трассировка лучей обеспечивает значительно более высокое качество картинки, по сравнению с растеризацией, даже при том, что ее применение пока ограничено возможностями аппаратного обеспечения. Но анонс технологии Nvidia RTX и соответствующих GPU дал разработчикам принципиальную возможность — начать исследования алгоритмов, использующих трассировку лучей, что стало самым значительным изменением в графике реального времени за долгие годы. Это перевернет все представление о графике, но не сразу, а постепенно. Первые примеры использования трассировки будут гибридными (сочетание трассировки лучей и растеризации) и ограниченными по количеству и качеству эффектов, но это — единственно правильный шаг к полной трассировке лучей, которая станет доступной уже через несколько лет.
Благодаря первенцам семейства GeForce RTX, уже сейчас можно использовать трассировку для части эффектов — качественных мягких теней (будет реализовано в свежей игре Shadow of the Tomb Raider), глобального освещения (ожидается в Metro Exodus и Enlisted), реалистичных отражений (будет в Battlefield V), а также сразу нескольких эффектов одновременно (было показано на примерах Assetto Corsa Competizione, Atomic Heart и Control). При этом для GPU, не имеющих аппаратных RT-ядер в своем составе, можно использовать привычные методы растеризации. А RT-ядра в составе новых чипов используются исключительно для расчета пересечения лучей с треугольниками и ограничивающими объемами (BVH), важнейшими для ускорения процесса трассировки (подробности читайте в полном обзоре), а вычисления по закраске пикселей все так же делаются в шейдерах, исполняемых на привычных мультипроцессорах.
Что касается производительности новых GPU при трассировке, то публике назвали цифру в 10 гигалучей в секунду. Много это или мало? Оценивать производительность RT-ядер в количестве обсчитываемых лучей в секунду не совсем корректно, так как скорость сильно зависит от сложности сцены и когерентности лучей. И она может отличаться в десяток раз и более. В частности, слабо когерентные лучи при обсчете отражений и преломлений требуют большего времени для расчета, по сравнению с когерентными основными лучами. Так что показатели эти чисто теоретические, и сравнивать разные решения нужно в реальных сценах при одинаковых условиях. Но уже известно, что новые GPU до 10 раз быстрее (это в теории, а в реальности — скорее до 4–6 раз) в задачах трассировки, по сравнению с предыдущими решениями аналогичного уровня.
О потенциальных возможностях трассировки лучей не стоит судить по ранним демонстрациям, в которых намеренно выпускают на первый план именно эти эффекты. Картинка с трассировкой лучей всегда реалистичнее в целом, но на данном этапе массы еще готовы мириться с артефактами при расчете отражений и глобального затенения в экранном пространстве, а также другими хаками растеризации. Но с трассировкой можно получить потрясающие результаты — посмотрите на скриншот из новой демки от компании Nvidia с трассировкой лучей, применяемой для полного просчета освещения, в том числе глобального, мягких теней (правда, лишь от одного источника света — солнца, зато его можно перемещать) и реалистичных отражений, не бросающихся в глаза, как это мы видели в других демонстрациях.

Сцена в демке (нам обещали позднее выпустить ее публично, чтобы все могли посмотреть вживую) наполнена объектами сложной формы из разных материалов: барная стойка, стулья, светильники, бутылки, натертый до блеска паркетный пол и др. Для сглаживания используется продвинутый алгоритм с применением искусственного интеллекта — DLSS, и сцена при всем этом отрисовывается почти в реальном времени всего лишь на паре видеокарт GeForce RTX 2080 Ti! Да, пока что в играх такого не увидишь, но все еще впереди. Немного больше информации об этой демке — под спойлером в последней главе материала.
Недоверчивый игрок сразу же прицепится к паре топовых GPU: «Ага, я всегда знал, что трассировка лучей будет сильно просаживать производительность!» Нет, далеко не всегда для трассировки нужны две топовые видеокарты стоимостью по тыще долларов каждая, в игре Enlisted от Gaijin Entertainment применяется столь хитрый метод расчета глобального освещения в реальном времени с применением аппаратной трассировки от Nvidia, что включение GI не приносит потерь производительности вообще!
 GI выключен — 117,9 FPS
GI выключен — 117,9 FPS GI включен — 118,3 FPS
GI включен — 118,3 FPSЕсли вы обратите внимание на счетчик FPS в углу экрана, то легко заметите, что включение GI не снизило частоту кадров вовсе, хотя значительно увеличило реалистичность освещения (картинка без GI плоская и нереалистичная). Это стало возможно на GeForce RTX благодаря хитрому алгоритму от Gaijin и специализированным RT-ядрам, выполняющим всю работу по ускорению специальных структур (BVH — Bounding Volume Hierarchy) и поиску пересечений лучей с треугольниками. Так как большая часть работы выполняется именно на выделенных RT-ядрах, а не CUDA-ядрах, то и снижения производительности это практически не приносит в данном конкретном случае.
Пессимисты скажут, что ровно так же можно предварительно рассчитать GI и «запечь» информацию об освещении в специальные лайтмапы, но для больших локаций с динамическим изменением погодных условий и времени суток сделать это просто физически невозможно. Так что аппаратно ускоренная трассировка лучей мало того, что приносит повышение качества, она облегчит труд дизайнеров, да еще при всем этом может быть «дешевой» или даже «бесплатной» в некоторых случаях. Конечно, так будет не всегда, качественные тени и преломления сложнее рассчитать, но специализированные RT-ядра сильно помогают, по сравнению с трассировкой лучей чисто при помощи вычислительных шейдеров.
Вообще, ознакомившись с множеством мнений простых игроков после анонса технологии RTX и просмотра демонстраций в играх, можно сделать вывод о том, что далеко не все поняли, что принципиально нового дает трассировка лучей. Многие говорят что-то типа: «А что, тени в играх сейчас и так реалистичные и отражения есть — те, которые показала Nvidia с использованием трассировки, ничем не лучше. В том и дело, что лучше! Хотя растеризация при помощи многочисленных хитрых хаков и трюков к нашим дням действительно добилась отличных результатов, когда во многих случаях картинка выглядит достаточно реалистично для большинства людей, в некоторых случаях отрисовать корректные отражения и тени при растеризации невозможно принципиально.
Самый явный пример — отражения объектов, которые находятся вне сцены — типичными методами отрисовки отражений без трассировки лучей полностью реалистично отрисовать их невозможно. Или не получится сделать реалистичные мягкие тени и корректно рассчитать освещение от больших по размеру источников света (площадные источники света — area lights). Для этого пользуются разными хитростями, вроде расставления вручную большого количества точечных источников света и фейкового размытия границ теней, но это — не универсальный подход, он работает только в определенных условиях и требует дополнительной работы и внимания от разработчиков.
Для качественного же скачка в возможностях и улучшении качества картинки переход к гибридному рендерингу и трассировке лучей просто необходим. Точно такой же путь в свое время проходила киноиндустрия, в которой в конце прошлого века применялся гибридный рендеринг с одновременной растеризацией и трассировкой. А еще через 10 лет все в кино постепенно перешли к полной трассировке лучей. То же самое будет и в играх (только быстрее), этот шаг с относительно медленной трассировкой и гибридным рендерингом невозможно пропустить, так как он дает возможность подготовиться к трассировке всего и вся.
Тем более, что во многих хаках растеризации уже и так используются схожие с трассировкой методы (к примеру, можно взять самые продвинутые методы имитации глобального затенения и освещения типа VXAO), поэтому более активное использование трассировки в играх — лишь дело времени. Тем более, что она позволяет упростить работу художников по подготовке контента, избавляя от необходимости расставления фейковых источников света для имитации глобального освещения и от некорректных отражений, которые с трассировкой будут выглядеть естественно.
В киноиндустрии переход к полной трассировке лучей привел к увеличению времени работы художников непосредственно над контентом (моделированием, текстурированием, анимацией), а не над тем, как сделать неидеальные методы растеризации реалистичными. К примеру, сейчас очень много времени уходит на расставление источников света, предварительный расчет освещения и «запекание» его в статические карты освещения. При полной трассировке это все будет не нужно, и даже просто подготовка карт освещения на GPU вместо CPU даст ускорение этого процесса. То есть, переход на трассировку дает не просто улучшение картинки, а скачок и в качестве самого контента.
Кто-то скажет, что в переходный гибридный период в играх все будет блестящее и отражающее и это нереалистично. А как будто когда-то было иначе! Когда только началось внедрение отражений в экранном пространстве (SSR — screen space reflections) в играх, то каждая первая автогонка (вспомните серию Need for Speed, начиная с Underground) считала своим долгом показывать чуть ли не исключительно мокрые ночные дороги. Вероятно, отражающих объектов с внедрением трассировки тоже станет больше, но в основном по той причине, что ранее рендеринг реалистичных отражений был или сложен или вовсе невозможен в определенных случаях. Плюс — вполне естественно, что в первых демонстрациях технологии нам показывают в основном те поверхности, на которых эффект хорошо виден, но в играх будущего вовсе не обязательно будет так.
На первых стадиях внедрения трассировки есть и явная проблема недостатка ее производительности, но аппетиты разработчиков постоянно растут, как только они распробуют новую технологию. К примеру, создатели игры Metro Exodus изначально планировали добавить в игру лишь расчет Ambient Occlusion, добавляющий теней в основном в углах между поверхностями, но затем они решили внедрить уже полноценный расчет глобального освещения GI. Результат получился довольно неплохим уже сейчас:
Поначалу визуальная разница между максимально проработанными алгоритмами растеризации и начинающей свой путь аппаратной трассировкой лучей нередко действительно будет не слишком большой, и в этом есть определенная опасность для Nvidia. Пользователи могут сказать, что они не готовы заплатить за такую разницу, и с потребительской точки зрения понять их можно.
С другой стороны, переходного периода не избежать, и кто, как не лидер индустрии, способен потянуть его, заодно уговорив и своих партнеров? Тем более правильно делать это при нынешнем положении дел, когда единственный конкурент решил сделать большую (нет, не так — ОГРОМНУЮ) паузу по разработке своих решений.
Зачем вообще игровой видеокарте какой-то интеллект?
С трассировкой лучей более-менее разобрались, и она, безусловно, полезна для графики, пусть и дается сначала достаточно большой ценой. Но для чего в игровых графических процессорах оставили тензорные ядра, которые впервые появились в архитектуре Volta и в дорогущей видеокарте для энтузиастов — Titan V. Эти тензорные ядра ускоряют задачи с применением искусственного интеллекта (так называемое глубокое обучение), и зачем все это игрокам, по мнению некоторых вынужденным платить за то, что они не используют.
Главное, для чего нужны тензорные ядра в GeForce RTX — для помощи все той же трассировке лучей. Поясню — в начальной стадии применения аппаратной трассировки, производительности хватает только для сравнительно малого количества рассчитываемых лучей на каждый пиксель, а малое количество рассчитываемых сэмплов дает весьма «шумную» картинку, которую приходится дополнительно обрабатывать (подробности читайте в нашей статье о трассировке). В первых проектах это будет от 1 до 4 лучей на пиксель, в зависимости от задачи и алгоритма. К примеру, в Metro Exodus для расчета глобального освещения используется по три луча на пиксель с расчетом одного отражения, и без дополнительной фильтрации результат к применению не слишком пригоден.
Для решения этой проблемы можно использовать различные фильтры шумопонижения, улучшающие результат без необходимости увеличения количества выборок (лучей). Шумодавы очень эффективно устраняют неидеальность результата трассировки с малым количеством выборок и результат их работы зачастую не отличить от изображения, полученного с помощью в разы большего количества выборок.

На данный момент в Nvidia используют различные шумодавы, в том числе и основанные на работе нейросетей. Которые как раз могут быть ускорены на тензорных ядрах. В будущем такие методы с применением ИИ будут улучшаться и способны полностью заменить все остальные. Главное, что нужно понять — на текущем этапе применениям трассировки лучей без фильтров шумоподавления не обойтись, во многом именно поэтому тензорные ядра обязательно нужны в помощь RT-ядрам.
Но далеко не только для этой задачи можно использовать искусственный интеллект (ИИ) и тензорные ядра, в частности. Nvidia уже показывала новый метод как бы сглаживания — DLSS (Deep Learning Super Sampling). «Как бы» — потому, что это не совсем привычное сглаживание, а технология, использующая искусственный интеллект для улучшения качества отрисовки аналогично сглаживанию.
Для успешной работы DLSS, нейросеть «тренируют» в оффлайне на тысячах изображений, полученных с применением суперсэмплинга с большим количеством выборок (именно поэтому технологию назвали Super Sampling, хотя это не суперсэмплинг). Затем уже в реальном времени на тензорных ядрах видеокарты исполняются вычисления (инференс), которые «дорисовывают» изображение на основе ранее обученной нейросети.

То есть, нейросеть на примере тысяч хорошо сглаженных изображений учат »додумывать» пиксели, делая из грубой картинки сглаженную, и она успешно делает это затем уже для любого изображения из игры. И такой метод работает значительно быстрее любого традиционного метода с аналогичным качеством. В результате, игрок получает четкие изображения вдвое быстрее, чем GPU предыдущего поколения с использованием традиционных методов сглаживания типа TAA. Да еще и с лучшим качеством, если присмотреться к приведенным выше примерам.
К сожалению, у DLSS есть один важный недостаток — для внедрения этой технологии нужна поддержка со стороны разработчиков, так как для работы алгоритма требуются данные буфера с векторами движения. Но таких проектов уже довольно много — 25 штук на сегодняшний день, включая такие известные игры, как Final Fantasy XV, Hitman 2, PlayerUnknown«s Battlegrounds, Shadow of the Tomb Raider, Hellblade: Senua’s Sacrifice и другие:

Но DLSS — еще далеко не все, для чего можно применять нейросети. Все зависит от разработчика, он может использовать мощь тензорных ядер для более «умного» игрового ИИ, для улучшенной анимации (такие методы уже есть), да много чего еще можно придумать. Даже, казалось бы, совершенно дикого — к примеру, можно в реальном времени улучшать текстуры и материалы в старых играх! Ну, а почему бы и нет? Натренировать нейросеть на основе парных изображений старых и улучшенных текстур и пусть она уже дальше сама работает. Это я уж не говорю о банальном увеличении разрешения (upscale), с которым ИИ уже идеально справляется.
Главное, что возможности применения нейросетей фактически безграничны, мы просто еще даже не догадываемся о том, что еще можно с их помощью сделать. Просто раньше производительности было слишком мало для того, чтобы применять нейросети массово и активно, а теперь, с появлением тензорных ядер в простых игровых видеокартах (пусть пока только дорогих — мы еще вернемся к этому вопросу) и возможностью их использования при помощи специального API и фреймворка Nvidia NGX (Neural Graphics Framework) это становится всего лишь делом времени.
ОК, новые фичи хороши, а что со старыми играми?
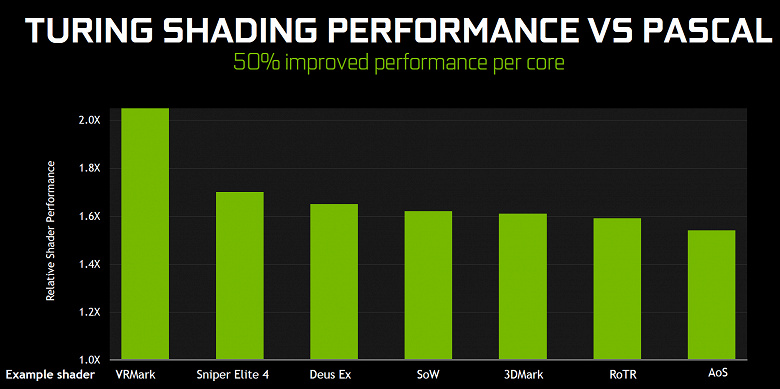
Одним из важнейших вопросов, тревожащих игроков по всему миру, стал вопрос производительности в уже существующих проектах. Да, новые фичи дадут скорость и качество, но почему Nvidia на презентации в Кельне ничего не сказала о скорости в нынешних играх по сравнению с линейкой Pascal? Наверняка там не все так уж хорошо, вот поэтому и скрывают! Действительно, отсутствие каких-либо данных о скорости рендеринга в уже вышедших играх со стороны компании было явной оплошностью, которую они затем поспешили исправить, выпустив слайды о приросте скорости до 50% в известных играх по сравнению с аналогичными моделями из линейки GeForce GTX.
Общественность вроде бы немного успокоилась, но остался нераскрытым главный вопрос — как удалось этого добиться? Ведь количество CUDA-ядер и прочих привычных блоков (TMU, ROP и т.д.) возросло не слишком сильно, по сравнению с Pascal, да и тактовая частота выросла не слишком сильно. Действительно, чисто по этим характеристикам приросту в 50% взяться неоткуда. Но, оказывается, что Nvidia вовсе не сидела, сложа руки, внеся некоторые изменения и в уже известные нам блоки.
К примеру, в архитектуре Turing стало возможным одновременное выполнение целочисленных (INT32) команд вместе с операциями с плавающей запятой (FP32). Некоторые пишут, что в CUDA-ядрах «появились» блоки INT32, но это не совсем верно — они есть там уже давно, просто раньше одновременное исполнение целочисленных и FP-инструкций было невозможным.
Теперь же в ядра были внесены изменения аналогично Volta, которые позволяют исполнять INT32- и FP32-операции параллельно и независимо. По данным Nvidia, типичные игровые шейдеры, помимо операций с плавающей запятой, в среднем используют при исполнении и около 36% дополнительных целочисленных операций (адресация, специальные функции и т.п.), так что уже одно это нововведение способно серьезно повысить производительность во всех играх, а не только с трассировкой лучей и DLSS.
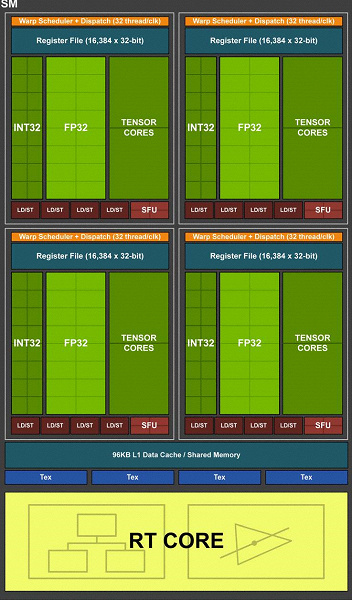
Можно удивиться разве что соотношению количества блоков INT32 и FP32, но задачи процессоров Nvidia не ограничиваются игровыми шейдерами, а в других применениях доля целочисленных операций вполне может быть и выше. Кроме этого, INT32-блоки наверняка значительно проще FP32, так что «лишнее» их количество вряд ли сильно повлияло на общую сложность GPU.
Это не единственное улучшение основных вычислительных ядер. В новых SM также серьезно изменили архитектуру кэширования, объединив кэш первого уровня и текстурный кэш (у Pascal они были раздельные). В итоге, вдвое выросла пропускная способность L1-кэша, снизились задержки доступа к нему вместе с увеличением емкости кэша, а каждый кластер TPC в чипах архитектуры Turing теперь имеет вдвое больше кэш-памяти второго уровня. Оба этих значительных архитектурных изменения привели к примерно 50% улучшения производительности шейдерных процессоров в играх (таких как Sniper Elite 4, Deus Ex, Rise of the Tomb Raider и других).
Кроме этого, также были улучшены технологии сжатия информации без потерь, экономящие видеопамять и ее пропускную способность. Архитектура Turing включает новые техники сжатия, по данным Nvidia до 50% более эффективные, по сравнению с алгоритмами в семействе чипов Pascal. Вместе с применением нового типа памяти GDDR6 это дает приличный прирост эффективной ПСП, так что новые решения точно не будут ограничены возможностями памяти.
Добавим немного информации и о тех изменениях, которые могут сказаться как в старых, так и в новых играх. К примеру, по некоторым фичам (feature level) из Direct3D 12, чипы Pascal отставали от решений AMD и даже интегрированных GPU от Intel! В частности это касается таких возможностей, как Constant Buffer Views, Unordered Access Views и Resource Heap (если вы не знаете, что это такое — просто поверьте, что эти возможности немного облегчают работу программистам, упрощая доступ к различным ресурсам). Так вот, по возможностям Direct3D feature level новые GPU уже не отстают от конкурентов.
Кроме этого, было улучшено еще одно, не так давно еще больное место чипов Nvidia — асинхронное исполнение шейдеров, высокой эффективностью которого могут похвалиться решения AMD. Оно уже неплохо работало и в последних чипах Pascal, но в Turing этот самый async shading был улучшен дополнительно, по словам Джоны Албена, главного по разработке графических чипов в компании. К сожалению, никаких подробностей он не выдал, хотя рассказал также и о том, что новые CUDA-ядра способны исполнять операции с плавающей запятой сниженной точности (FP16) с двойным темпом, в дополнение к озвученной ранее способности Turing исполнять такие операции и на тензорных ядрах (ура, еще одно применение «бесполезным» тензорам!).
И очень кратко расскажем о том, какие еще изменения в Turing нацелены на будущее. Nvidia предлагает метод, позволяющий значительно снизить зависимость от мощности CPU и одновременно с этим во много раз увеличить количество объектов в сцене. Бич CPU overhead давно уже преследует ПК-игры, и хотя частично он решался в DirectX 11 (в меньшей степени) и DirectX 12 (в большей), радикально ничего особо не улучшилось — каждый объект все так же требует нескольких вызовов функций отрисовки (draw calls), каждый из которых требует обработки на CPU, что не дает GPU показать все свои возможности.
Главный конкурент Nvidia еще при анонсе семейства Vega предложил возможное решение проблем — primitive shaders, но дело не пошло дальше заявлений. В Turing предлагается аналогичное решение под названием Mesh Shading — это как бы новая шейдерная модель, которая ответственна сразу за всю работу над геометрией, вершинами, тесселяцией и т.д. При Mesh Shading становятся ненужными вершинные шейдеры и тесселяция, весь привычный вершинный конвейер заменяется аналогом вычислительных шейдеров для геометрии, которыми можно делать все, что захочется: трансформировать вершины, добавлять их или убирать, используя вершинные буферы как угодно или создавать геометрию прямо на GPU.
Увы, столь радикальный метод требует поддержки от API, вероятно поэтому у конкурента дело дальше заявлений не пошло. Предполагаем, что в Microsoft уже работают над добавлением этой возможности, раз она поддерживается уже двумя основными производителями GPU (Intel, ау!), и в какой-то из будущих версий DirectX она появится. Пока что ее вроде бы можно использовать при помощи специализированного NVAPI, который в т.ч. и создан для внедрения возможностей новых GPU, еще не поддерживаемых в графических API. Но так как это не универсальный метод, то широкой поддержки Mesh Shading до обновления популярных графических API можно не ждать, увы.
Еще одна интереснейшая возможность Turing — Variable Rate Shading (VRS), шейдинг с переменным количеством сэмплов. Вкратце, эта возможность дает разработчику контроль над тем, сколько выборок использовать в случае каждого из тайлов буфера размером 4×4 пикселя. То есть, для каждого тайла изображения из 16 пикселей можно выбрать свое качество на этапе закраски пикселя. Важно, что это не касается геометрии, так как буфер глубины остается в полном разрешении.
Зачем это все нужно? В кадре всегда есть участки, на которых легко можно понизить количество сэмплов закраски практически без потерь в качестве — к примеру, это части изображения, впоследствии замыленные постэффектами типа Motion Blur или Depth of Field. И разработчик может задавать качество шейдинга для разных участков кадра, достаточное, по его мнению, что может увеличить производительность. Сейчас для подобных задач иногда применяют так называемый checkerboard rendering, но он не универсален и ухудшает качество закраски для всего кадра, а с VRS можно делать все это максимально тонко.

Можно упрощать шейдинг тайлов в несколько раз, чуть ли не с одной выборкой для блока в 4×4 пикселя (такая возможность не показана на картинке, но она есть, как нам известно), а буфер глубины остается в полном разрешении, и даже при таком низком качестве шейдинга, границы полигонов будут сохраняться в полном качестве, а не один на 16. К примеру, на картинке выше самые смазанные участки дороги рендерятся с экономией ресурсов вчетверо, остальные — вдвое, и лишь самые важные отрисовываются с максимальным качеством закраски.
А кроме оптимизации производительности, эта технология дает и некоторые неочевидные возможности, вроде почти бесплатного сглаживания для геометрии. Для этого нужно отрисовывать кадр в буфер вчетверо большего разрешения (делая как бы 2×2 суперсэмплинг), но включить shading rate на 2×2 по всей сцене, что убирает стоимость вчетверо большей работы по закраске, но оставляет сглаживание геометрии в полном разрешении. Таким образом получится, что шейдеры исполняются лишь один раз на пиксель, но сглаживание будет с качеством 4х MSAA практически «бесплатно», так как основная работа GPU заключается именно в шейдинге. И это лишь один из вариантов использования VRS, программисты наверняка придумают и другие.
Но $1000! Наживается ли Nvidia на игроках или двигает индустрию?
Наконец-то мы подошли, пожалуй, к самому спорному моменту для GeForce RTX. Да, новые возможности Turing и GeForce RTX в частности выглядят весьма впечатляюще, это невозможно не признать. В новых GPU были улучшены как традиционные блоки, так и появились совершенно новые, с новыми же возможностями. Казалось бы — беги скорее в магазин делать предзаказ! Но нет, очень многих потенциальных покупателей сильно смутили цены новых решений Nvidia, которые оказались выше предполагаемых ими.
И это так, цены действительно совсем немаленькие, особенно в условиях нашей страны. Но не стоит забывать и об особенностях нашего… национального ценообразования, обвиняя Nvidia. Все же у нас любят сравнивать цены без налогов в США (а они в и штатах могут достигать 10–15%) и российские цены с дополнительно заложенным НДС, логистическими расходами и немалыми рисками, связанными с нестабильностью национальной валюты, что тоже закладывается в цену. Все перечисленное выше сильно сблизит американскую цену без налогов с нашей розничной. Тем более не нужно сравнивать цены референсных образцов и заявленные цены на карты от партнеров — подождем практики, может разница между ценами у нас и «там» на деле будет не такой большой. Ну, а если будет даже с учетом специфики рынка, то с радостью присоединимся к вашей ругани.
А кто вообще сейчас может себе позволить отдать 96 тыс. руб. за топовую GeForce RTX 2080 Ti или даже 64 и 48 тыс. руб. за менее мощные варианты? Это ведь всего лишь видеокарта со стоимостью в целый ПК. Но подождите, окружающая нас объективная реальность такова, что представленный на днях топовый смартфон очень популярной марки (без особых улучшений по сравнению с предыдущим поколением, к слову) и то дороже стоит! Почему тогда видеокарта не может?
Новинки от Nvidia стоят… нет, не »дорого», а »дороже предыдущих решений». Разница есть и нужно понимать, что это не цена сама по себе высокая, а она просто выше цен на предыдущие поколения GPU. Чему есть в том числе и вполне объективные причины:
- Высокая себестоимость разработки — проектирование столь продвинутых графических архитектур на протяжении нескольких лет нужно как-то отбивать. А Nvidia потратила на нее долгие годы работы и миллиарды вовсе не рублей.
- Дороговизна в производстве больших GPU при необходимости обеспечения прибыльности. Чипы в конечном счете получились весьма непростые и большие по площади (вспоминаем цифры из первой главы), что также ограничивает возможности снижения цен на готовую продукцию компании. Тем более, что технологический процесс от TSMC используется довольно новый, хоть и родственный уже освоенному 16 нм.
- Фактическое отсутствие конкуренции в верхнем ценовом сегменте — от компании AMD не предвидится ничего схожего по производительности и возможностям в ближайшее время (похоже, что долгие месяцы), а ожидаемого хода Intel придется ждать еще минимум пару лет, да и то не факт, что все у них получится в срок и хорошо.
Соответственно, при капитализме в Nvidia имеют право назначать любые цены и конкретно с их точки зренияПолный текст статьи читайте на iXBT
