Эксперимент по настройке Linux для блокирования 10 млн пакетов в секунду
Марек Майковски (Marek Majkowski), разработчик ядра Linux, работающий в компании CloudFlare, опубликовал результаты оценки производительности различных решений на базе ядра Linux для отбрасывания огромного числа пакетов, поступающих в ходе DDoS-атаки. Наиболее высокопроизводительный метод позволил отбрасывать потоки запросов, поступающие с интенсивностью 10 млн пакетов в секунду.
Наибольшей производительности удалось добиться при использовании подсистемы eBPF, представляющей встроенный в ядро Linux интерпретатор байткода, позволяющий создавать высокопроизводительные обработчики входящих/исходящих пакетов с принятием решений об их перенаправлении или отбрасывании. Благодаря применению JIT-компиляции, байткод eBPF на лету транслируется в машинные инструкции и выполняется с производительностью нативного кода. Для блокировки использовался вызов XDP_DROP, предоставляемый подсистемой XDP (eXpress Data Path), позволяющей запускать BPF-программы на уровне сетевого драйвера, с возможностью прямого доступа к DMA-буферу пакетов и на стадии до выделения буфера skbuff сетевым стеком.
Блокировка осуществлялась при помощи загруженного в ядро простого BPF-приложения (около 50 строк кода), написанного на подмножестве языка C и скомпилированного при помощи Clang. Для загрузки скомпилированного модуля eBPF применяется недавно появившаяся в iproute2 команда «xdp obj» («ip link set dev ext0 xdp obj xdp-drop-ebpf.o»), позволяющая обойтись без написания специализированного BPF-загрузчика. Для просмотра статистики применялась команда «ethtool -S». Логика блокировки была зашита непосредственно в BPF-приложение, например, блокируемые IP-подсеть, порт назначения и тип протокола были определены через условные операторы (системы типа bpfilter и Cilium умеют генерировать BPF-программы на основе высокоуровневых правил фильтрации):
if (h_proto == htons(ETH_P_IP)) { if (iph->protocol == IPPROTO_UDP && (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24 && udph->dest == htons(1234)) { return XDP_DROP; } } Другие опробованные методы блокировки:
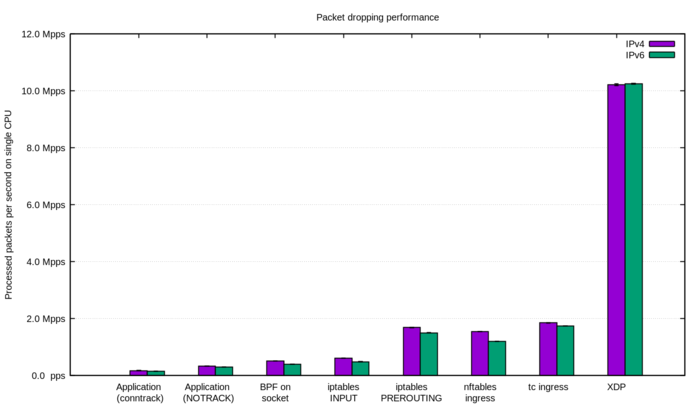
- Отбрасывание пакетов путём создания приложения-заглушки, принимающего запросы на целевом сетевом порту, но не выполняющего каких-либо действий («s.bind ((»0.0.0.0», 1234))» и бесконечный цикл с «s.recvmmsg ()» — использование recvmmsg вместо recvmsg важно с точки зрения снижения числа системных вызовов, в свете накладных расходов при включении в ядре защиты от уязвимости Meltdown). Производительность такого решения составила всего 174 тысячи пакетов в секунду, при этом узким местом было не переключение контекста и само приложение (нагрузка была 27% sys и 2% userspace), а полная утилизация второго ядра CPU при обработке SOFTIRQ.
Большие накладные расходы также возникали из-за ведения ядром таблиц отслеживания соединений (conntrack), отключение которых при помощи правила «iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK» позволило поднять производительность почти в два раза, до 333 тысяч пакетов в секунду. Дополнительное применение режима SO_BUSY_POLL подняло скорость обработки до 470 тысяч пакетов в секунду.
- Использование BPF с привязкой к сетевому сокету и запуском на уровне ядра (как с обычным BPF, так и с eBPF). Специально написанное BPF-приложение bpf-drop, подключающее обработчик для фильтрации пакетов к сокету через вызов «setsockopt (SO_ATTACH_FILTER)», продемонстрировало производительность всего 512 тысяч пакетов в секунду (в 20 раз меньше, чем BPF-обработчик на базе XDP). Причиной низкой производительности, как и в первом рассмотренном методе, стали большие накладные расходы при обработке SOFTIRQ.
- Применение операции DROP в iptables в цепочке INPUT (после обработки маршрутизации). При использовании следующих правил
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
удалось добиться производительности 608 тысяч пакетов в секунду.
- Использование iptables DROP на стадии до обработки маршрутизации (PREROUTING). Замена в правиле »-I INPUT» на »-I PREROUTING -t raw» подняло производительность почти в три раза до 1.688 млн пакетов в секунду.
- Применение операции DROP в nftables на стадии до выполнения стадии отслеживания соединений (для обхода CONNTRACK применяется «hook ingress»):
nft add table netdev filter nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; } nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter dropПроизводительность предложенного решения составила 1.53 млн пакетов в секунду, что немного отстаёт от iptables DROP с PREROUTING.
- Применение операции DROP в ingress-обработчике tc позволило добиться производительности в 1.8 млн пакетов в секунду.
tc qdisc add dev vlan100 ingress tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
Полный текст статьи читайте на OpenNet
