Чипы для искусственного интеллекта: кто наступает на пятки NVIDIA
Мы находимся в точке перелома в вычислительной технике, которая бывает раз в несколько поколений. Традиционные способы проектирования и создания вычислительной инфраструктуры уже не соответствуют экспоненциально растущим требованиям таких рабочих нагрузок, как генеративный ИИ и большие языковые модели. За последние 5 лет количество параметров в LLM увеличивалось в 10 раз в год. В результате заказчикам требуется инфраструктура, оптимизированная для ИИ, экономически эффективная и масштабируемая.
Спрос на специализированные чипы искусственного интеллекта резко возрос после запуска ChatGPT в прошлом году. Ускорители ИИ необходимы для обучения и работы новейших технологий генеративного ИИ. Nvidia — один из немногих производителей на этом рынке. Ряд крупных технологических игроков делают попытки разработать собственные процессоры и взять под контроль этот сегмент. В статье разбираемся, какие чипы в разработке сейчас и на чем будет «крутиться» искусственный интеллект в ближайшем будущем.
 Изображение сгенерировано в Midjourney
Изображение сгенерировано в Midjourney
Планы NVIDIA на будущее
На рынке графических процессоров для искусственного интеллекта доминирует Nvidia. Компания контролирует более 80% мирового рынка чипов, которые наиболее подходят для работы ИИ и приложений на его основе.
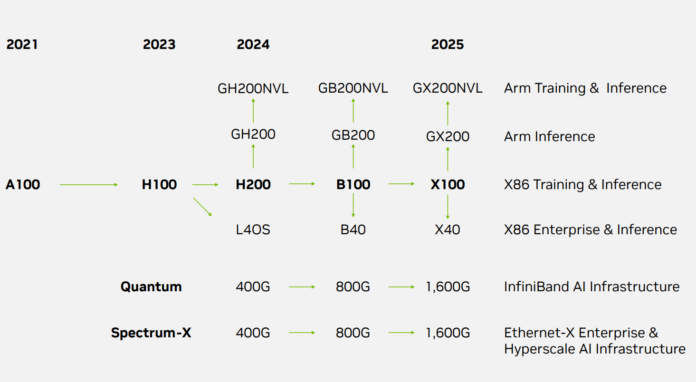
Недавно NVIDIA представила свою дорожную карту. Компания активно продвигается в области центров обработки данных. Ее представители рассчитывают, что этот сегмент будет как минимум в 3 раза больше игрового и в 4,5 раза больше, если учесть корпоративный ИИ и облачные предложения DGX Cloud. Дорожная карта включает появление таких компонентов, как H200, B100, X100, B40, X40, GB200, GX200, GB200NVL, GX200NVL и других. Существует даже перспектива перехода на 1,6T Ethernet в ближайшие два года.
 Дорожная карта NVIDIA
Дорожная карта NVIDIA
Одно из основных изменений — NVIDIA теперь разделяет свои продукты на базе Arm и продукты на базе x86, причем Arm занимает первое место. Для справки: сегодня обычный покупатель не может приобрести даже NVIDIA Grace или Grace Hopper, поэтому демонстрация Arm — важная деталь. Ранее уже был запуск линейки x86 NVL с NVIDIA H100 NVL, но это решения на базе Arm. В 2024 году появится GH200NVL. За ней быстро следуют GB200NVL и GX200NVL. Существуют также версии без NVL. Ускоритель GB200 станет следующим поколением в 2024 году, а GX200 — в 2025 году.
 Dual NVIDIA GH200 Refresh
Dual NVIDIA GH200 Refresh
Для рынка x86 в 2024 году выйдет H200, который будет обновлен с большим объемом памяти на архитектуре Hopper. B100 и B40 — это части архитектуры следующего поколения, за которыми последуют X100 и X40 в 2025 году.
В целом запланировано обновление поколения Hopper в 2024 году, переход к поколению Blackwell позже в 2024 году и смена архитектуры в 2025 году. Что касается процессоров, то в последнее время наблюдается война за количество ядер в x86-архитектуре. Например, запланировано, что количество ядер в топовых Xeon от Intel вырастет более чем в 10 раз в период с начала второго квартала 2021 года до второго квартала 2024 года. NVIDIA, похоже, не отстает от нее в центрах обработки данных.
Чип Instinct MI300X от AMD
В июне 2023 года Advanced Micro Devices представила свой чип Instinct MI300X, который стал центральным элементом стратегии компании в области вычислений для искусственного интеллекта. У ускорителя в 2,4 раза больше плотность памяти, чем GPU H100 Hopper от Nvidia, и в 1,6 раза больше пропускная способность.
 Instinct MI300X
Instinct MI300X
Графический процессор Instinct MI300X от AMD имеет несколько «чиплетов» GPU, 192 гигабайта памяти HBM3 DRAM и пропускную способность 5,2 терабайта в секунду. Чип представляет собой продолжение ранее анонсированной модели MI300A. В действительности это комбинация нескольких «чиплетов» — отдельных микросхем, объединенных в единый корпус общей памятью и сетевыми каналами. В MI300X количество транзисторов увеличено со 146 млрд до 153 млрд транзисторов, а общая память DRAM увеличена со 128 Гбайт в MI300A до 192 Гбайт. Пропускная способность памяти увеличена с 800 гигабайт в секунду до 5,2 терабайт в секунду.
По словам компании, это единственный чип, способный обрабатывать в памяти большие языковые модели с количеством параметров до 80 миллиардов. MI300A демонстрируют заказчикам AMD в качестве образца, а MI300X запланировали поставлять с третьего квартала этого года.
Ускоритель Habana Gaudi2 от Intel
Intel не отстает и уже сделала Intel Habana Gaudi2, который тоже сравнивают с H100. Новый суперкомпьютер Intel построен на базе новейших процессоров Intel Xeon Scalable и использует до 4 тыс. аппаратных ускорителей Intel Habana Gaudi2 AI. Если предположить, что в каждой машине используют 8 процессоров Habana Gaudi2 в форм-факторе OAM, то в машине до 500 узлов. Учитывая, что Gaudi2 от Intel обладает впечатляющей производительностью, сравнимой с H100 от Nvidia в некоторых приложениях, суперкомпьютер должен быть достаточно мощным. Вероятно, речь идет о производительности 7–8 FP16 ExaFLOPS в области искусственного интеллекта.
 Intel
Intel
Более того, в конце сентября корпорация Intel объявила об одном из первых в мире крупных развертываний своих ускорителей Gaudi2 для рабочих нагрузок искусственного интеллекта. Суперкомпьютер будет использовать компания Stability AI для приложений генеративного ИИ.
Процессоры Intel используют во многих суперкомпьютерах и даже в системах Nvidia DGX H100 для приложений ИИ и высокопроизводительных вычислений (HPC). Однако собственные вычислительные GPU компании не столь удачны, и на сегодняшний день существует очень мало развертываний ИИ на базе Gaudi/Gaudi2 или Ponte Vecchio. Раз Stability AI теперь работает с Gaudi2, будет интересно посмотреть, какие еще компании решат попробовать свои силы в этом направлении.
Тензорные процессоры TPU v5e от Google Cloud
В августе 2023 года на ежегодной конференции Cloud Next компания Google Cloud объявила о выпуске пятого поколения своих тензорных процессоров (TPU) для обучения нейросетей — TPU v5e.
При его создании особое внимание уделяли эффективности. В сравнении с предыдущим поколением новый обещает 2-кратное улучшение производительности в пересчете на доллар для обучения больших языковых моделей и генеративных нейросетей, а также 2,5-кратное улучшение производительности по тому же критерию для инференс-систем. При стоимости менее половины стоимости TPU v4, TPU v5e позволяет большему числу организаций обучать и развертывать более крупные и сложные модели ИИ. При этом особенно подчеркивается, что компания не экономила на технических характеристиках TPU v5e в угоду рентабельности. Кластеры могут включать до 256 чипов TPU v5e, объединенных высокоскоростным интерконнектом с совокупной пропускной способностью более 400 Тбит/с. Производительность платформы — 100 Попс (Петаопс) в INT8-вычислениях.
 Внутри дата-центра Google
Внутри дата-центра Google
«Мы предоставляем нашим клиентам возможность легко масштабировать свои модели искусственного интеллекта за пределы физических границ одного модуля TPU или одного кластера TPU. Другими словами, одна большая рабочая нагрузка искусственного интеллекта теперь может распределяться на несколько физических кластеров TPU, масштабируясь буквально до десятков тысяч чипов. При этом работа будет выполняться экономически эффективно. В результате, используя облачные графические процессоры и облачные TPU, мы действительно предоставляем нашим клиентам большой выбор, гибкость и дополнительные возможности для удовлетворения потребностей широкого набора рабочих задач, связанных с ИИ, которые, как мы видим, продолжают множиться», — рассказал вице-президент и генеральный директор по вычислительной и ML-инфраструктуре Google Cloud Марк Ломейер.
TPU v5e предлагает интеграцию с Google Kubernetes Engine (GKE), Vertex AI и ведущими фреймворками: Pytorch, JAX и TensorFlow, а также обеспечивает встроенную поддержку популярных инструментов с открытым исходным кодом: Transformers и Accelerate от Hugging Face, PyTorch Lightning и Ray. Также в компании сообщили, что станут общедоступными виртуальные машины A3 на базе графических процессоров NVIDIA H100, поставляемые в виде GPU-суперкомпьютера, для обеспечения работы крупномасштабных моделей ИИ.
Google стратегически интегрировала свои чипы ИИ в рекламные кампании своих облачных предприятий. Например, она объявила о том, что разработчики Midjourney и Character AI используют тензорные процессоры компании.
Чипы Trainium и Inferentia от Amazon
В 2015 году компания Amazon приобрела израильскую компанию Annapurna Labs, которая специализируется на разработке микросхем. Это стало первым шагом Amazon в области разработки чипов. Затем, в 2018 году, она вышла на рынок серверных чипов с микросхемой под названием Graviton. Его особенность в том, что он основан на архитектуре Arm. Это стало вызовом для таких конкурентов, как AMD и Intel, которые лидировали на рынке со своими собственными чипами.
Тем временем компания Amazon Web Services вырвалась в лидеры, став крупнейшим в мире поставщиком облачных вычислений. AWS стремится к инновациям в области ИИ. В июне компания объявила о том, что инвестирует 100 млн долларов в инновационный центр генеративного ИИ. Что касается аппаратного обеспечения ИИ, то в июле AWS представила новое оборудование для ускорения ИИ на базе процессоров Nvidia H100.
Упор Amazon на инновации в области микрочипов привел к созданию двух ключевых микросхем — Inferentia и Trainium. Они призваны сделать модели ИИ более умными и быстрыми. Это своего рода компьютерные мозги. Их позиционируют как альтернативу популярным чипам Nvidia, которые стали дорогими и труднодоступными.
 Inferentia
Inferentia
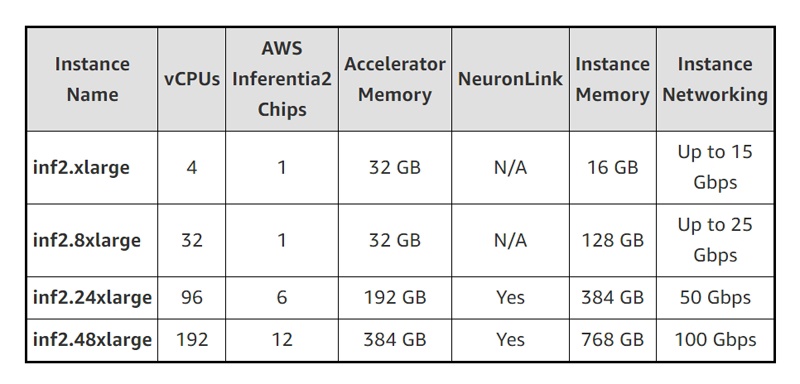
Amazon начала создавать собственные чипы еще в 2013 г. под названием Nitro. Теперь Nitro повсеместно используется в серверах AWS — их насчитывается более 20 млн. Trainium — новичок, появившийся на рынке в 2021 году. Сейчас он гораздо лучше справляется со своей задачей — делает модели машинного обучения более интеллектуальными, а также стоит дешевле — примерно в два раза по сравнению с другими методами. Inferentia существует с 2019 года, и сейчас она уже второго поколения. Пока что графические процессоры Nvidia по-прежнему лидируют в области обучения ИИ, но доминирование Amazon в облачных технологиях может дать ей преимущество на рынке.
Что касается финансовой поддержки корпорации Amazon компании Anthropic, конкурента OpenAI, это обусловлена тем, что Anthropic будет использовать чипы искусственного интеллекта Amazon под названиями Trainium и Inferentia.
Чип MTIA от Meta*
Meta* сконцентрировала усилия на разработке кастомного кремниевого чипа, оптимизированного для ИИ, а также суперкомпьютере на 16 000 GPU для исследований в области ИИ. Эти проекты находятся на стадии реализации и в дальнейшем позволят разрабатывать более крупные и сложные модели ИИ, а затем эффективно внедрять их в масштабах компании. ИИ уже лежит в основе продуктов Meta*, обеспечивая лучшую персонализацию и безопасность.
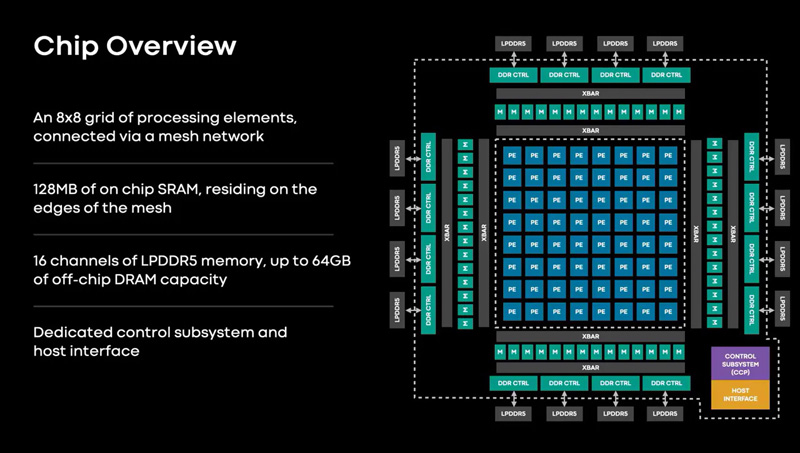
MTIA (Meta* Training and Inference Accelerator) — семейство ускорителей собственной разработки. MTIA обеспечивает более высокую вычислительную мощность и эффективность по сравнению с центральными процессорами и адаптирован для внутренних рабочих нагрузок. Развертывание чипов MTIA и графических процессоров позволяет повысить производительность, уменьшить задержки и увеличить эффективность каждой рабочей нагрузки. Проект MTIA — часть инициативы Meta* по модернизации архитектуры дата-центров в свете стремительного развития ИИ-платформ. Чип MTIA v1 был создан еще в 2020 году. Это интегральная схема специального назначения (ASIC), состоящая из набора блоков, функционирующих в параллельном режиме.
 MTIA
MTIA
Что касается суперкомпьютера Research SuperCluster (RSC) от Meta*, то он считается одним из самых быстрых суперкомпьютеров в мире и создан для обучения следующего поколения больших моделей ИИ. Те в свою очередь планируют задействовать в новых инструментах дополненной реальности, системах понимания контента, технологиях перевода в реальном времени и т.д. Суперкомпьютер оснащен 16 000 графических процессоров, доступных через трехуровневую сетевую структуру Clos, которая обеспечивает полную пропускную способность каждой из 2000 обучающих систем.
Чипы Athena от Microsoft
На конференции Microsoft Ignite, которая пройдет 14 ноября, компания представит свой первый чип для ИИ. Так планируют снизить зависимость от графических процессоров NVIDIA, особенно с учетом ограниченных поставок GPU. Ожидается, что Athena будет конкурировать с флагманским графическим процессором NVIDIA H100 в центрах обработки данных. С помощью Athena Microsoft сможет последовать примеру конкурентов AWS и Google и предложить пользователям облака собственные чипы искусственного интеллекта.

Пока что ускоритель тестирует небольшая группа в Microsoft и OpenAI. Компания начала разработку Athena в 2019 году, стремясь сократить расходы и получить преимущества перед NVIDIA. Подробности о производительности пока не уточняют, но Microsoft надеется, что Athena сможет сравниться с востребованным H100.
OpenAI планирует выпускать собственные чипы
С 2020 года OpenAI разрабатывает свои технологии генеративного ИИ на огромном суперкомпьютере, построенном Microsoft, одним из крупнейших спонсоров проекта. Задействовано 10 000 графических процессоров Nvidia.
Генеральный директор Сэм Альтман публично жаловался на нехватку графических процессоров и поставил их приобретение одним из главных приоритетов компании. С прошлого года в компании обсуждали варианты решения проблемы: создание собственного чипа, более тесное сотрудничество с другими производителями (в том числе Nvidia), а также диверсификацию поставок.
Компания, создавшая ChatGPT, рассматривает возможность выпуска собственных чипов искусственного интеллекта и уже приступила к оценке потенциального объекта приобретения, по словам людей, которые знакомы с планами компании.
Причина не только в дефиците чипов, но и в непомерных расходах. Запуск ChatGPT обходится компании очень дорого. По данным аналитика Bernstein Стейси Расгон, каждый запрос стоит примерно 4 цента. Если объем запросов ChatGPT вырастет до десятых долей от объема поиска Google, то для поддержания работоспособности потребуются графические процессоры на сумму около 48,1 млрд долл. на начальном этапе и около 16 млрд долл. в год.
План по производству собственных ускорителей ИИ — крупная стратегическая инициатива и серьезные инвестиции. Даже если OpenAI выделит ресурсы для решения этой задачи, это не гарантирует успеха. Пока что нет информации о компании, которую OpenAI рассматривает для покупки. Но даже если такой проект реализуют, на это уйдет несколько лет. А пока компания будет зависеть от таких поставщиков, как Nvidia и AMD.
В целом ставки высоки, поскольку чипы ИИ становятся жизненно важными компонентами центров обработки данных. Если раньше под задачу закупали компьютеры и сервера, то теперь проектируют собственные чипы. Для этого, естественно, надо быть Microsoft, Google или Amazon.
Meta* — экстремистская и запрещенная в РФ организация.
Полный текст статьи читайте на Компьютерра
