Внезапный диван леопардовой расцветки
Если вы интересуетесь искусственным интеллектом и прочим распознаванием, то наверняка уже видели эту картинку:  А если не видели, то это результаты Хинтона и Крижевского по классификации ImageNet-2010 глубокой сверточной сетью
А если не видели, то это результаты Хинтона и Крижевского по классификации ImageNet-2010 глубокой сверточной сетью
Давайте взглянем на ее правый угол, где алгоритм опознал леопарда с достаточной уверенностью, разместив с большим отрывом на втором и третьем месте ягуара и гепарда.
Это вообще довольно любопытный результат, если задуматься. Потому что… скажем, вы знаете, как отличить одного большого пятнистого котика от другого большого пятнистого котика? Я, например, нет. Наверняка есть какие-то зоологические, достаточно тонкие различия, типа общей стройности/массивности и пропорций тела, но мы же все-таки говорим о компьютерном алгоритме, которые до сих пор допускают какие-то вот такие достаточно глупые с человеческой точки зрения ошибки. Как он это делает, черт возьми? Может, тут что-то связанное с контекстом и фоном (леопарда вероятнее обнаружить на дереве или в кустах, а гепарда в саванне)? В общем, когда я впервые задумался над конкретно этим результатом, мне показалось, что это очень круто и мощно, разумные машины где-то за углом и поджидают нас, да здравствует deep learning и все такое.
Так вот, на самом деле все совершенно не так.
Один маленький зоологический фактИтак, давайте посмотрим на наших котиков чуть ближе. Вот это — ягуар: 
Самая большая кошка на континентах обоих Америк, при этом единственная, которая периодически убивает жертву путем протыкания клыками черепа и укусания в мозг. Это не тот зоологический факт, который важен для нашей темы, но тем не менее. Среди характерных признаков — цвет глаз, большая челюсть и вообще они наиболее массивные из всей тройки. Как видите, достаточно тонкие детали.
Вот это — леопард: 
Живет в Африке, уступает на этом континенте размерами только льву. У них светлые (желтые) глаза, и существенно более маленькие лапы, чем у ягуара.
Ну и, наконец, гепард: 
Ощутимо меньше по размерам, чем два его собрата. У него длинное, стройное тело, и наконец-то хоть что-то, что может служить визуально заметным признаком — отличительный узор на морде, похожий на темную дорожку слез от глаз к носу.
И вот он тот самый зоологический факт: оказывается, пятна на шкуре этих кошек расположены совсем не случайным образом. Они собраны по несколько штук в маленькие группы, которые называются «розетки». Причем у леопарда розетки условно-маленькие, у ягуара — намного больше (и с маленькими черными точками внутри), а у гепарда их вообще нет — просто россыпь одиноко стоящих пятен.
 Вот здесь это видно лучше. Спонсор спонтанного образования — Imgur, и прошу прощения на случай, если я переврал что-то из матчасти.
Вот здесь это видно лучше. Спонсор спонтанного образования — Imgur, и прошу прощения на случай, если я переврал что-то из матчасти.
Пчелы начинают подозревать Где-то в этот момент в мозг начинает прокрадываться ужасная догадка —, а что если вот это различие в текстуре пятен и есть главный критерий, по которому алгоритм отличает три возможных класса распознавания друг от друга? То есть на самом деле сверточная сеть не обращает внимания на форму изображенного объекта, количество лап, толщину челюсти, особенности позы и все вот эти тонкие различия, которые, как мы было предположили, она умеет понимать — и просто сравнивает картинки как два куска текстуры?
Это предположение необходимо проверить. Давайте возьмем для проверки простую, бесхитростную картинку, без каких-либо шумов, искажений и прочих факторов, осложняющих жизнь распознаванию. Уверен, эту картинку с первого взгляда легко опознает любой человек.

Для проверки воспользуемся Caffe и туториалом по распознаванию на предобученных моделях, который лежит прямо у них на сайте. Здесь мы используем не ту же самую модель, которая упомянута в начале поста, но похожую (CaffeNet), и вообще для наших целей все сверточные сети покажут примерно одинаковый результат.
import numpy as np import matplotlib.pyplot as plt
caffe_root = '…/' import sys sys.path.insert (0, caffe_root + 'python')
import caffe
MODEL_FILE = '…/models/bvlc_reference_caffenet/deploy.prototxt' PRETRAINED = '…/models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel' IMAGE_FILE = '…/sofa.jpg'
caffe.set_mode_cpu ()
net = caffe.Classifier (MODEL_FILE, PRETRAINED,
mean=np.load (caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy').mean (1).mean (1),
channel_swap=(2, 1, 0),
raw_scale=255,
image_dims=(500, 500))
input_image = caffe.io.load_image (IMAGE_FILE)
prediction = net.predict ([input_image])
plt.plot (prediction[0])
print 'predicted class:', prediction[0].argmax ()
plt.show ()
Что получилось: 
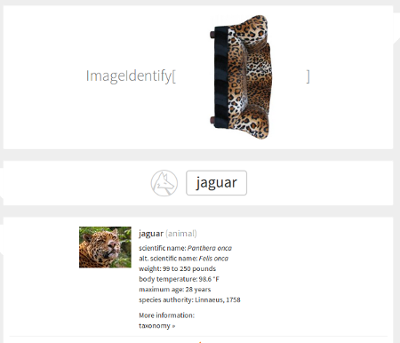
>> predicted class: 290
 Упс.
Упс.
Но погодите, может, это проблема отдельно взятой модели? Давайте сделаем больше проверок:
Clarifai
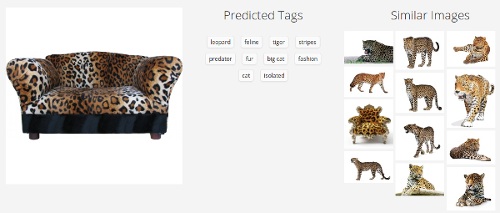
Недавний мега-сервис Стивена Вольфрама
Тут картинка повернута набок — это значит, что сервис справился с правильно ориентированным диваном, но сломался при повороте на 90 градусов. В каком-то смысле это даже хуже, чем если бы он не справился вообще — такое простое преобразование не должно радикальным образом менять результат. Похоже, что наша догадка насчет текстуры близка к истине.
Открытых веб-сервисов распознавания на удивление не так уж и много. Я сделал еще пару проверок (Microsoft, Google) — некоторые из них ведут себя лучше, не подсовывая ягуара, но победить повернутый набок диван не смог никто. Неплохой результат в мире, где уже мелькают заголовки в духе »{Somebody}'s Deep Learning Project Outperforms Humans In Image Recognition».
Почему так происходит? Вот одна из догадок. Давайте представим себя на месте обычного supervised-классификатора, не вдаваясь в детали архитектуры. Мы получаем на входе много-много картинок, каждая из которых промаркирована соответствующим классом, и дальше настраиваем свои параметры таким образом, чтобы для каждой картинки выходные данные соответствовали этому самому классу. Таким образом мы надеемся извлечь из изображения какую-то внутреннюю структуру, отличительные признаки, сформулировать аналитически невыразимое правило распознавания — так, чтобы потом новые, незнакомые изображения, обладающие этими признаками, попадали в нужный класс. В процессе обучения мы руководствуемся величиной ошибки нашего предсказания, и тут важное значение имеет размер и пропорции выборки — если у нас 99 изображений класса A и одно изображение класса B, то при самом глупом поведении классификатора («всегда говори А») ошибка окажется равной 1%, несмотря на то, что мы особенно ничему и не научились.
Так вот, с этой точки зрения никакой проблемы здесь нет. Алгоритм ведет себя так, как ему положено себя вести. Внезапный диван леопардовой расцветки — это аномалия, большая редкость в выборке ImageNet, да и в нашем повседневном опыте тоже. С другой стороны, отличительный паттерн темных пятен на светлом фоне — прекрасный отличительный признак больших пятнистых кошек. Где еще, в конце концов, вы увидите такой узор? Более того, учитывая то, что на классификатор взваливают чертовски непростые задачи в духе различения разных видов кошек — польза узора становится еще большей. Если бы мы подкинули ему в выборку достаточно количество леопардовых диванов, то ему пришлось бы выдумывать новые критерии различия (интересно, какой бы тогда был результат), но раз их нет — то ошибка в таком редком случае совершенно естественна.
Или нет?
What we humans do Вспомните первые классы школы, когда вы учились писать цифры.
Каждому из учеников тогда приносили по увесистой книге с названием «MNIST database», где на сотнях страниц были выписаны шестьдесят тысяч цифр, все — различными почерками и стилями, жирным шрифтом и едва заметным курсивом. Особенно упрямые добирались до еще более огромного приложения «Permutation MNIST», где эти же цифры были повернуты на различные углы, растянуты вверх-вниз и в стороны, и сдвинуты то вправо, то влево — без этого нельзя было научиться определять цифру, посмотрев на нее под углом. Потом, когда долгое и утомительное обучение заканчивалось, каждому выдавали небольшой (сравнительно) список в 10000 цифр, которые нужно было правильно опознать на общеклассовом тестировании. А ведь после математики наступал следующий урок, где приходилось учить значительно более объемный алфавит…
Хм. Говорите, все было совсем не так?
Любопытно, но похоже, нам с вами не так уж и нужна выборка в процессе обучения. По крайней мере, если и нужна, то не для того, зачем ее используют сейчас при обучении классификаторов — для выработки устойчивости к пространственным пермутациям и искажениям. Те же рукописные цифры мы воспринимаем как абстрактные платоновские концепции — вертикальная палка, два кружочка один над другим. Если, например, нам попадется изображение, где нет ни одного из этих концептов, мы отвергнем его как «не цифру», но supervised-классификатор никогда так не сделает. Наши компютерные алгоритмы не ищут концепты — они разгребают груду данных, распихивая их по кучкам, и каждая картинка в конце концов должна оказаться в какой-то кучке, с которой у нее чуть больше общего, чем с остальными.
Много ли вы в своей жизни видели леопардов? Может и порядочно, но наверняка меньше, чем «стаканов», «компьютеров» и «лиц» (другие классы из ImageNet). Встречались ли вам когда-нибудь диваны такой расцветки? Мне, например — почти никогда, кажется. И тем не менее, никто из прочитавших этот текст ни на мгновение не задумался перед тем, как корректно расклассифицировать вышеприведенную картинку.
Сверточные сети усугубляют ситуацию

Сверточные сети постоянно показывают стабильно высокие результаты в соревнованиях на базе ImageNet, и по состоянию на 2014 год они, кажется, уступают только ансамблям из сверточных сетей. Почитать про них подробнее можно много где — пока ограничимся только тем, что это такие сети, которые в процессе обучения формируют маленькие «фильтры» (или kernels), которыми пробегаются по изображению, активируясь в тех местах, где есть соответствующий конкретному фильтру элемент. Их очень любят использовать именно при распознавании изображений — во-первых, потому что там часто есть локальные признаки, способные оказываться в разных местах картинки, а во-вторых, потому что это ощутимо вычислительно дешевле, чем запихивать огромную (1024×768=~800000 параметров) картинку в обычную сеть.
Давайте снова представим себе наших леопардов. Это достаточно сложные физические тела, которые могут принимать кучу разных положений в пространстве, и к тому же еще и сфотографированными с разных углов. Каждая картинка леопарда, скорее всего, будет содержать уникальный, почти не повторяющийся контур — где-то видны усы, лапы и хвост, где-то — только невнятная спина. В таких ситуациях сверточная сеть — это просто наш спаситель, потому что вместо того, чтобы пытаться придумать одно правило для всего этого множества форм, мы просто говорим «возьми вот этот набор маленьких отличительных признаков, пробегись им по картинке и суммируй количество совпадений». Естественно, текстура леопардовых пятен становится хорошим признаком — она есть много где, и практически не меняется при изменении позы объекта. Именно поэтому модели вроде CaffeNet прекрасно реагируют на пространственные вариации объектов на картинках — и именно поэтому, кхм, с ними происходит диван.
Это на самом деле очень неприятное свойство. Отказываясь от полноценного анализа формы объекта на картинке, мы начинаем воспринимать его просто как набор признаков, каждый из которых может находиться где угодно без связи с остальными. Используя сверточные сети, мы сразу отказываемся от возможности отличить кошку, сидящую на полу, от перевернутой кошки, сидящей на потолке. Это хорошо и здорово при распознавании отдельных картинок где-то в интернете, но если такое компьютерное зрение будет координировать ваше поведение в реаллайфе, это будет совсем не здорово.
Если этот аргумент звучит для вас не очень убедительно — загляните в статью Хинтона, которой уже несколько лет, и где отчетливо звучит фраза «convolutional networks are doomed» — именно по этой самой причине. Основная часть статьи посвящена завязке альтернативного концепта — «теории капсул» (над которой он работает как раз сейчас), и тоже очень стоит того, чтобы ее прочитать.
Итого Подумайте об этом ненадолго (и не очень всерьез) — мы ведь все делаем неправильно.
Набивка огромных датасетов картинками, ежегодные соревнования, еще более глубокие сети, еще больше GPU. Мы улучшили распознавание цифр MNIST с ошибки в 0.87 до 0.23 (пруф) — за три года (никто при этом до сих пор не знает точно, какую ошибку может допустить человек). В челленджах ImageNet счет конкурентов идет на десятые доли процента — кажется, вот еще чуть-чуть, и мы точно победим, и получим настоящее компьютерное зрение. И все-таки при этом — нет. Все, что мы делаем — это пытаемся как можно точнее разбросать по категориям кучу картинок, при этом не понимая (я осознаю, что слово «понимать» тут опасно использовать, но), что на них изображено. Что-то должно быть по-другому. Наши алгоритмы должны уметь определять пространственное положение объекта, и повернутый набок диван все-таки опознавать как диван, но с легким предупреждением на тему «хозяин, у тебя мебель вывозят». Они должны уметь обучаться быстро, всего на нескольких примерах — как мы с вами — и не требовать при этом мультиклассовой выборки, а извлекать нужные признаки из объектов самих по себе.
В общем, нам явно есть чем заняться.
