Самое главное о нейронных сетях. Лекция в Яндексе
Константин klakhman Лахман закончил МИФИ, работал исследователем в отделе нейронаук НИЦ «Курчатовский институт». В Яндексе занимается нейросетевыми технологиями, используемыми в компьютерном зрении.
Под катом — подробная расшифровка со слайдами.
Всем привет. Меня зовут Костя Лахман, и тема сегодняшней лекции — это «Нейронные сети». Я работаю в «Яндексе» в группе нейросетевых технологий, и мы разрабатываем всякие прикольные штуки, основанные на машинном обучении, с применением нейронных сетей. Нейронные сети — это один из методов машинного обучения, к которому сейчас приковано достаточно большое внимание не только специалистов в области анализа данных или математиков, но и вообще людей, которые никак не связаны с этой профессией. И это связано с тем, что решения на основе нейронных сетей показывают самые лучшие результаты в самых различных областях человеческого знания, как распознавание речи, анализ текста, анализ изображений, о чем я попытаюсь в этой лекции рассказать. Я понимаю, что, наверное, у всех в этой аудитории и у тех, кто нас слушает, немножко разный уровень подготовки — кто-то знает чуть больше, кто-то чуть меньше, –, но можете поднять руки те, кто читал что-нибудь про нейронные сети? Это очень солидная часть аудитории. Я постараюсь, чтобы было интересно и тем, кто вообще ничего не слышал, и тем, кто что-то все-таки читал, потому что большинство исследований, про которые я буду рассказывать — это исследования этого года или предыдущего года, потому что очень много всего происходит, и буквально проходит полгода, и те статьи, которые были опубликованы полгода назад, они уже немножко устаревают. 
Давайте начнем. Я очень быстро просто расскажу, в чем заключается задача машинного обучения в целом. Я уверен, что многие из вас это знают, но, чтобы двигаться дальше, хотелось бы, чтобы все понимали. На примере задачи классификации как самой понятной и простой.
Пусть у нас есть некоторое U — множество объектов реального мира, и к каждому из этих объектов мы относим какие-то признаки этих объектов. А также у каждого из этих объектов есть какой-то класс, который мы бы хотели уметь предсказывать, имея признаки объекта. Давайте рассмотрим эту ситуацию на примере изображений.
Объекты — это все изображения в мире, которые могут нас интересовать.
Самые простые признаки изображений — это пиксели. За последние полвека, в течение которых человечество занимается распознаванием образов, были придуманы значительно более сложные признаки изображений –, но это самые простые.
И класс, который мы можем отнести к каждому изображению, — это, например, человек (это фотография Алана Тьюринга, например), птица, дом и так далее.
Задачей машинного обучения в данном случае является построение решающей функции, которая по вектору признаков объекта будет говорить, к какому классу она принадлежит. У вас была лекция, насколько я знаю, Константина Воронцова, который про это все рассказывал значительно глубже меня, поэтому я только по самой верхушке.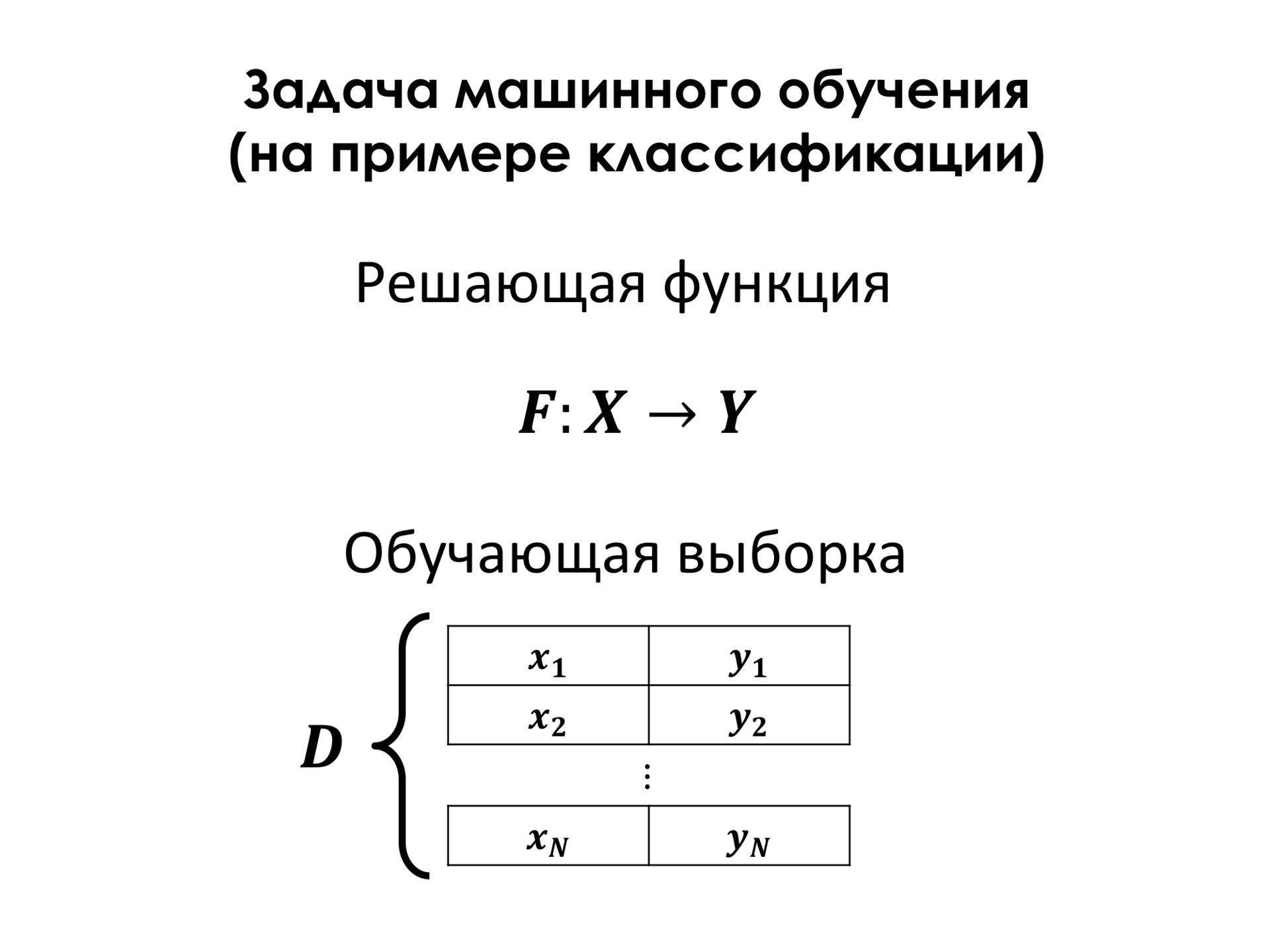
В большинстве случаев необходима так называемая обучающая выборка. Это набор примеров, про которые нам точно известно, что у этого объекта такой класс. И на основе этой обучающей выборки мы можем построить эту решающую функцию, которая как можно меньше ошибается на объектах обучающего множества и, таким образом, рассчитывает, что на объектах, которые не входят в обучающее множество, у нас будет тоже хорошее качество классификаций.
Для этого мы должны ввести некоторую функцию ошибки. Здесь D — это обучающее множество, F — это решающая функция. И в самом простом случае функция ошибки — это просто количество примеров, на которых мы ошибаемся. И, для того чтобы найти оптимальную решающую функцию, нам надо понять. Обычно мы выбираем функцию из какого-то параметрического множества, то есть это просто какой-то, например, полином уравнения, у которого есть какие-то коэффициенты, и нам их надо как-то подобрать. И параметры этой функции, которые минимизируют эту функцию ошибки, функцию потерь, и являются нашей целью, то есть мы хотим найти эти параметры.
Существует множество методов того, как искать эти параметры. Я не буду сейчас в это углубляться. Один из методов — это когда мы берем один пример этой функции, смотрим, правильно ли мы его классифицировали или неправильно, и берем производную по параметрам нашей функции. Как известно, если мы пойдем в сторону обратной этой производной, то мы, таким образом, уменьшим ошибку на этом примере. И, таким образом, проходя все примеры, мы будем уменьшать ошибку, подстраивая параметры функции.
То, о чем я сейчас рассказывал, относится ко всем алгоритмам машинного обучения и в той же степени относится к нейросетям, хотя нейросети всегда стояли немножко в стороне от всех остальных алгоритмов.
Сейчас всплеск интереса к нейросетям, но это один из старейших алгоритмов машинного обучения, который только можно придумать. Первый формальный нейрон, ячейка нейронный сети была предложена, его первая версия, в 1943 году Уорреном Маккалоком и Уолтером Питтсом. Уже в 1958 году Фрэнк Розенблатт предложил первую самую простую нейронную сеть, которая уже могла разделять, например, объекты в двухмерном пространстве. И нейронные сети проходили за всю эту более чем полувековую историю взлеты и падения. Интерес к нейронным сетям был очень большой в 1950–1960-е годы, когда были получены первые впечатляющие результаты. Затем нейронные сети уступили место другим алгоритмам машинного обучения, которые оказались более сильными в тот момент. Опять интерес возобновился в 1990-е годы, потом опять ушел на спад.
И сейчас в последние 5–7 лет оказалось, что во многих задачах, связанных с анализом естественной информации, а все, что нас окружает — это естественная информация, это язык, это речь, это изображение, видео, много другой самой разной информации, — нейронные сети лучше, чем другие алгоритмы. По крайней мере, на данный момент. Возможно, опять ренессанс закончится и что-то придет им на смену, но сейчас они показывают самые лучшие результаты в большинстве случаев.
Что же к этому привело? То что нейронные сети как алгоритм машинного обучения, их необходимо обучать. Но в отличие от большинства алгоритмов нейронные сети очень критичны к объему данных, к объему той обучающей выборки, которая необходима для того, чтобы их натренировать. И на маленьком объеме данных сети просто плохо работают. Они плохо обобщают, плохо работают на примерах, которые они не видели в процессе обучения. Но в последние 15 лет рост данных в мире приобретает, может быть, экспоненциальный характер, и сейчас это уже не является такой большой проблемой. Данных у нас очень много.
Второй такой краеугольный камень, почему сейчас ренессанс сетей — это вычислительные ресурсы. Нейронные сети — один из самых тяжеловесных алгоритмов машинного обучения. Необходимы огромные вычислительные ресурсы, чтобы обучить нейронную сеть и даже чтобы ее применять. И сейчас такие ресурсы у нас есть. И, конечно, новые алгоритмы были придуманы. Наука не стоит на месте, инженерия не стоит на месте, и теперь мы больше понимаем о том, как обучать подобного рода структуры.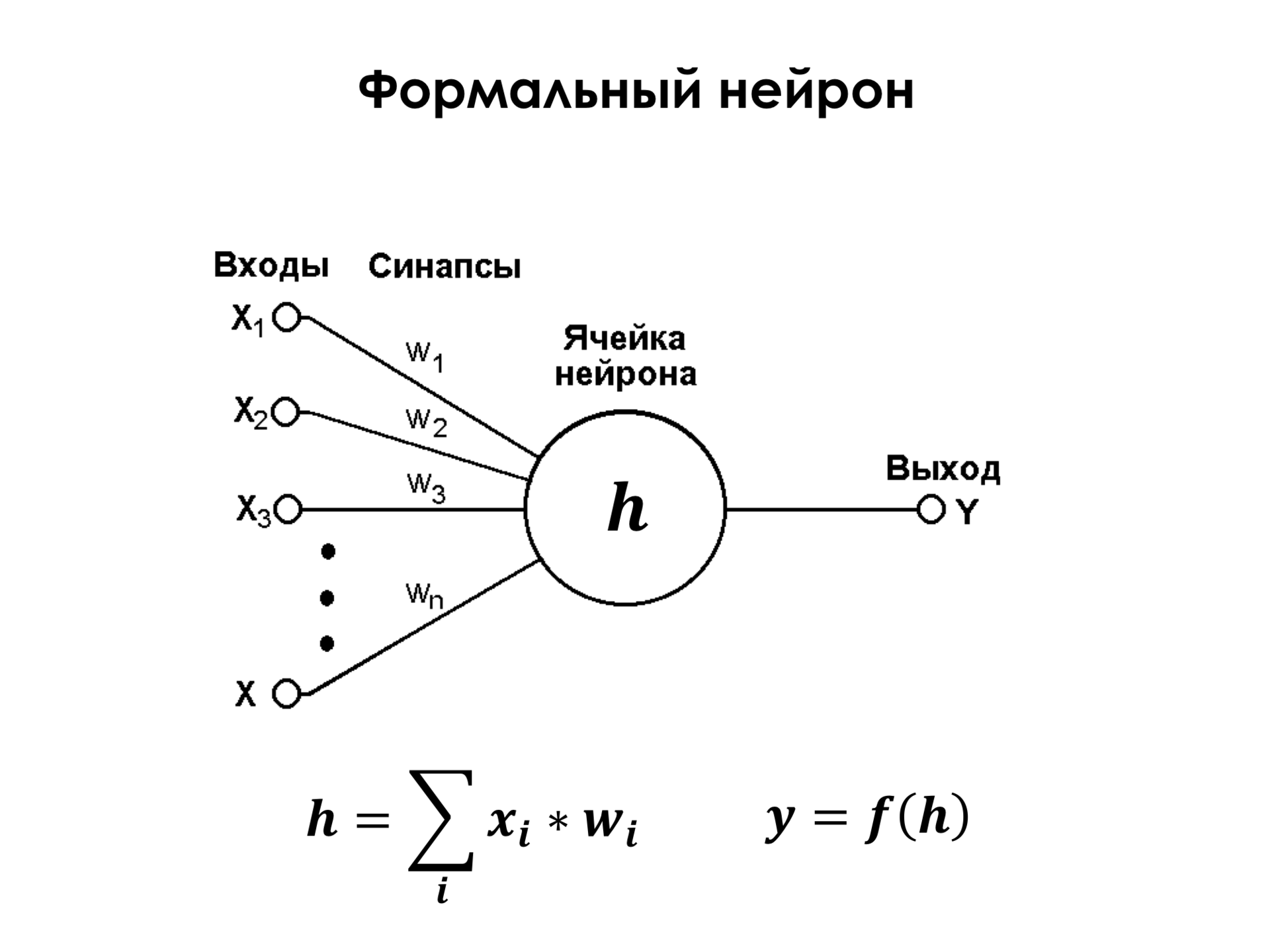
Что такое формальный нейрон? Это очень простой элемент, у которого есть какое-то ограниченное количество входов, к каждому из этих входов привязан некоторый вес, и нейрон просто берет и осуществляет взвешенную суммацию своих входов. На входе могут быть, например, те же самые пиксели изображения, про которые я рассказывал раньше. Представим себе, что X1 и до Xn — это просто все пиксели изображения. И к каждому пикселю привязан какой-то вес. Он их суммирует и осуществляет некоторое нелинейное преобразование над ними. Но даже если не касаться линейного преобразования, то уже один такой нейрон является достаточно мощным классификатором. Вы можете заменить этот нейрон и сказать, что это просто линейный классификатор, и формальный нейрон им и является, это просто линейный классификатор. Если, допустим, в двухмерном пространстве у нас есть некоторое множество точек двух классов, а это их признаки X1 и X2, то есть, подобрав эти веса V1 и V2, мы можем построить разделяющую поверхность в этом пространстве. И, таким образом, если у нас эта сумма, например, больше нуля, то объект относится к первому классу. Если эта сумма меньше нуля, то объект относится ко второму классу.
И все бы хорошо, но единственное, что эта картинка очень оптимистичная, тут всего два признака, классы, что называется, линейно разделимые. Это означает, что мы можем просто провести линию, которая правильно классифицирует все объекты обучающего множества. На самом деле так бывает не всегда, и практически никогда так не бывает. И поэтому одного нейрона недостаточно, чтобы решать подавляющее большинство практических задач.
Это нелинейное преобразование, которое осуществляет каждый нейрон над этой суммой, оно критически важно, потому что, как мы знаем, если мы, например, осуществим такую простую суммацию и скажем, что это, например, какой-то новый признак Y1 (W1×1+W2×2=y1), а потом у нас есть, например, еще второй нейрон, который тоже суммирует те же самые признаки, только это будет, например, W1'x1+W2'x2=y2. Если мы потом захотим применить опять линейную классификацию в пространстве этих признаков, то это не будет иметь никакого смысла, потому что две подряд примененные линейные классификации легко заменяются на одну, это просто свойство линейности операций. А если мы осуществим над этими признаками некоторое нелинейное преобразование, например, самое простое… Раньше применяли более сложные нелинейные преобразования, такие, как эта логистическая функция, она ограничена нулем и единицей, и мы видим, что здесь есть участки линейности. То есть она около 0 по x ведет себя достаточно линейно, как обычная прямая, а дальше она ведет себя нелинейно. Но, как оказалось, чтобы эффективно обучать подобного рода классификаторы, достаточно самой простой нелинейности на свете — просто урезанной прямой, когда на положительном участке это прямая, а на отрицательном участке это всегда 0. Это самая простая нелинейность, и оказывается, что даже ее уже достаточно, чтобы эффективно обучать классификацию. 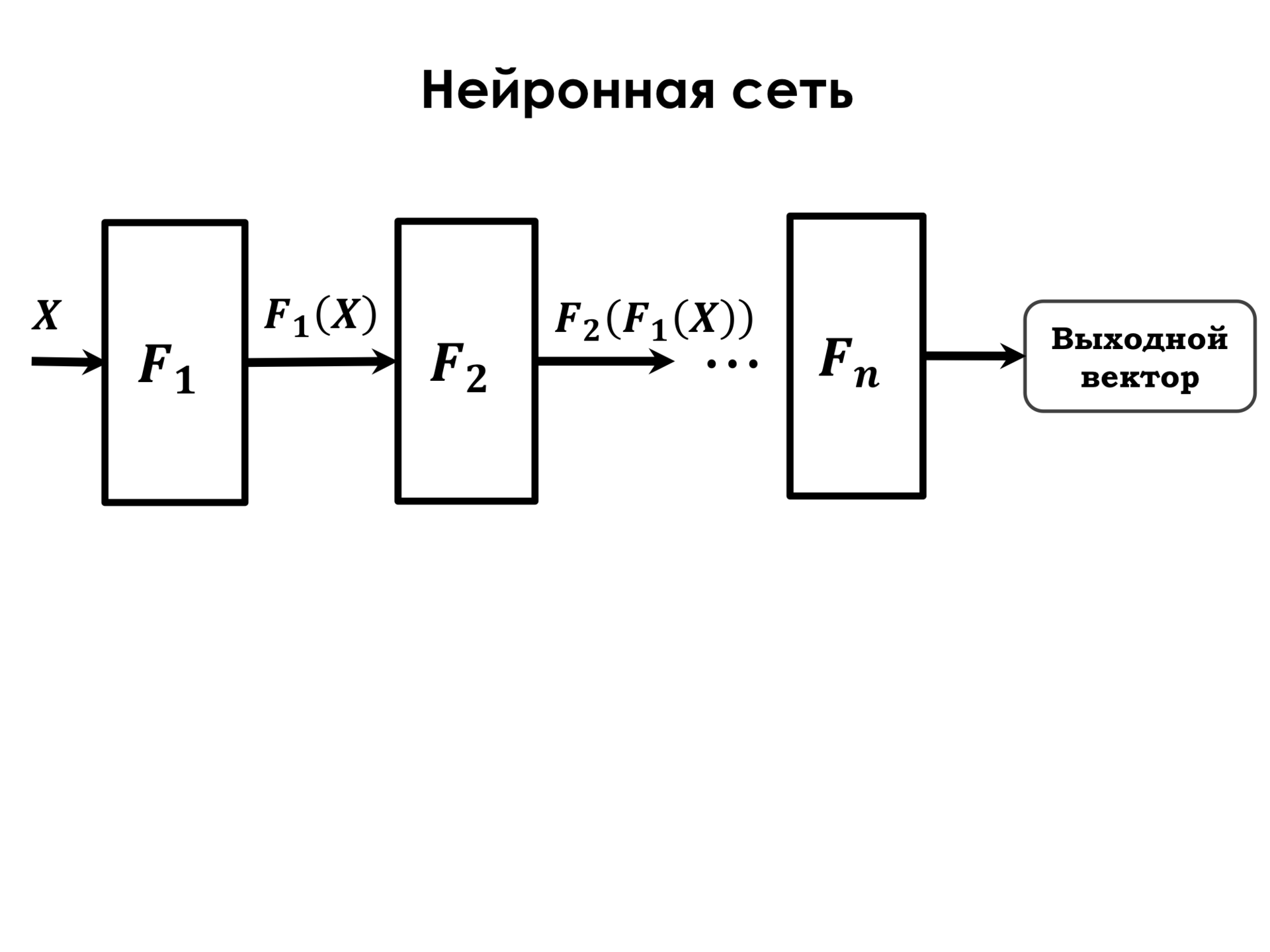
Что представляет из себя нейронная сеть? Нейронная сеть представляет из себя последовательность таких преобразований. F1 — это так называемый слой нейронной сети. Слой нейронной сети — это просто совокупность нейронов, которые работают на одних и тех же признаках. Представим, что у нас есть исходные признаки x1, x2, x3, и у нас есть три нейрона, каждый из которых связан со всеми этими признаками. Но у каждого из нейронов свои веса, на которых он взвешивает такие признаки, и задача обучения сети в подборе таких весов у каждого из нейронов, которые оптимизируют эту нашу функцию ошибки. И функция F1 — это один слой таких нейронов, и после применения функция у нас получается некоторое новое пространство признаков. Потом к этому пространству признаков мы применяем еще один такой слой. Там может быть другое количество нейронов, какая-то другая нелинейность в качестве преобразующей функции, но это такие же нейроны, но с такими весами. Таким образом, последовательно применяя эти преобразования, у нас получается общая функция F — функция преобразования нейронной сети, которая состоит из последовательного применения нескольких функций.
Как обучаются нейронные сети? В принципе, как и любой другой алгоритм обучения. У нас есть некоторый выходной вектор, который получается на выходе сети, например, класс, какая-то метка класса. Есть некоторый эталонный выход, который мы знаем, что у этих признаков должен быть, например, такой объект, или какое число мы должны к нему привязать.
И у нас есть некоторая дельта, то есть разница между выходным вектором и эталонным вектором, и дальше на основе этой дельты здесь есть большая формула, но суть ее заключается в том, что если мы поймем, что эта дельта зависит от Fn, то есть от выхода последнего слоя сети, если мы возьмем производную этой дельты по весам, то есть по тем элементам, которые мы хотим обучать, и еще применим так называемое правило цепочки, то есть когда у нас производные сложной функции — это произведение от производной по функции на произведение функции по параметру, то получится, что таким нехитрым образом мы можем найти производные для всех наших весов и подстраивать их в зависимости от той ошибки, какую мы наблюдаем. То есть если у нас на каком-то конкретном обучающем примере нет ошибки, то, соответственно, производные будут равны нулю, и это означает, что мы его правильно классифицируем и нам ничего не надо делать. Если ошибка на обучающем примере очень большая, то мы должны что-то с этим сделать, как-то изменить веса, чтобы уменьшить ошибку.
Сверточные сети
Сейчас было немножко математики, очень поверхностно. Дальше большая часть доклада будет посвящена крутым вещам, которые можно сделать с помощью нейронных сетей и которые делают сейчас многие люди в мире, в том числе и в Яндексе.

Одним из методов, который первым показал практическую пользу, являются так называемые сверточные нейронные сети. Что такое сверточные нейронные сети? Допустим, у нас есть изображение Альберта Эйнштейна. Эту картину, наверное, многие из вас тоже видели. И эти кружочки — это нейроны. Мы можем подсоединить нейрон ко всем пикселям входного изображения. Но тут есть большая проблема, что если подсоединить каждый нейрон ко всем пикселям, то, во-первых, у нас получится очень много весов, и это будет очень вычислительно емкая операция, очень долго будет вычислять такую сумму для каждого из нейронов, а во-вторых, весов получится так много, что этот метод будет очень неустойчив к переобучению, то есть к эффекту, когда на обучающем множестве мы все хорошо предсказываем, а на множестве примеров, которые не входят в обучающие, мы работаем очень плохо, просто потому, что мы перестроились на обучающее множество. У нас слишком много весов, слишком много свободы, мы можем очень хорошо объяснить любые вариации в обучающем множестве. Поэтому придумали другую архитектуру, в которой каждый из нейронов подсоединен только к небольшой окрестности на изображении. Кроме всего прочего все эти нейроны обладают одними и теми же весами, и такая конструкция называется сверткой изображения.
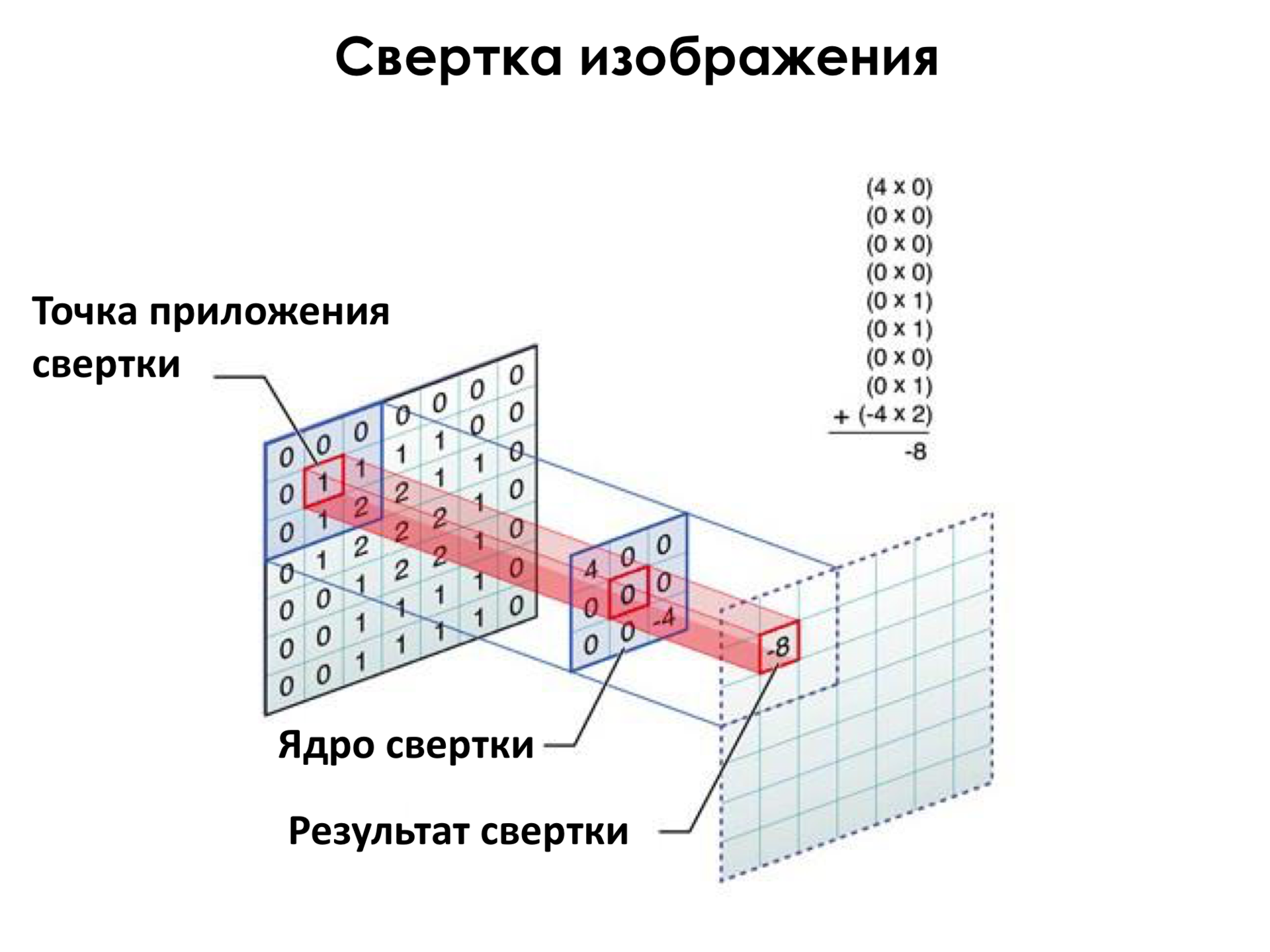
Как она осуществляется? У нас тут в центре есть так называемое ядро свертки — это совокупность весов этого нейрона. И мы применяем это ядро свертки во всех пикселях изображения последовательно. Применяем — это означает, что мы просто взвешиваем пиксели в этом квадрате на веса, и получаем некоторое новое значение. Можно сказать, что мы преобразовали картинку, прошлись по ней фильтром. Как в Photoshop, например, существуют какие-то фильтры. То есть самый простой фильтр — как можно из цветной картинки сделать черно-белую. И вот мы прошлись таким фильтром и получили некоторое преобразованное изображение.
В чем здесь плюс? Первый плюс, что меньше весов, быстрее считать, меньше подвержены к переобучению. С другой стороны, каждый из этих нейронов получается некоторым детектором, как я покажу это дальше. Допустим, если где-то у нас на изображении есть глаз, то мы одним и тем же набором весов, пройдясь по картинке, определим, где на изображении глаз.
Здесь должно быть видео.
И одной из первых вещей, к чему применили подобную архитектуру — это распознавание цифр, как самых простых объектов.
Применил это где-то в 1993 году Ян Лекун в Париже, и здесь сейчас будет практически архивная запись. Качество так себе. Здесь сейчас они предоставляют рукописные цифры, нажимают некоторую кнопочку, и сеть распознает эти рукописные цифры. В принципе, безошибочно она распознает. Ну, эти цифры, естественно, проще, потому что они печатные. Но, например, на этом изображении цифры уже значительно сложнее. А эти цифры, честно сказать, даже я не совсем могу различить. Там, кажется, четверка слева, но сеть угадывает. Даже такого рода цифры она распознает. Это был первый успех сверточных нейронных сетей, который показал, что они действительно применимы на практике.
В чем заключается специфика этих сверточных нейронных сетей? Эта операция свертки элементарная, и мы строим слои этих сверток над изображением, преобразовывая все дальше и дальше изображения. Таким образом, мы на самом деле получаем новые признаки. Наши первичные признаки — это были пиксели, а дальше мы преобразовываем изображение и получаем новые признаки в новом пространстве, которые, возможно, позволят нам более эффективно классифицировать это изображение. Если вы себе представите изображение собак, то они могут быть в самых разных позах, в самых разных освещениях, на разном фоне, и их очень сложно классифицировать, непосредственно опираясь только на пиксели. А последовательно получая иерархию признаков новых пространств, мы это сделать можем.
Вот в чем основное отличие нейронных сетей от остальных алгоритмов машинного обучения. Например, в области компьютерного зрения, в распознавании изображений до нейронных сетей был принят следующий подход.
Когда вы берете предметную область, например, нам нужно между десятью классами определять, к какому из классов принадлежит объект — дом, птица, человек, люди очень долго сидели и думали, какие бы признаки можно было найти, чтобы отличать эти изображения. Например, изображение дома легко отличить, если у нас много геометрических линий, которые как-то пересекаются. У птиц, например, бывает очень яркий окрас, поэтому если у нас есть сочетание зеленых, красных, других признаков, то, наверное, это больше похоже на птицу. Весь подход заключался в том, чтобы придумать как можно больше таких признаков, а дальше подать их на какой-нибудь достаточно простой линейный классификатор, примерно такой, который состоит на самом деле из одного слоя. Есть еще и сложнее методы, но, тем не менее, они работали на этих признаках, которые придуманы человеком. А с нейронными сетями оказалось, что вы можете просто сделать обучающую выборку, не выделять никакие признаки, просто подать ей на вход изображения, и она сама обучится, она сама выделит те признаки, которые критичны для классификации этих изображений за счет этой иерархии.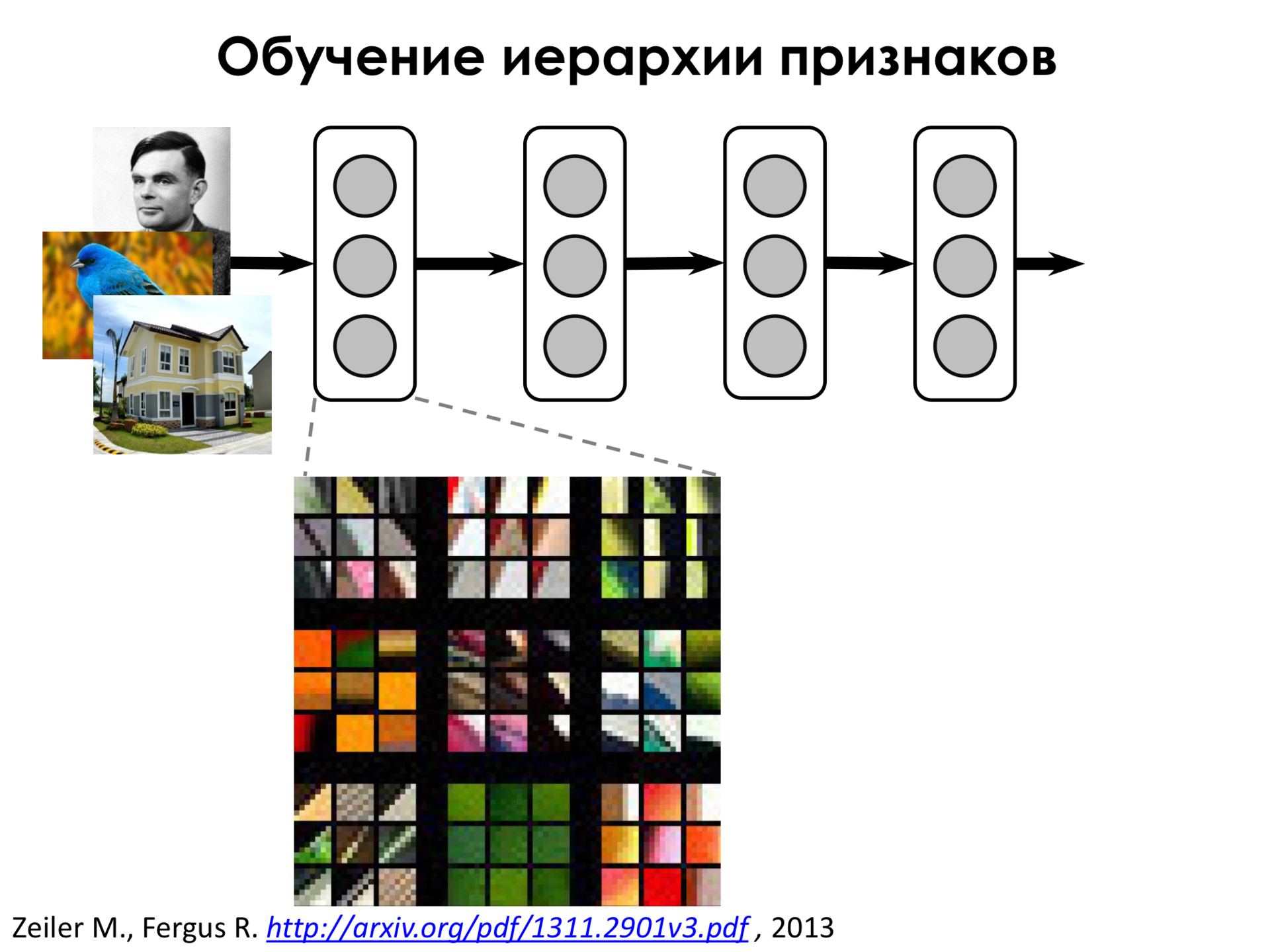
Давайте посмотрим на то, какие признаки выделяет нейронная сеть. На первых слоях такой сети оказывается, что сеть выделяет очень простые признаки. Например, переходы градиентов или какие-то линии под разным углом. То есть она выделяет признаки — это означает, что нейрон реагирует, если примерно такой кусок изображения он видит в окне своего ядра свертки, в области видимости. Эти признаки не очень интересны, мы бы и сами их могли придумать.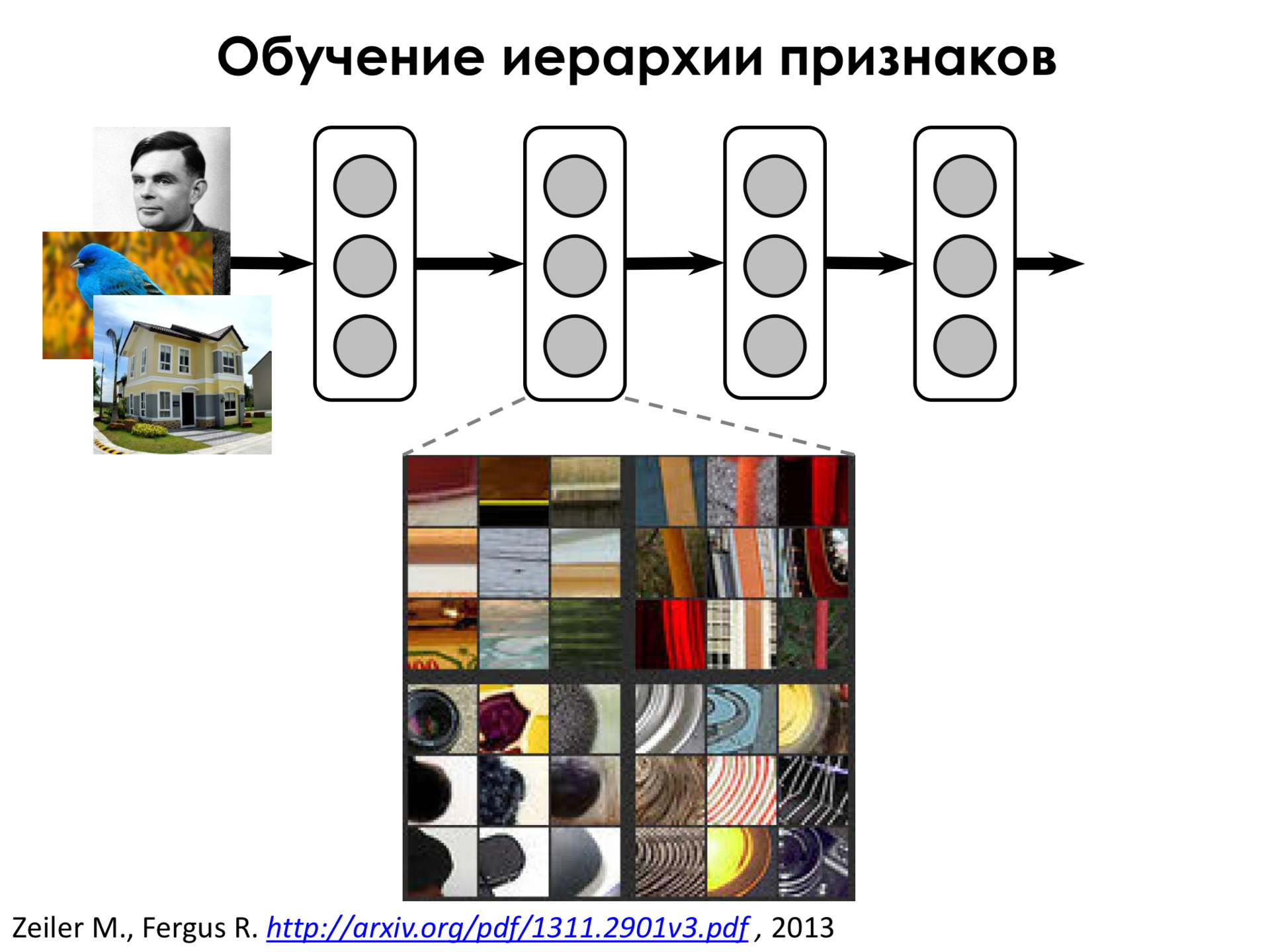
Переходя глубже, мы видим, что сеть начинает выделять более сложные признаки, такие, как круговые элементы и даже круговые элементы вместе с какими-то полосками.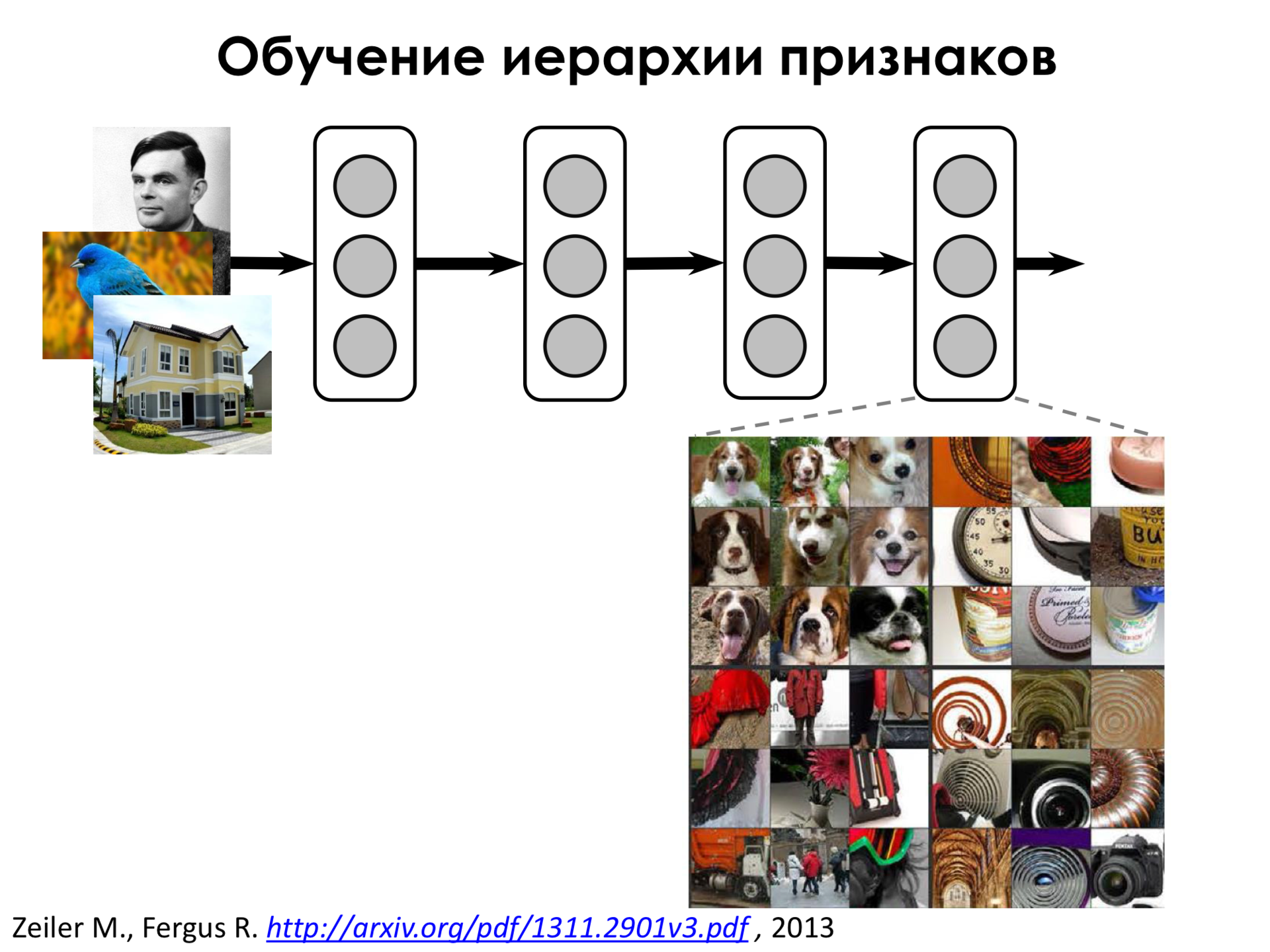
И чем дальше мы идем по нейронной сети, чем дальше мы от входа, тем более сложными становятся признаки. То есть, например, этот нейрон уже может реагировать на лицо собаки, то есть он зажигается, когда видит в части изображения лицо собаки, банку, часы, еще что-то такое.
Для чего это все нужно? Есть по современным меркам не очень большая, но три года это была самая большая размеченная база изображений в мире Image.net. В ней есть чуть больше миллиона изображений, которые разделены на тысячу классов. И необходимо добиться наибольшей точности распознавания на этой выборке.
Эта выборка совсем непростая. Надо просто понять, что, например, хаски и сибирский хаски — это два разных класса там. Если мне показать два эти изображения, я не отличу, где хаски, а где сибирский хаски, а сеть может отличить. Там, по-моему, больше 300 пород собак разных классов и пара десятков только видов терьеров. То есть человек, наверное, обладающий каким-то специфическим знанием в области кинологии, но обычный человек не может.
Применили нейронную сеть к этой выборке изображений, и оказалось, что она очень неплохо с ней справляется. Например, здесь показана картинка, под картинкой показан правильный класс, а здесь показаны столбиками предсказания сети. И чем больше столбик, тем больше сеть уверена, что это предсказание правильно. И мы видим, что она правильно предсказывает леопарда, предсказывает скутер, несмотря на то что здесь кроме скутера еще люди есть на изображении. Но она видит, что скутер — это доминирующий объект на изображении, и предсказывает именно его. Допустим, она даже предсказывает клеща, несмотря на то что все изображение состоит просто из однородного фона, и клещ только где-то в самом-самом углу. Но она понимает, что клещ является основой этой сцены. При этом анализ ошибок нейронной сети тоже очень интересен и позволяет выявить, например, ошибки в обучающем множестве, потому что это множество размечали люди, и люди всегда ошибаются. Допустим, есть картинка с далматином и вишней, на которую нейронная сеть с огромной уверенностью отвечает, что это далматин. Ну, правда, мы смотрим на это изображение и видим, что основной объект — далматин. Но на самом деле на переднем фоне здесь есть вишня, и человек, который размечал это изображение в процессе подготовки выборки, почему-то решил, что вишня — это доминирующий объект на этом изображении. И получается, что нейронная сеть ошиблась по нашей метрике.
С другой стороны, например, здесь есть некоторое животное справа внизу. Я не знал, что это за животное. В разметке написано, что это мадагаскарская кошка. Поверим разметке. Но сеть делает очень резонное предположение о том, что это может быть. Она говорит, что это какой-то вид обезьяны. Мне кажется, что эти ошибки они очень разумны. То есть я тоже мог бы предположить, что это какой-то вид обезьяны, очень нераспространенный и экзотический.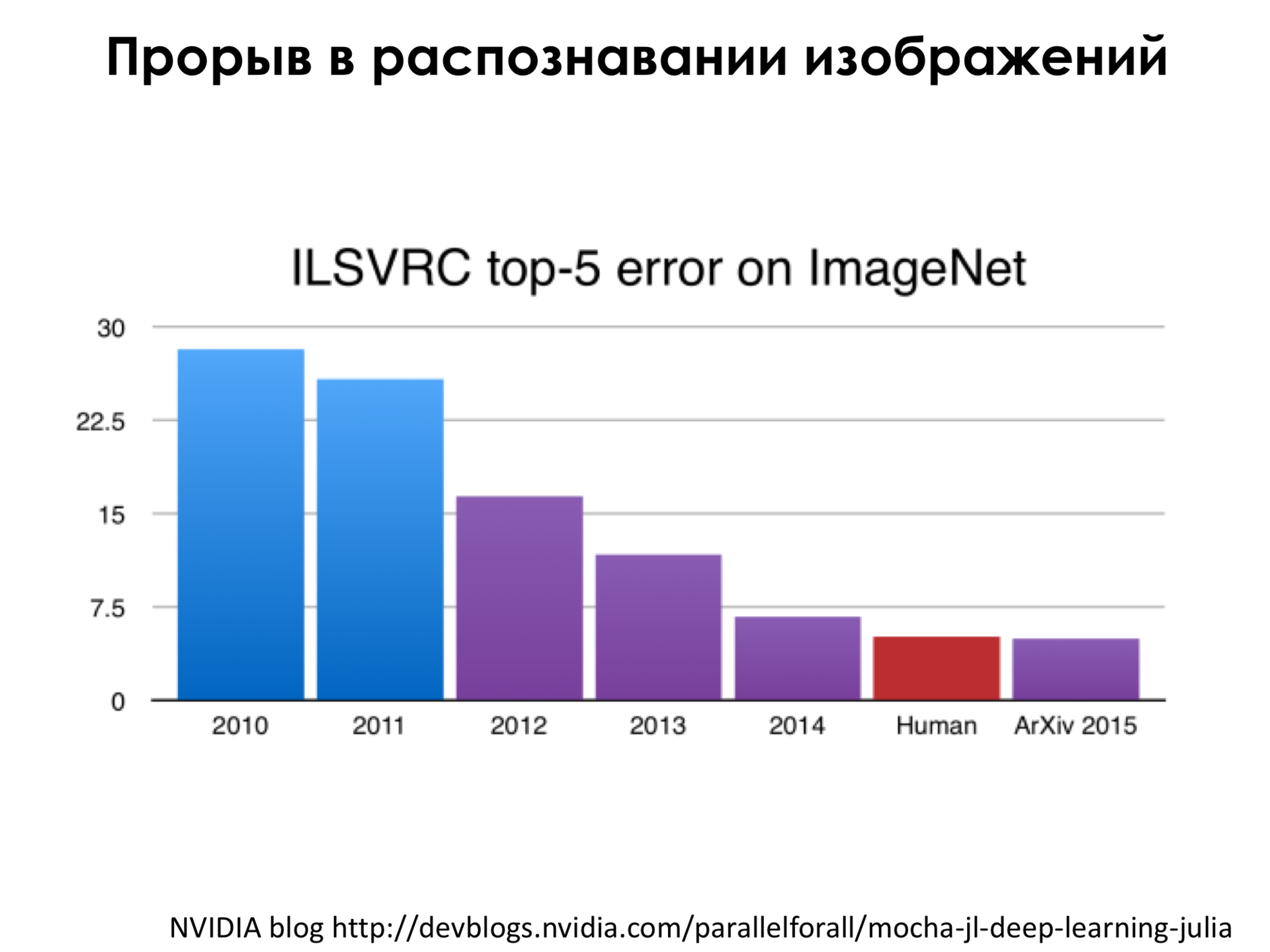
Основной метрикой ошибки на этой базе является так называемая Топ-5 ошибка. Это когда мы берем Топ-5 предсказаний, первые пять предсказаний нашей сети, в которых она наиболее уверена, и если правильный класс из разметки попал в эти пять предсказаний, то мы говорим, что сеть права. И ошибка — это когда у нас в первые пять предсказаний не попал правильный класс. И до эры нейронной сети (это 2010–2011 год, это до эры сверточных нейронных сетей) мы видим, что ошибка, конечно, уменьшалась, была чуть ниже 30%, а в 2011 году еще чуть ниже, но, например, в 2012 году, когда впервые применили сверточную нейронную сеть к этой задаче, оказалось, что мы можем снизить ошибку радикально, то есть все остальные методы были на это неспособны, а нейронная сеть была на это способна, и дальше по мере роста интереса к нейронным сетям оказалось, что мы можем снизить эту ошибку — это сейчас будет некоторая спекуляция — на уровень, которого может достичь человек на этой базе. Было проведено некоторое исследование, оно было не очень глобальное, там было пять человек, которые несколько дней готовились распознавать подобного рода изображения, и у них получилась ошибка где-то в районе 4,5% на этой выборке, и нейронная сеть на момент весны или лета 2015 года этот рубеж побила, что всех очень поразило, было очень много новостных заметок по этом поводу, и так далее.
То, о чем я говорил раньше, что глубина этой сети, то есть количество этих функций, которые мы последовательно применяем к входному изображению, имеет значение. Например, в 2013 году победила такая сеть, которая имела порядка, по-моему, 8 или 9 слоев последовательного преобразования изображения. А, например, в 2014 году победила такая сеть, в которой очень много слоев и архитектура в целом значительно сложнее, но главное, что она глубже, то есть это означает, что мы больше применяем нелинейности к нашему входному изображению, и за счет этого мы получаем прорыв в качестве.
Для чего все это нужно? Не только распознавать изображения, но и как мы можем применить это на практике? Например, так как мы с вами уже знаем, что на каждом слое мы получаем некоторые новые признаки, то мы можем взять с какого-нибудь одного из последних слоев нейронной сети выходы и считать что-то, допустим, это некоторые новые признаки изображения, и искать похожие изображения на основе этих признаков, то есть, грубо говоря, попробовать найти изображения с такими же признаками, как у входного. Например, есть такая картинка, ребята играют в баскетбол, NBA, все дела, и мы хотим найти похожие изображения.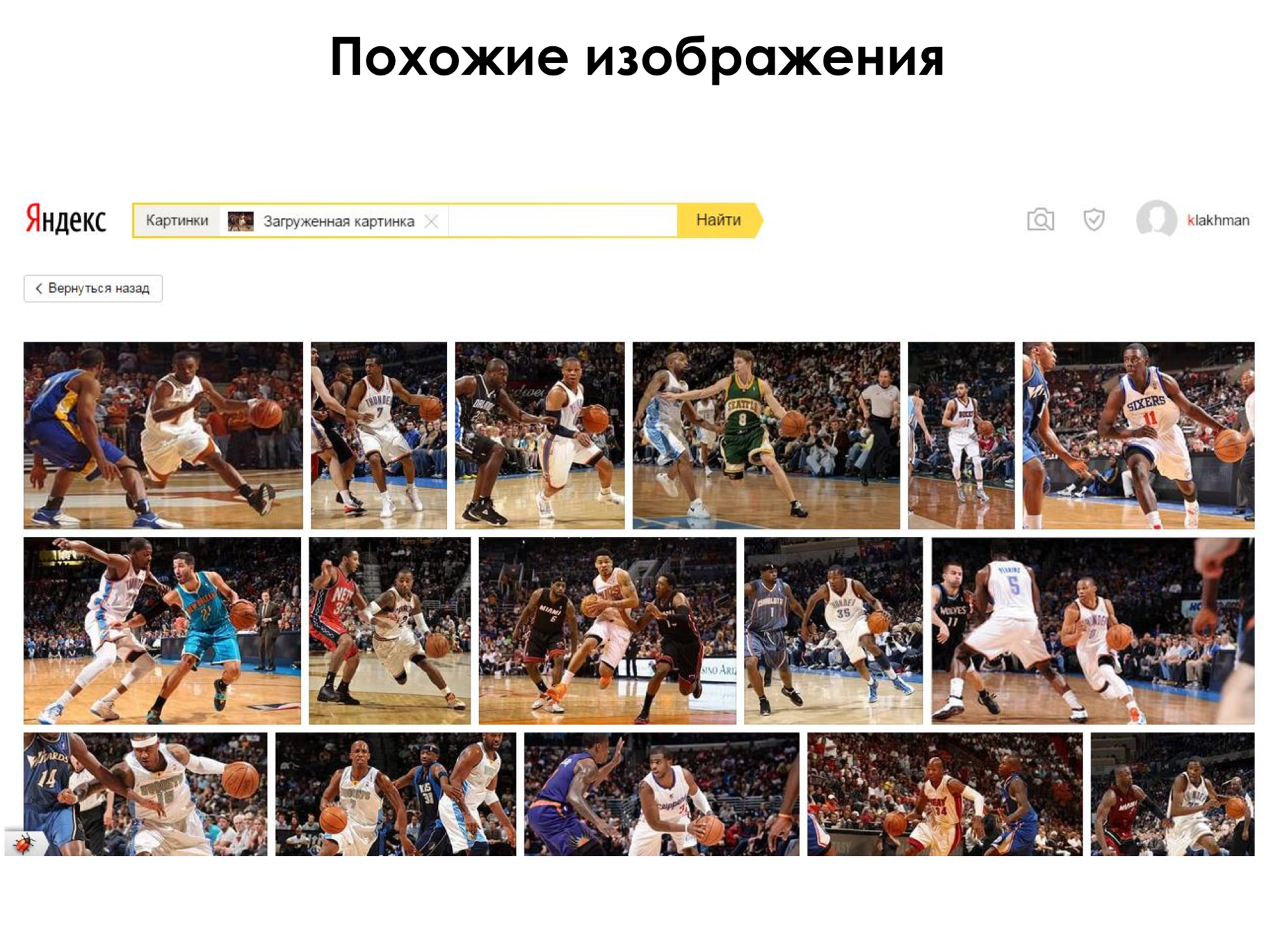
Кидаем эту картинку в сервис похожих изображений и, действительно, находим другие изображения. Это другие игроки, другие команды. Но мы видим, что все они относятся к тому, как игрок ведет мяч на площадке.
На самом деле, у того, о чем я сейчас рассказываю — у алгоритмов компьютерного зрения — есть очень много применений, но есть также очень много применений в реальном мире, такие, как поиск таких изображений, распознавание. Но есть очень много и анекдотичных применений. Например, группа исследователей попробовала взять достаточно простую картинку, она здесь слева в верхнем ряду изображения, и научить сеть стилизовывать это изображение под картины разных великих художников, таких, как Пабло Пикассо, Кандинский, Винсент Ван Гог. Фактически они подавали на вход обычные изображения и картину и говорили, что «Мы хотим, чтобы, с одной стороны, выходное изображение было похоже на исходное, но также чтобы в нем присутствовал некоторый стиль этого художника». И, как мы видим, оно достаточно интересным образом преобразует картинки. И, с одной стороны, мы можем узнать исходное изображение, а также черты автора. Как видите, большинство статей, про которые рассказываю, — это где-то 2014–2015 год, и вы тоже можете зайти и посмотреть более подробно.
Рекуррентные нейронные сети
В последний год приобретают популярность другие модели нейронных сетей: не сверточные, которые мы применяем к изображениям, а так называемые рекуррентные модели нейронных сетей. Что это такое?
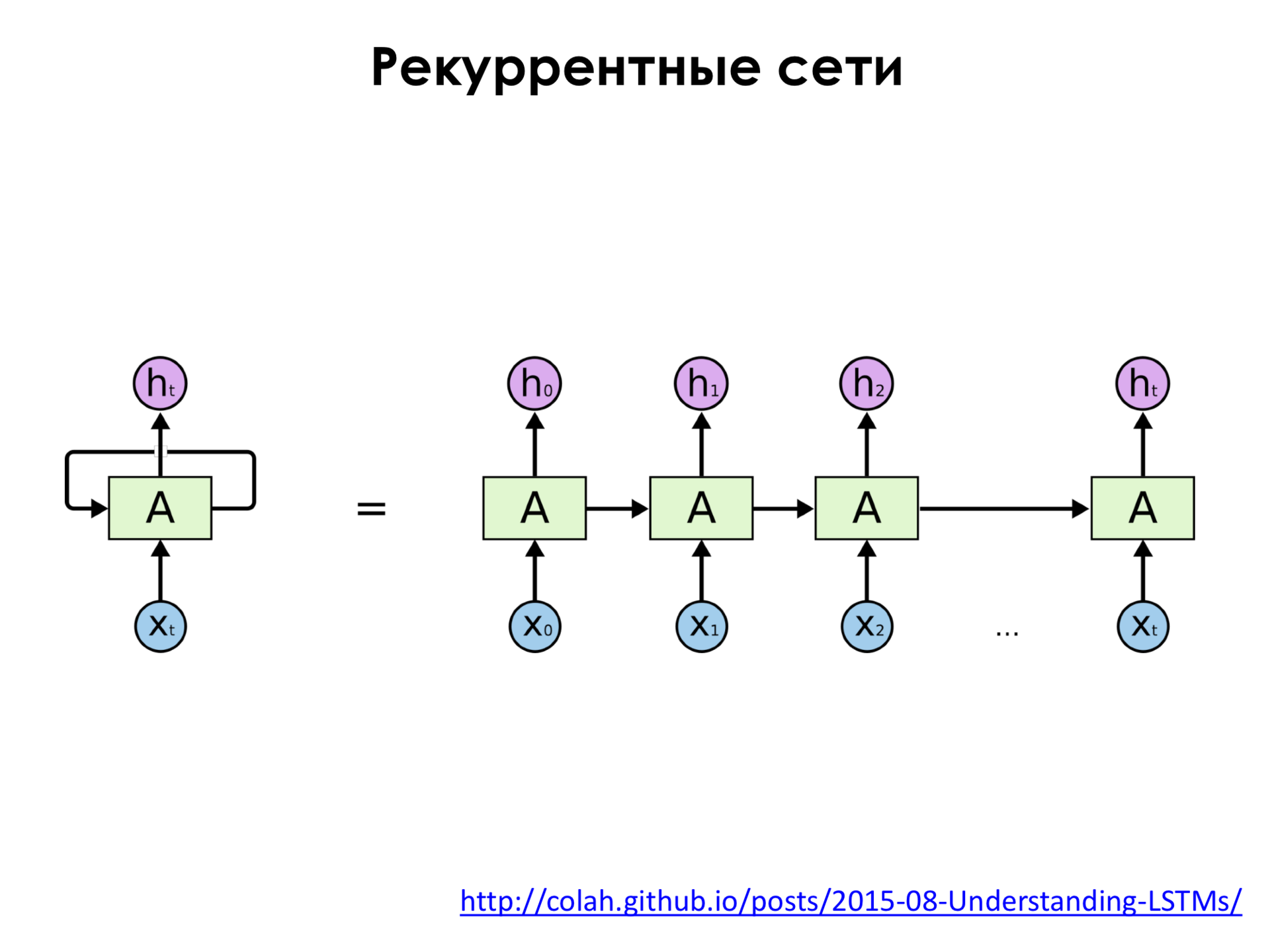
Обычно такая сеть — сеть прямого распространения — не имеет в себе никакой памяти. То есть, допустим, мы подали изображение на эту сеть, она что-то распознала, мы подали следующее изображение, и она ничего про предыдущее изображение уже не помнит. То есть она никак не связывает последовательность изображений между собой. Во множестве задач такой подход не очень применим, потому что если мы, например, возьмем какой-нибудь текст, допустим, текст на естественном языке, какая-нибудь глава книжки, то этот текст состоит из слов, и эти слова образуют некоторую последовательность. И нам бы хотелось, чтобы мы, например, подавали это слово на сеть, потом подавали на следующее слово, но чтобы она не забыла про предыдущее слово, чтобы она помнила про него, помнила, что оно было, и анализировала каждое следующее слово с учетом предыдущей истории. И для этого существуют рекуррентные нейронные сети. Как здесь видно, кроме того, что у нас есть путь от входных признаков к некоторому выходу нейронной сети, мы также учитываем сигналы из этих внутренних слоев с предыдущих временных шагов, то есть мы как бы запоминаем информацию, подаём её на вход опять самим себе. И такую рекуррентную нейронную сеть можно развернуть.
Справа — это просто развертка по времени. x0, x1, x2 и так далее. И сеть еще помнит свое предыдущее состояние. И то, как она анализирует каждый входной объект, зависит не только от этого объекта, но и от предыдущей истории.
Для чего это применяется? Одно из интересных применений — например, мы хотим генерировать тексты просто по букве. Допустим, мы сначала инициализируем эту сеть некоторой последовательностью, например, словом, и дальше хотим, чтобы на каждом следующем временном шаге она нам выплевывала просто букву, то есть какую следующую букву она хочет написать. Это статья в LaTeX, которая позволяет одновременно писать, то есть это такой язык программирования для написания статей по большому счету. Если натренировать сеть таким образом и позволить ей генерировать текст, то получаются осмысленные, по крайней мере, слова. То есть слова она не путает. Кажется, что даже синтаксис предложений тоже получается осмысленным. То есть у нас есть глагол, есть подлежащее, сказуемое в английском языке, но семантика этих предложений, то есть их смысл, не всегда присутствует. Вроде с точки зрения построения все выглядит хорошо, а смысла там бывает иногда немного. Но это очень простая модель, она генерирует по одному символу за проход. И, например, она еще даже пытается рисовать какие-то диаграммы здесь справа наверху. Так как язык разметки LaTeX позволяет не только писать, но и рисовать, то она пытается еще что-то рисовать.
Или, например, мы можем непосредственно генерировать исходный код программ. Эта сеть была обучена на исходном коде ядра операционной системы Linux, и мы можем видеть, что, кажется, она генерирует, по крайней мере, похожий на осмысленный код. То есть у нас есть, например, функции, есть разные условные выражения, циклы и так далее. Кажется, что это выглядит осмысленно. Скоро сети будут сами писать за нас программы, кажется, но, я думаю, что до этого еще далеко, и программисты будут нам еще нужны, не только сети.
Оказывается, что тренировать такие рекуррентные сети, если мы будем просто представлять их так слоями нейронов, достаточно сложно. Сложно потому, что они очень быстро забывают информацию о предыдущих объектах, которые мы им подавали до текущего. А иногда нам нужно, чтобы они помнили взаимосвязи между объектами, которые очень отдалены на расстоянии. Допустим, если мы себе представим «Войну и мир», чудесное произведение Льва Толстого, то там некоторые предложения занимают по несколько строчек. И я помню, что когда я их читал, то к концу предложения я уже забывал о том, что там было вначале. И такая же проблема наблюдается у рекуррентных сетей, они тоже забывают, что было в начале последовательности, а не хотелось бы. И для этого придумали более сложную архитектуру. Здесь важно то, что у нас в центре есть один нейрон, который подает свой выход себе же на вход. Мы вид
