PGConf.Russia #10 (2024)

Юбилейная 10-я конференция PGConf.Russia опередила юбилей компании (Postgres Professional исполнилось 9 лет). А самая первая — PGConf.Russia 2015 — даже опередила саму компанию-устроителя: конференция прошла в феврале, а официальный день рождения Postgres Professional 1 апреля 2015.
-10, +10
Гендир Postgres Professional Олег Бартунов вместо торжественной речи обратился с вопросом к залу:
поднимите руки те, кто участвовал в самой 1-й конференции. Таковых оказалось, мягко говоря, не слишком много. «Вот видите, вы очень ценные товарищи! — сказал Олег, — Запомните этот день и вспомните его через 10 лет! »
Выступление Ивана Панченко, зам гендира, оно же официальное открытие — тоже было коротенькое. Началось с исторической справки о 9 предыдущих PGConf.Russia. Я дополню его табличку некоторыми подробностями:
Для 1-й конференции — PGConf.Russia 2015 — в качестве места выбрали Digital October на стрелке Москвы реки в бывшем здании фабрики Красный Октябрь, недалеко от Петра. И сразу собрали 460 участников. Получилась на то время самая большая конференция сообщества. На открытии с приветственным словом выступил министр связи и массовых коммуникаций Н.А. Никифоров. Выступил там и уже покойный Саймон Ригс (Simon Riggs), тогда в качестве основателя компании 2nd Quadrant. Вообще иностранцев было много.
PGConf.Russia 2016. Решили попробовать Известия-холл. Золотым партнёром была компания Avito.
PGConf.Russia 2017 — снова Digital October. 60 докладов, 7 мастер-классов. Начиная с этой конференции я сам присутствовал на всех. Московская PGConf теперь не одна: появилась новосибирская PGConf.Сибирь 2017.
PGConf.Russia 2018. Экономфак МГУ. Digital October — симпатичное место, но чувствовался некоторый дискомфорт по поводу сервиса. Оказалось, что на Экономфаке организовать процессы проще.
PGConf.Russia 2019. Экономфак МГУ. Это опять самая большая постгресовая конференция в мире: 900 человек. В программе доклады по 90 минут и даже по 180. «Приглашаю присоединиться к увлекательному 3-часовому путешествию по хитрому миру отладки Postgres!» — анонсировал свой доклад Производительность и эксплуатация Postgres Джошуа Дрейк (Joshua D. Drake, Command Prompt). Позже от таких марафонов отказались.
PGConf.Russia 2020 — и в третий раз конференция проводится в стенах Экономического факультета МГУ, с приветственным словом выступает заместитель декана Экономического факультета МГУ им. М.В. Ломоносова — Александр Александрович Курдин. Появились блиц-доклады. Ковид ещё только задумался о путешествии по России. На этой конференции ещё есть 3-часовые мастер-классы.
PGConf.Russia 2021. Проходит в октябре в 1-м Меде — Первом МГМУ имени И.М. Сеченова. Разгар ковида, карантинные правила, а там можно организовать профессиональный контроль людей в белых халатах. 380 участников, 30 с лишним докладов. Долгий доклад (90 мин.) только один: Сергей Новиков (ЕДИНЫЙ ЦУПИС) рассказывает о Внедрении партицирования без простоя. Остальные — по 45 и 22 мин.
До этого в марте проходит PGConf.Online 2021. Кроме того 30 сентября проходит PGConf.NN в Нижнем, а 28 мая PGConf.VRN в Воронежском Государственном Университете.
PGConf.Russia 2022. Новое место — Рэдиссон Славянская на Площади Европы у Киевского вокзала. Проходит в июне в гибридном формате онлайн/оффлайн. Брюс Момджан делает виртуальный доклад Возможности PostgreSQL 15.
PGConf.Russia 2023. Там же. Приехал Крис Трейверс (Christopher Travers) в качестве независимого члена сообщества, делает 2 доклада — PostgreSQL vs Redis: Making the Right Choice и Crazy things you can do with PostgreSQL Indexes. А Брюс Момджан удалённо расширяет тему: Beyond Joins and Indexes. Вигнешваран Си (Vigneshwaran C, Fujitsu Consulting India) тоже делает виртуальный доклад — Logical replication internals. В графике пиджиконфов появляется PGConf.СПб 2023.
И вот — PGConf.Russia 2024 и снова в Рэдиссоне. 800 участников присутствуют физически, 600 виртуально.
Shardman и другие
Поскольку конференция проходила там же, где и в прошлом году, разница в количестве пришедших на неё чувствовалась: на этот раз и в конференцзал, и в залы «Пушкин-Толстой» и «Чехов», где протекали 3 потока, лучше было прийти заранее, чтобы слушать сидя. В фойе, где кофе и стенды, тоже было многолюдно. Во время некоторых докладов (Shardman и BiHA, например) преимущество было у рослых — проще заглядывать через плечи приближенных к докладчику.
Первым, как и в прошлом году, докладывал Павел Лузанов о новинках версии, только в прошлом году о 16-й, а в этом — о PostgreSQL 17. По результатам голосования занял 2-е место. Но я не буду здесь пересказывать доклад Павла — просто почитайте и послушайте в материалах конференции, если есть доступ в личный кабинет участников. А если нет, то вот набор ссылок на обзоры 2023–07, 2023–09, 2023–11 и 2024–01, из которых собрался этот итоговый.
В прошлом году я начинал с доклада Павла Конотопова Пять оттенков шардинга, вот и в этом хочется начать с Про-Shardman Алексея Борщёва и П. Конотопова (оба Postgres Professional). Алексей и Павел не разработчики шардмана, они его добросовестно, пристрастно тестируют. Ещё на позапрошлой конференции меня в докладе Алексея очаровала внимательность к нюансам. Поэтому не сомневаюсь, что при тестировании никакая пакость не ускользнёт. Этот доклад очень понравился публике (не знаю, почему не вошёл в лидеры по голосованию) не только технической основательностью, но и открытостью. Говорили: мы боялись, что это будет PR-доклад, а получился откровенный разговор о плюсах и минусах, о нюансах миграции.
Вопросы были о глобальных индексах. Вообще-то проблема не только шардированных баз, но секционированных (партицированных). Ответ — работа идёт. Она идёт и по читающим репликам. Пока таковые ещё нельзя организовать из-за некоторых аномалий чтения.
Алексей остановился подробней на проблеме внучек (цепочек до родительских таблиц, у правнучек и далее тоже проблемы). Она решается очень трудоёмко. И вообще: прозрачное шардирование — недостижимая мечта. Начните с вертикального масштабирования, а когда упрётесь в его ограничения, вот тогда можно переходить к горизонтальному. То есть к шардированию, — посоветовал Алексей.
Этот доклад был дополнен докладом Никиты Печёнкина, разработчика Postgres Professional — о том же, но с другого угла:
Консистентность в распределенных системах на базе PostgreSQL
Уж точно большинство читателей этой статьи знают о существовании уровней изоляции транзакций в СУБД, который возглавляет строгий SERIALIZABLE. Сооружение из прямоугольничков, отражающее уровни согласованности (консистентности) с учётом распределённости системах выглядит посложней:
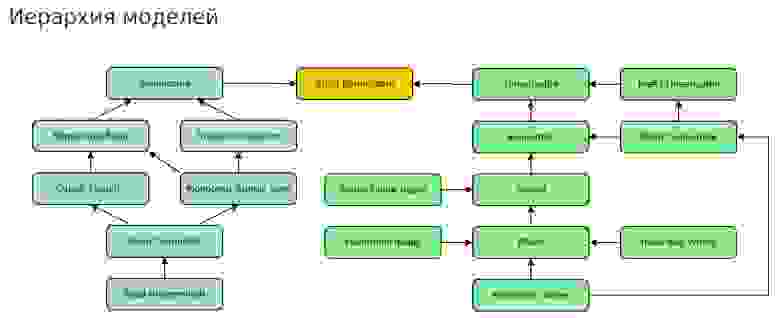
После впечатляющих схем и таблиц, Никита переходит к устройству Shardman. Он обеспечивает уровень изоляции Snapshot для любых распределенных транзакций. Для этого используются уникальные, глобально упорядоченные CSN (Commit Sequence Number) для снимков и коммитов. CSN — функция от времени. Перекосы времени — серьёзный источник аномалий. Никита рассказал о Jepsen-тестировании. Доклад Никиты вдохновлён прошлогодним докладом Павла Конотопова.
Оказывается, Fuzzing, о котором немного позже рассказывал Николай Шаплов — это тоже тестирование, особый его вид:
Fuzzing-исследование PostgreSQL. Как мы искали и что мы нашли
Николай Шаплов даже обозначен в докладе специфически: Postgres Professional, fuzzing engineer. Из аннотации: «Фаззинг-исследование, это когда мы подаем в программу (или её часть) случайные входные данные (на самом деле случайность весьма условна) и смотрим что из этого получится. И так много раз на многих процессорах.»

Николай рассказал о том, что такое SAF (Structure-Aware Fuzzing), как использовали btrfs, о том, как подменяли POSIX-вызовы и строили поддельную сетевую подсистему:
Что нужно для фаззинга сетевого соединения: подменить сетевой обмен на выхлоп фаззера; запустить PostgreSQL с сетевой подсистемой в один процесс; избавиться от backend«ов; не запускать worker«ы; восстанавливать контекст (содержимое БД) после каждого цикла фаззинга.
А что нашли? Баги. И некоторые направили в сообщество, например Bug in jsonb_in function (14 & 15 version are affected).
Новинки Postgres Professional составили увесистую долю докладов, но причина уважительная: действительно появилось за этот год много. Другие (не все) доклады о новинках Postgres Professional:
Управление планами запросов — новые возможности - Александр Котин, Postgres Professional, старший технический менеджер продукта. Он рассказал о том, как и для чего нужны AQO и AQE, sr_plan и pg_hint_plan, как их совместно использовать, а когда не стоит использовать (например, в 1С из-за временных таблиц и другой специфики).
Adaptive Query Executor (AQE/replan) перепланирует на лету, этот софт ещё не выложен, но это очень интересно, поэтому ещё и Борис Пищик (старший технический консультант Postgres Professional) делал демонстрацию в фойе, и был целый 40-минутный доклад Перепланирование безнадежных запросов в реальном времениразработчиковАлены Рыбакиной и Андрея Лепихова.
Александр Попов, инженер Postgres Professional, сделал 2 доклада:
pgpro_redefinition — расширение для онлайн манипуляций с большими таблицами — о новом расширении, которое позволяет перестраивать большую таблицу в секционированную таблицу без остановки приложения; разбить таблицу на несколько таблиц; добавить колонку со значением по умолчанию и даже создать копию таблицы на другом сервере СУБД. И второй доклад:
pgpro_rp — Приоритизация ресурсов — это о расширении, которое задаёт приоритеты 1, 2, 4 (по умолчанию), 8. Но кроме того можно создавать планы с заданным именем и параметрами и назначить план определённой роли.
PgRAP: Программа оценки здоровья и рисков PostgreSQL — Евгений Пажитнов, Postgres Professional, TAM. «Причину каждого инцидента мы классифицируем по трём направлениям: Технологии, Люди и Процессы. Доклад описывает наш опыт в части комплексного подхода к предотвращению сбоев СУБД.»
pg_profile: Отслеживание состояний сессий Андрей Зубков, Postgres Professional, руководитель группы систем мониторинга — довольно неожиданный доклад: Андрей сразу говорит, что о самом pg_profile (и pgpro_pwr) рассказывать на этот раз не будет, так как есть подробнейший полуторачасовой мастеркласс: Утилиты стратегического мониторинга pg_profile/pgpro_pwr. Архитектура, настройка, возможности. Он был на PGConf.Russia 2023. А этот доклад о новом механизме сбора информации об аномальных сессиях — о промежуточных снимках: take_subsample([server]). И, соответственно, о доступности исторической информации: о продолжительных транзакциях и запросах; об удерживаемых горизонтах транзакций; об общем количестве сессий, которые отслеживает pg_profile. Заметим, всё же, что pg_profile/pgpro_pwr ещё и обзавелись за это время интерфейсом Grafana.
Новые возможности pg_ProBackup 3.0 — Алексей Дарвин, Postgres Professional, менеджер продукта, Дарья Лепихова, Postgres Professional, разработчик.
По сравнению с временами pg_probackup 2 переход к 3-й версии это не эволюция, а революция — сказал Алексей. Для того, чтобы реализовать новые требования, нужно уже полностью переписывать предыдущую версию, развивающуюся с 2016 года. Решили, что лучше делать всё заново.
А что новое? Очень много: добавлен новый режим, в котором применяется новый репликационный протокол (добавлены свои команды в walsender); не требуется отдельная версия приложения под каждую версию БД; умеет работать как с PGPRO, так и с ванильным PostgreSQL; вместо копирования файлов 1:1, перешли к хранению в больших файлах; работа в многопоточном режиме на чтение и запись. И много другого.
Кроме того будет доступен полноценный SDK, поддерживающий C, C++ и GoLang. Добавлен бэкап на ленту. Включены все доработки и оптимизации работы с wal, cfs, Ptrack, S3 имеющиеся в версии 2.
К счастью, и «старый» pg_probackup (как и Pro Backup Enterprise) работает исправно:
Аварийное восстановление Postgres Pro Enterprise в Машине Баз Данных Скала^р при помощи pg_probackup — Александр Бурцев, Skala^p, руководитель продукта Машина Баз Данных и Алексей ВласовSkala-r, архитектор, рассказали об архитектурных решениях хранения резервных копий внутри Машины Базы Данных для Postgres (МБД.П). И сравнили этот вариант СРК с реализацией подключения МБД.П к Машине Хранения Данных (МХД.О) c S3-интерфейсом, сравнили производительности двух этих решений и их ограничения.
Избранные
В списке лучших докладов по зрительскому голосованию 6 позиций, всех в результате упомянем. Первая тройка: Алексей Семихатов, Павел Лузанов и Пётр Петров с докладом Инструменты диагностики и примеры оптимизации запросов. Пётр — ведущий инженер в группе производительности Postgres Professional, отличается необыкновенной обстоятельностью и тщательностью анализа. mamonsu, postgres_exporter, PPEM, 5 модулей для отслеживания долгих запросов, pgpro_stats, pg_profile и pgpro_pwr — много слайдов, огромное количество информации, анализ ошибок.
Вторая тройка: Сергей Новиков, Анатолий Анфиногенов, Илья и Фёдор Сазоновы — на этот раз без представителей Postgres Professional. Кстати, в прошлом году Анатолий в этом соревновании был вторым с докладом Вакуумотерапия: лечим хронические заболевания БД.
Оптимизация OLTP-нагрузки — Сергей Новиков представлял ЕДИНЫЙ ЦУПИС — одну из самых больших финтех-систем с миллионами платежей ежедневно и SLA 99.99%. Для мониторинга использовали малую часть набора Петра Петрова — pg_stat_statements и postgres_exporter (с кастомными запросами). Плюс VictoriaMetrics. Значительная часть доклада посвящена анализу поля n_distinct в pg_stats:
»Часто проблемы с запросами вызваны неправильной оценкой кардинальности. Когда кардинальность недооценена, мы получаем вечный nested loop. Вариант решения: Перепланирование в реальном времени.» То есть replan — см. выше. Переоцененная кардинальность — другая проблема. Ещё вариант решения:»оптимизация отключением оптимизации». И ещё несколько случаев из серии »бывает и такое».
Диапазонные типы в Postgres — доклад Анатолия Анфиногенова, ВНИИЖТ, замдир научного центра — начальник отдела разработки ПО). Вот приятные слова Анатолия:
»Postgres — это не упрощенная версия Oracle, как могло показаться некоторым в процессе миграции, а самобытная СУБД, заметно его превосходящая во многих вопросах. Поговорим о диапазонных типах — одном из бриллиантов в короне Postgres, про которые, как оказалось, знают далеко не все разработчики.»

Красивые слова подкрепляются примерами, применимыми к цифровой прогнозной макромодели движения поездопотоков ЭЛЬБРУС–М (2020). Обсуждаются и бесконечности, и версионности в Бирюлёве, и логические операции с (мульти)диапазонами. И Анатолий даже дружески попенял на отсутствие в книжке Егора Рогова PostgreSQL 15 изнутри рассмотрения GiST применительно к диапазонным типам (зато в его статье на хабре это есть). [UPD: Егор прокомментировал: Пара слов все же есть на с. 566.]
pg укротитель — не знаю, что/кто это, может быть это лично Илья Сазонов, Всегда Да, руководитель разработки, или Фёдор Сазонов, Сбер, руководитель направления. Я не был на этом докладе, а на сайте конференции нет, к сожалению, ни PDF, ни видео (так случается по желанию докладчика). Кажется, все остальные материалы доступны через личный кабинет.
Битва файловых систем
Два доклада были посвящены zfs/btrfs. Они были в разных залах, не одновременно, а подряд. Так что те, кто хотел послушать оба (а их было немало), просто переместились в другой зал.
Слоник который смог в ZFS - доклад Артема Свяжина, LLC SIMA-LAND, руководителя отдела системного инжиниринга был о развертывании тестовых и dev-контуров СУБД больших размеров за несколько секунд. Тут важен и контекст: Сима-Ленд, о которой я ничего не знал, крупнейшая оптовая компания России с суммарным объёмом данных 40TB+ на 100+ серверах Postgres, с 900+ микросервисов в контейнерах k8s, с 75К TPS на главной БД.
Секунды секундами, но рассказ был о «тернистом пути к ZFS». Из доклада следует, что пришли к необходимости не ZFS, а файловой системы с COW, а дальше выбирали из Btrfs и ZFS. Выбрали ZFS по нескольким критериям. Артём показал и схему — как у них всё теперь работает.
А вот Виктор Васильев, архитектор решений в Postgres Professional, рассказал о Btrfs:
Snapshot Standby с BTRFS в работе с PostgreSQL, хотя, по моим впечатлениям, в компании иметь дело с ZFS приходится чаще (см. например, Битвы на территории ZFS). В докладе было о функциональности этой файловой системы, об архитектурах с томами, подтомами и снимками, о том, для чего это было нужно. Для того, чтобы делать большое количество виртуальных машин из моментальных снимков, и чтобы это не съедало огромное количество ресурсов. И далее Виктор рассказывает, почему не подошли LVM и ZFS (один из недостатков ZFS в этом контексте — не входит в ядро Linux, а Btrfs входит). С Btrfs можно создавать каскад мгновенных снимков каталога PGDATA и запускать экземпляры СУБД на основе каждого снимка в режиме на запись, а потом быстро их удалять. Для погружения в тему Виктор советовал ознакомиться с докладом Томаша Вондры (Tomas Vondra) Postgres vs. Linux filesystems.
Похожие задачи, заметим, встречаются всё чаще. И напомним, что Btrfs выбирал Николай Шаплов для своих опытов с фаззингом.
Не только о технике
В этом разделе немного о докладах образовательных, научно-популярных. Или относящихся к сообществу, а не к его произведениям.
Доклады Павла Толмачёва и Андрея Бородина образовали пару: Павел в ответ на один из вопросов сказал:»я думаю, что лучше ответит Андрей Бородин, присутствующий в зале». И он ответил. Но у него был и свой доклад:
Как начать контрибьютить в Postgres: моя версия. Андрей Бородин - руководитель подразделения разработки РСУБД с открытым исходным кодом в Яндекс.Облако. В 40-минутном докладе он подробно расписывает действия тех, кто собрался что-то отправить в сообщество. Можно даже считать, что это не доклад, а целое руководство. Для начинающих это, как говорится, must.
И вот 1-й доклад из этой пары:
Историко-статистический взгляд на сообщество PostgreSQL — доклад Павла Толмачева, специалиста образовательного отдела Postgres Professional. Сама тема для меня была неожиданной: раньше Павел, например, делал высоко-технологичные исследовательские доклады по тонкостям работы оптимизатора. А здесь — история Слоника на лого. А дальше — Павел решил обработать статистику коммитфестов остроумным способом: вместо простеньких «кто больше строк закоммитил», он, например, проанализировал время и день недели, когда патчи появились. И этот анализ наглядно показал, что да, сообщество становится всё более профессиональным, энтузиасты играют не такую роль, как в начале пути Postgres, всё меньше коммитов в выходные, всё меньше по ночам. Это уже просто работа.
Зачем мне векторная база данных, если уже есть PostgreSQL? — Владлен Пополитов, разработчик, делал этот доклад вместе с гендиром Postgres Professional Олегом Бартуновым. Я поместил доклад в этот раздел потому, что популярная составляющая в нём была значительна. И даже как бы антипопулярная — дистанцирование от хайпа, а цель доклада, — сказал Олег, — демистификация GPT и векторных баз, которые, конечно, останутся, но как нишевые. Техническая сторона, которую излагал Владлен, касалась больше алгоритмов поиска соседей. Не только известных, но и будущих.
На этом докладе, который длился 1 ч. 8 м. вместо положенных 40 минут, был анонсирован новый метод доступа GUNN, то есть Generalised ANN (Approximate Nearest Neighbour). Планируются алгоритмы с поддержкой WHERE, многоколоночные индексы. Пока было решено ничего не выкладывать, но обещано, что всё со временем будет выложено в общий доступ.
Нам нужны ваши кейсы и ваши данные, — сказал Олег, — мы хотим поработать не с тестовыми данными, а с реальными.
Теперь к чисто просветительским докладам. Таковых было два. Доклад Современные методы искусственного интеллекта делал Иван Оселедец — гендир интересной организации AIRI, профессор Сколтеха. Кроме качественного ликбеза, был и разговор о собственных достижениях и успехах отечественных коллег, о том, что сейчас отрасль вошла в интересную фазу, когда уже не мощность суперкомпьютеров определяет передний край, а качество данных и архитектур. Я записал к себе в записную телефонную книжку такую фразу:
Студенты ведут себя как языковые модели :)
Что касается технологий text-to-SQL, то там новость: появление PAUQ (=Pioneer dAtaset for rUssian text-to-SQL). Он хороший. И вообще Иван — оптимист: он считает, что с развитием ИИ количество рабочих мест станет больше.
И, наконец, доклад, выигравший голосование этого года: Открытие Вселенной силой мысли — Алексей Семихатов, доктор физ-мат наук, ведущий передачи Вопрос науки на телеканале Наука.
Пересказывать доклад Алексея Семихатова — это пересказать прозой стихотворение. Алексей — блестящий рассказчик, артист в хорошем смысле. Все отведенные 60 минут (это исключение, остальные доклады официально до 40–45 минут) он держал в напряжении неожиданными поворотами этакого поединка между закономерным и случайным в науке, красивым и не очень, практикой и теорией. Приключения знания — так бы я назвал это для себя.
Этот доклад завершал первый день конференции. И он завершает этот обзор, который, разумеется, не претендует на полноту и даже объективность отображения PGConf.Russia 2024.
