LLMOps: не разрешают использовать ChatGPT. Что можно сделать?
Бывают ситуации, когда жизненные обстоятельства не позволяют использовать ChatGPT и приходится разворачивать LLM локально. Например бабушка не разрешает. Так можно остаться и без AI, а этого мужики точно не поймут. Есть ли какие-то способы решения этой проблемы?
Если у вас такая ситуация — можете выдохнуть, решение есть. На данный момент существуют следующие варианты:
1. Проприетарные модели:
a. Anthropic — в настоящее время сравним или превосходит по качеству ChatGPT 4.0 на некоторых задачах и обладает большим контекстным окном, давая возможность решать многие задачи, не прибегая к RAG и другим гибридным методам
b. Yandex GPT — хорошо функционирует на русском языке, поэтому если ваша бабушка еще и майор — она точно оценит этот вариант
c. GigaChat — модель от Сбера, так же хорошо работает на русском и смотри пункт выше
2. Открытые модели:
LLama 2 — оригинальная открытая модель от известной террористической организации, на базе которой уже нагородили over 100500 разных моделей, за что этой организации большое спасибо (до сих пор никто не понимает, что подвигло Марка на данное решение). По качеству не дотягивает до ChatGPT 4.
ruGPT — претрейн от GigaChat под лицензией MIT, Сбер приложил руку и тут, спасибо им. Можно использовать
Mistral — модель, разработанная выходцами из Гугла во Франции. Качество не дотягивает до ChatGPT 4, но в среднем лучше, чем Llama 2.
Falcon — модель разработана на арабские деньги европейцами. В целом, послабее Llama 2, и смысл ее использования от меня ускользает.
Grok от X — предположительно «based» модель от самого Илона. Работает пока так себе, плюс-минус на уровне ChatGPT 3.5, но Илон обещает порвать всех на тряпки и есть причины ему верить.
Оценки моделей на текущий момент выглядят примерно так (можно поглядеть тут):
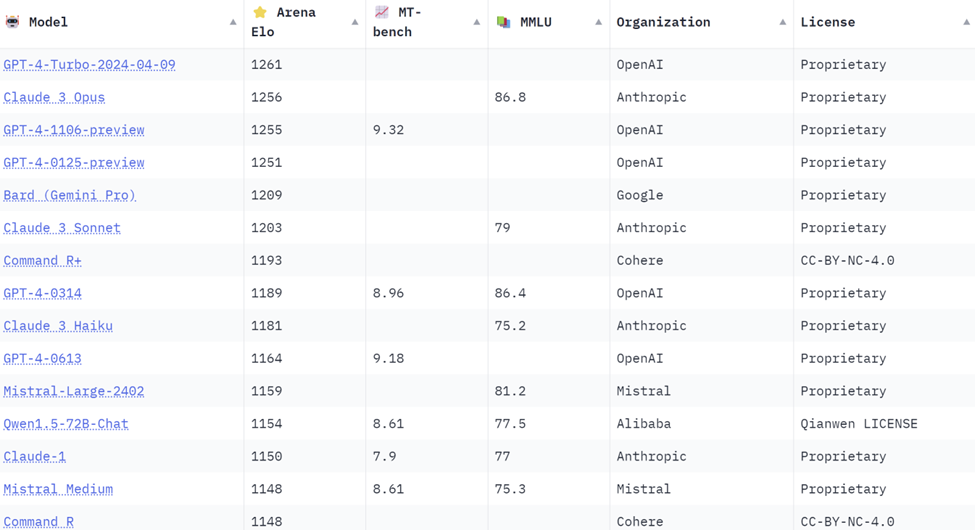
Наш опыт использования подтверждает, что модели от OpenAI и Anthropic превосходят остальные, и Anthropic даже немного выигрывает.
OnPrem
Что делать, если пользоваться облачными решениями невозможно (бабушка боится, что мошенники узнают, где спрятана заначка с пенсией). Тут два варианта:
развернуть у себя локально
Для этого потребуются видеокарты уровня NVidia A100, каждая стоит в районе $16 тыс.
Сколько их нужно, зависит от того, что вы будете делать. На обучение модели с нуля может потребоваться тысячи часов и соответственно большое количество видеокарт (и соответственно от десятков тысяч до миллионов долларов). Falcon 7B, например, была натренирована с помощью 400 A100s в течении двух недель. 7B Карл!
Для использования модели (инференс) — зависит от использования и количества одновременно подключенных пользователей. Допустим, вы хотите сделать чат-бот, который будет обслуживать 100 пользователей. Консервативно, количество графических процессоров, которое понадобится для размещения модели LLAMA 2 70B для 100 пользователей, зависит от объема памяти GPU. Точные требования к памяти зависят от спецификации модели, но один NVIDIA A100 с 80 ГБ VRAM может обслуживать пару экземпляров модели.
Для 100 одновременных пользователей нужно учитывать, что не все пользователи потребуют мгновенного ответа в одно и то же время, но система должна быть достаточно надежной для обработки высоких нагрузок.
Предположим, что один NVIDIA A100 80 ГБ может удобно запускать 2 экземпляра модели. Каждый экземпляр должен быть способен обслуживать несколько пользователей, в зависимости от того, как структурирован чат-бот и как управляются запросы пользователей.
Допустим, что один GPU может обслуживать до 25 одновременных пользователей (учитывая время ожидания и обработку). Таким образом, для 100 одновременных пользователей потребуется 4х GPU. Стоимость видеокарт будет примерно $65 тыс, не считая стоимости серверов, $75–90 тыс вместе со стоимостью сервера.
развернуть в дата-центре
Для примера возьмём Selectel. Один час работы сервера с конфигурацией, описанной выше (4хA100), обойдется примерно в 1200р в час. Неслабо, однако имеет смысл, если вы не собираетесь очень активно его использовать.
Оба сценария применимы в определенных ситуациях, тут нужно оценивать, что вы хотите получить на выходе.
Видеокарт нет, но вы держитесь (aka квантизация)
Если бабушка утверждает, что денег нет (а заначку вы еще не нашли), можно ли как-то сократить расходы? Да, можно использовать квантизацию. Это техника оптимизации, которая позволяет уменьшить объем памяти, необходимый для хранения и выполнения модели, и ускорить её вычисления, обычно с небольшим ухудшением качества. Это достигается за счёт уменьшения количества бит, которые используются для представления чисел в весах модели. Квантизация чаще всего включает в себя уменьшение точности данных от 32-битных чисел с плавающей запятой до 16-битных или 8-битных целых чисел. Как правило, качество падает не значительно, но нужно смотреть на ваших конкретных задачах. Это может снизить требования к железу в 2–4 раза, но нужно экспериментировать.
Это на самом деле очень большая тема и трудно описать все ньюансы в рамках одной статьи.
Ира, наш эксперт в этой области, скоро проводит вебинар по данной теме (совершенно бесплатно). Если интересно погрузиться в эту тему и задать вопросы эксперту — вот ссылка для регистрации.
Всем добра!
