Как мы побеждали бардак с железом и становились бюрократами с нуля

Разница между документацией и базой знаний: документация говорит, что это устройство охлаждает воздух до +18 градусов по Цельсию, а база знаний подсказывает, что есть редкий баг, когда два датчика сразу показывают -51 тысячу градусов и устройство начинает лихорадочно греть воздух для серверов.
Когда ты начинаешь новый маленький проект, то у тебя железка лежит на полу, нет документации, нифига вообще нет и можно работать работу. Потом проект вырастает до размеров нескольких сотен человек и тысяч железок, и тебе надо знать, где что точно лежит, как что делать и так далее.
Нужен нормальный учёт всего. Нужна документация. Не нужны ситуации, когда ты не знаешь, сколько и чего у тебя точно на складе. Не нужна история, что когда инженер заболел, остальные звонят ему домой и спрашивают, как он конфигурировал сервер год назад. Не нужна история, когда кто-то сказал поднять 10 серверов и два разных человека сделали это по-разному.
Но начали мы с простого. Вопросы были такими: Кто обновляет прошивку сервера? Кто отвечает за результат? Как это делается? Кого надо предупредить? Как писать план отката и что делать, если сервер упадёт? Кто-то записал все телефоны нужные заранее хотя бы?
В общем, первые же грабли вас или убьют к чертям, или научат делать всё правильно. У нас случилось второе и без граблей. Почти без граблей. Если у вас уже есть хаос, то наш опыт может оказаться полезным, потому что сейчас нам стало лучше.
Учёт железа
Самое первое и простое — это учитывать, где какое железо стоит и что делает. Нужно это для работы с изменениями, для инвентаризаций и для правильного бухгалтерского учёта. Например, сгорела планка памяти в сервере — надо завести инцидент у вендора и поменять её. Вендор сразу спросит, какой у планки FRU-номер. Номер планки написан на самой железяке, а также номер можно посмотреть в IMM (но только когда она работает). То есть если нет учёта, инженер пойдёт в машзал, выключит сервер, вынет эту планку (то есть все, потому что он не знает FRU, но знает DIMM) и, щуря глаза, скажет её номер.
Правильно было бы отсканировать все номера с самой планки и запустить сервер, либо после запуска сервера считать данные по планкам удаленно (рабочие можно посмотреть удалённо), чтобы быстро понимать, где именно сбойная память и какой у неё номер.
Ну и вообще хорошо бы понимать, что в каком сервере стоит, когда истекает гарантия, под какой проект используется, какая конфигурация и так далее. Когда серваков становится больше сотни, инфраструктурой уже сложно управлять без постоянно обновляемой карты. Не хочется оставлять это на носителей уникального знания вроде опытных эксплуатационников, на память знающих, что и где.
А ещё нужно иметь описанную сервисно-ресурсную модель, иметь какой-то ЗИП, понимать, что есть на случай инцидента. В случае нового клиента в той же закрытой под ПД ГИС части мы должны хорошо понимать, какое оборудование и какое количество лицензий есть, какими ресурсами располагаем, которые мы могли бы подключить.
Начали мы вот с таких карточек на каждый сервер:

Как видите, тут учтены все серийники, переписаны ТТХ железа и могут быть комментарии эксплуатационников по конкретным железякам. А ещё в карточке указано, когда началась и когда закончится поддержка, то есть можно настроить отчёты по этому — это полезно для планирования расходов.

А ещё в карточке написано, где это всё стоит и что воткнуто внутрь. Можно посмотреть вот такую иерархию:
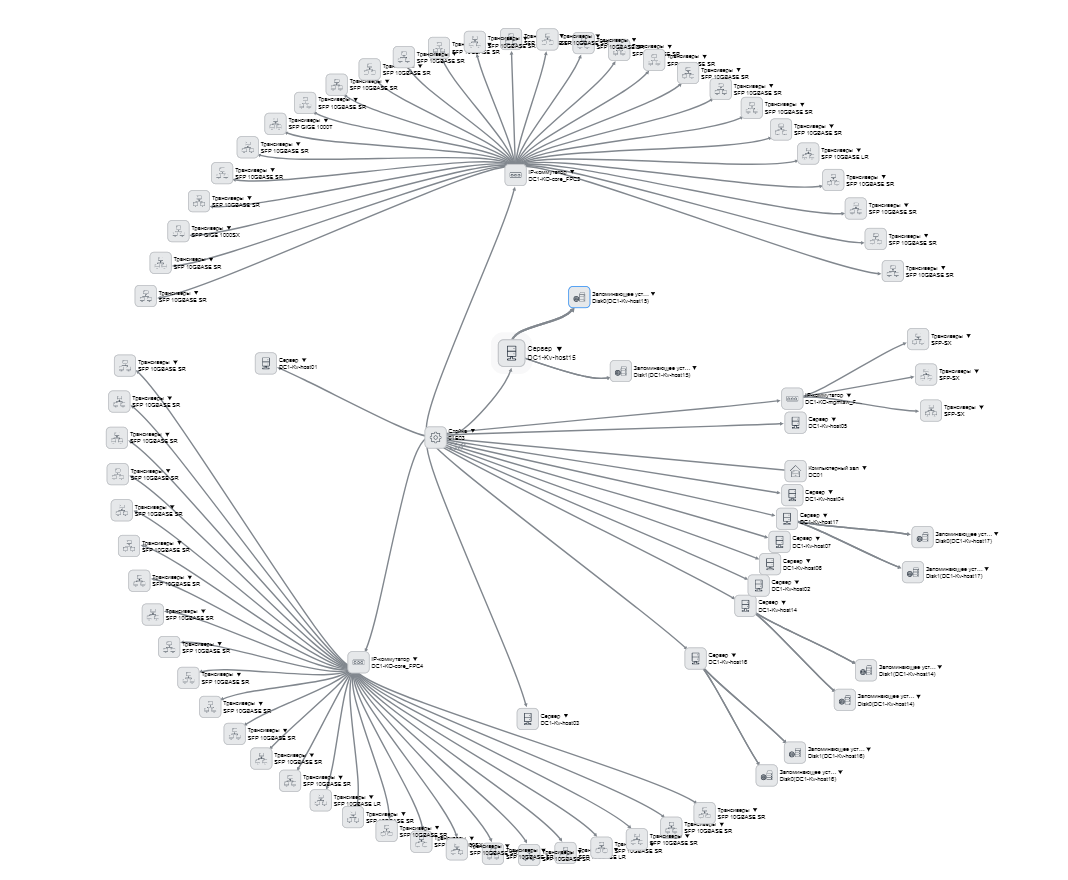
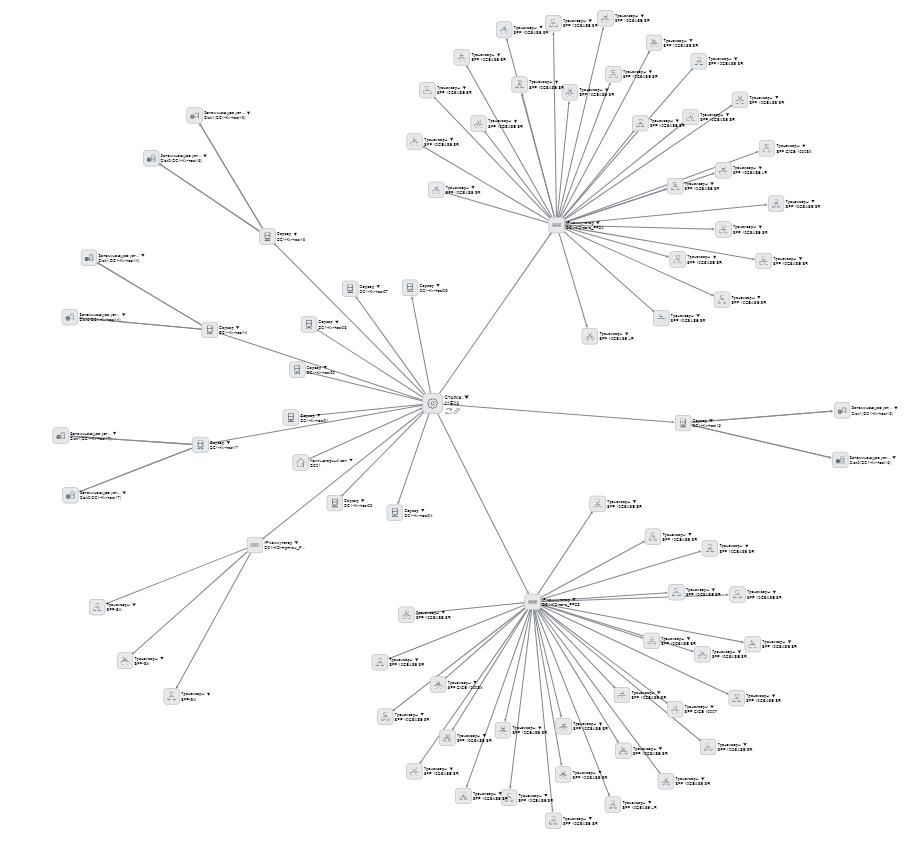
Карточки видны вот в таком списке:

Мы начали с серверов, потом пошли на коммутаторы, трансиверы, потом начали делать элементы СКС — сколько есть, где что стоит, как связано. Все серверы описаны — можно открыть любой, посмотреть, где стоит, в каком дата-центре, в каком зале, в какой стойке, в каком юните, что воткнуто, как подключено. Сделали связку с бухгалтерией с основными средствами — у них сервер учитывается как единица, а теперь мы знаем, какая карта и сетевые диски в нем установлены. Диски вообще одинаковые, отличаются серийниками, и где какой — до этого было неясно. А теперь к каждому привязан даже контракт, по которому он поставлен. Практическое удобство в том, что в бухгалтерии в одно основное средство входит большое количество оборудования, а у нас оно разнесено по стойкам, которые могут быть в разных залах, или вообще в ЗИП. Теперь мы при любом запросе (инвентаризации) бухгалтерии и клиента можем быстро найти все элементы основного средства.

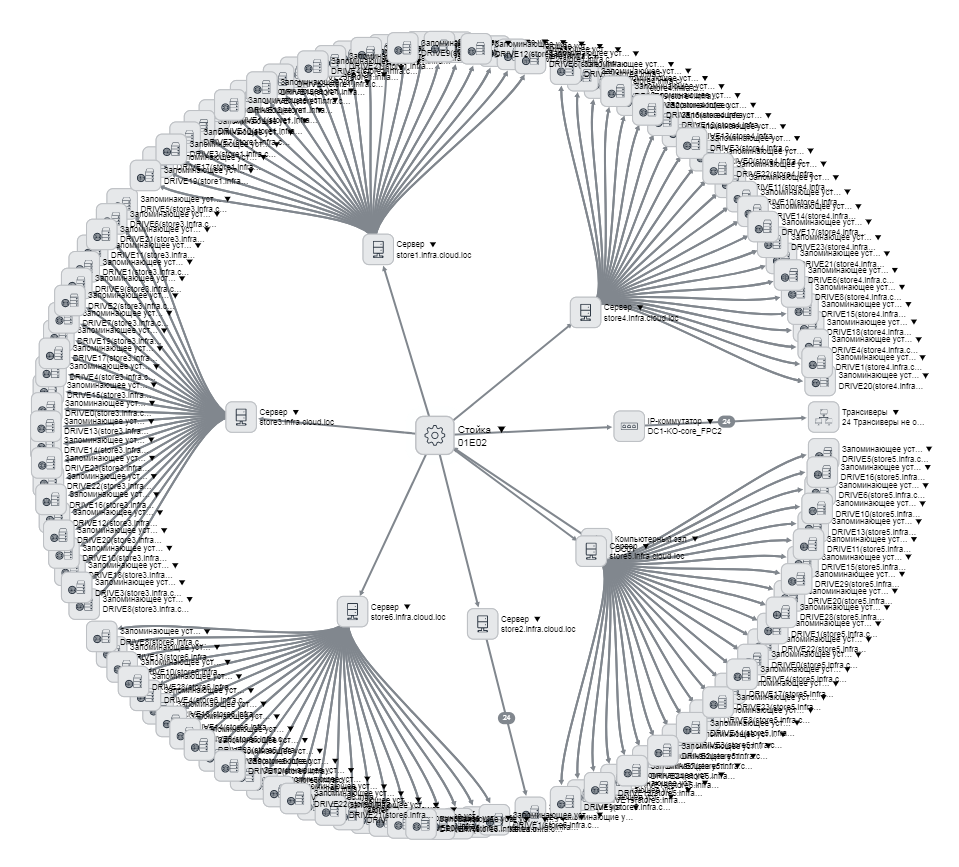
Пример карточки диска, мы про него знаем все
Теперь процессы
Когда с железом греющий душу порядок, для дальнейшего его поддержания надо начинать прописывать процессы. Например, заезжает банк в облако и под него надо добавить мощностей. Нужна постановка задачи с архитектурой и описанием для определения, что добавлять, куда добавлять, как настроить, как организовать сеть.
Раньше мы это обсуждали в почте, задача описывалась в таск-трекере, а потом, когда все договаривались, эксплуатация шла и делала.
Сейчас есть два типа процессов. Если изменения стандартные, то уже описаны все отдельные части процессов типа «выдели порт там-то» (в т.ч. план работ, план возврата, план тестирования, определены ли исполнители и т.д.), и каждая может встать в календарь изменений в ServiceNow. Поскольку процесс стандартный, согласований не надо, сразу назначаются ответственные, ставятся сроки, и всё это падает на конкретных исполнителей. На каждое изменение есть SLA, заявитель понимает, в какие сроки выполнят его задачу.
Пример — выделение портов. Порт можно выделить не везде. Первое — есть, к примеру, 100 коммутаторов, разные, у каждого по 48 портов. Портов 100×48, но это не значит, что любой можно выделить. Коммутаторы расположены в разных ЦОДах, залах. Нужно понимать, на каких можно выделить порты, на каких — нет. Согласно плану стандартного изменения, инженер знает, где и какие порты выделять, не выделит ранее зарезервированные. Второе — порт должен с чем-то взаимодействовать, соответственно, должны быть применены разные настройки (безопасность, скорость, ограничения полосы, настройка QOS и т.д.), всё это либо описано в запросе, либо указано в плане изменения. Третье — знаем, сколько у нас выделено, сколько зарезервировано, это очень полезно для последующего проектирования.
Если изменения нестандартные, то изменение после регистрации попадает на change-менеджера. Происходит проектирование, что и как, прорабатывается архитектура для реализации изменения, планы работ, оцениваются риски, планы отката, определяется время простоя, кого информировать, ответственные за работы, после чего всё отправляется на согласование… В общем, пишется та самая скриптовая последовательность со всеми вилками из прошлого пункта. Тот, кто это пишет, описывает риски (какие видит) и готовит план отката на каждый случай. После чего по процессу изменение попадает на комитет по изменению. Члены КАБа заранее определены для зон ответственности. Потом каждый участник смотрит план изменений и планы отката и согласовывает или нет. Если надо — доработка. Если надо — согласуются окна. После всех согласований ставятся задачи на исполнителей. Но на практике оказалось, что мы не такие большие. В боевой системе КАБ оставлен «на вырост» как сущность в системе, по факту — это руководители и/или архитекторы.
У каждого изменения есть change-менеджер (ответственный исполнитель), он отвечает за изменение, за всеми изменениями следит дежурная смена, отслеживает мониторинг и при нештатных ситуациях коммуницирует с заказчиками. Изменение закрывается только после того, как дежурная смена подтверждает работоспособность, change-менеджер проверяет согласно плану тестирования и обновляет CMDB и документацию.
Дело в том, что результат надо занести в документацию, а всё то, что было сделано во время изменения, отразить в базе активов. Элементарно обновить связность. Вот только после этого всё будет закрыто.
Вот такие процессы мы стали писать:
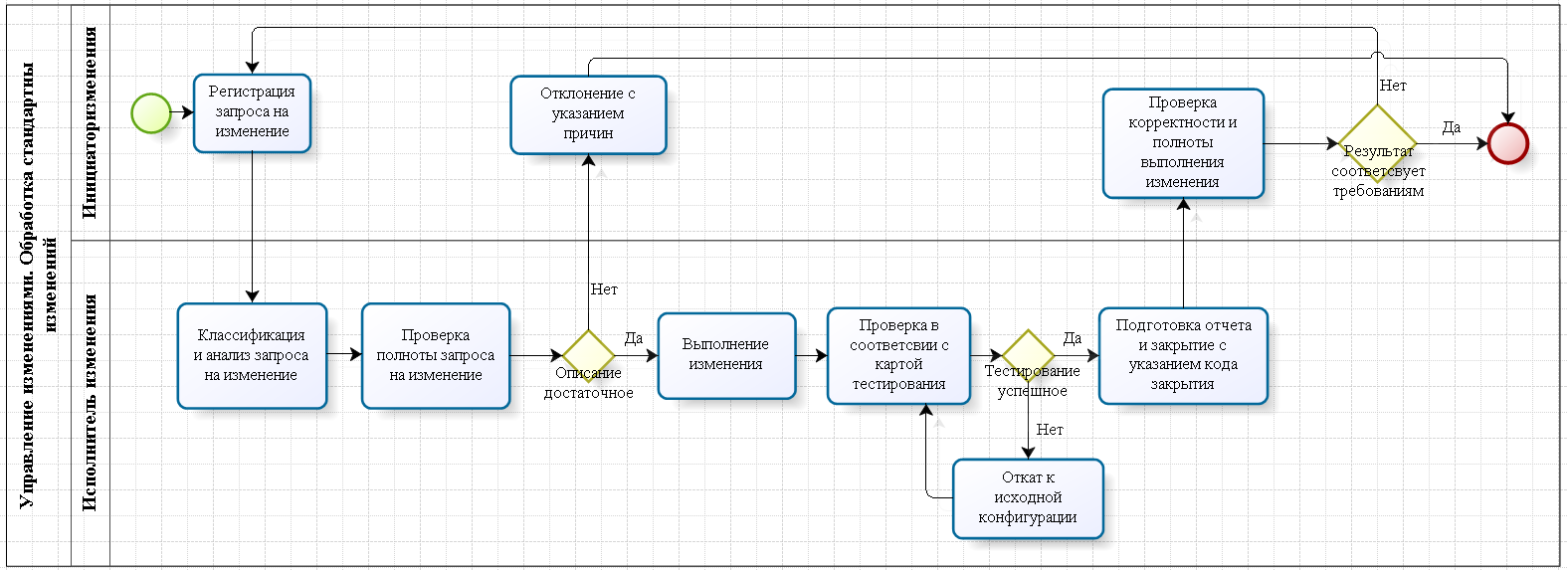
Разница с процессом и без — в том, что с процессом больше документации и бюрократии, но понятнее, что делать. Раньше кто как хотел, тот так и делал. Понятно, что пока людей мало, всё это держалось на неписаных стандартах. Выросли — понадобилось их записать, плюс без этого невозможно управлять большим количеством процессов. Появилась область ответственности. Появились разные SLA для разных случаев. Появилась обязанность готовить планы, предупреждать всех заинтересованных, а также согласовывать и документировать всё в конце. Дальше всё это автоматизировали в ITSM:
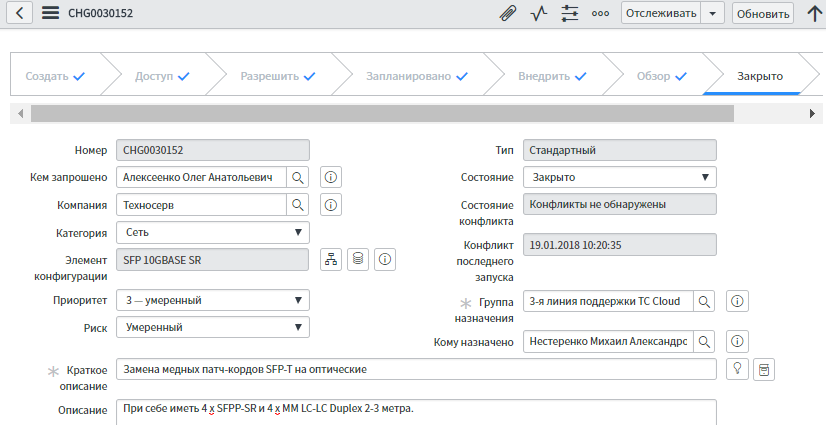
База знаний
Все работы в рамках изменений связаны с элементами конфигураций. Регистрируя изменение, мы знаем, что есть стандартизированный процесс: как работы должны выполняться, на каком оборудовании, и определён круг лиц — кто согласует, кто выполняет, кто что делает, если что-то идёт не по плану, и так далее.
Мы сразу видим риски, а в будущем — и стоимость работ.
Но этого мало.
Нужна база знаний, которая описывает то, что не описывает процесс. Например — редкий баг в прошивке. Или как лучше собирать стойку. Или как что подключать. Вот пример записи:
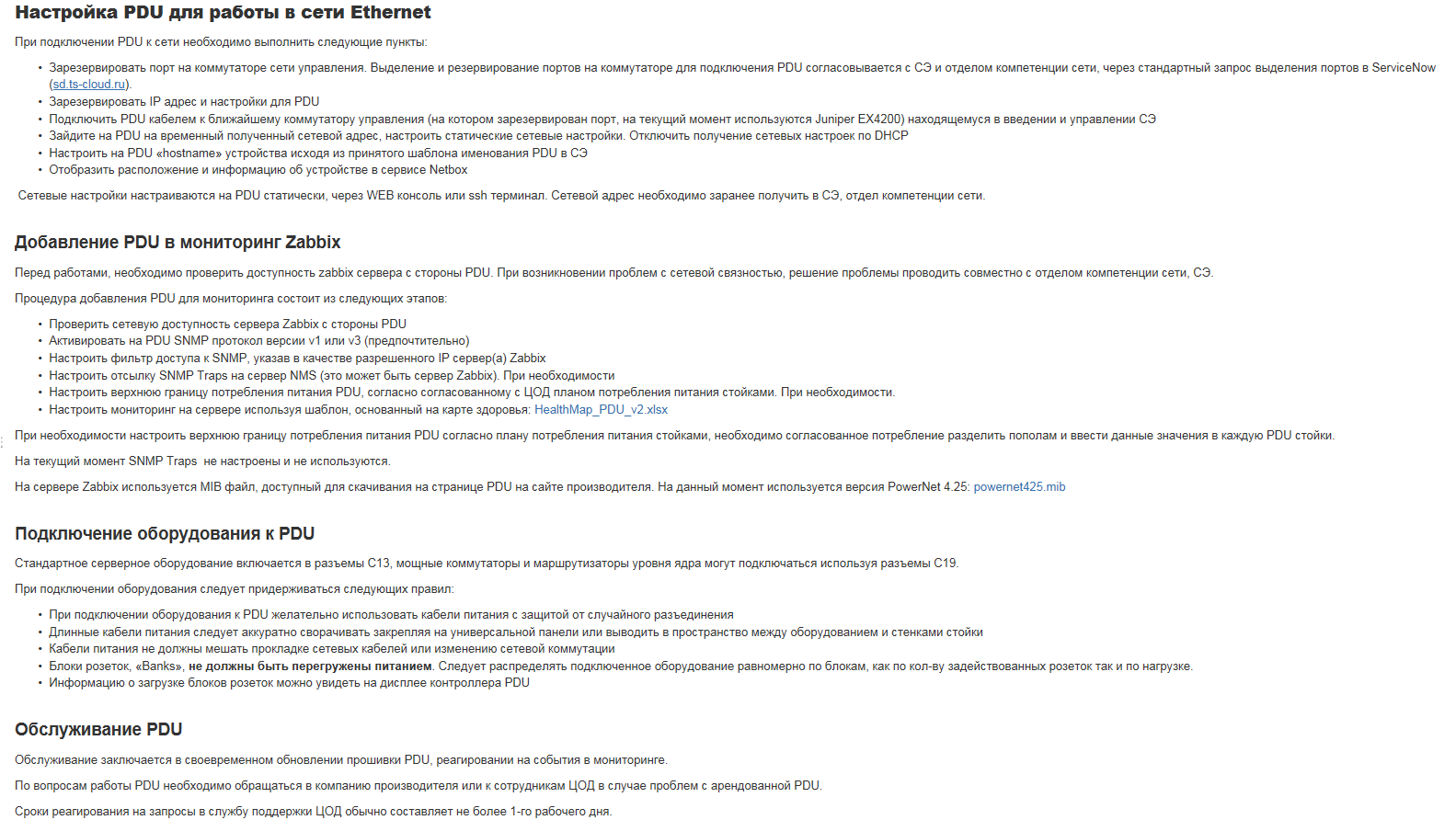
Это делается в основном из документов, которые пишет архитектор на стадии планирования. Но иногда инженеры и change-менеджеры добавляют что-то новое после выполнения работ.
Вы не представляете, какой кайф посмотреть на записи о железке и знать, что с ней делали и как до этого. А какой это будет кайф через 3–4 года — просто не передать.
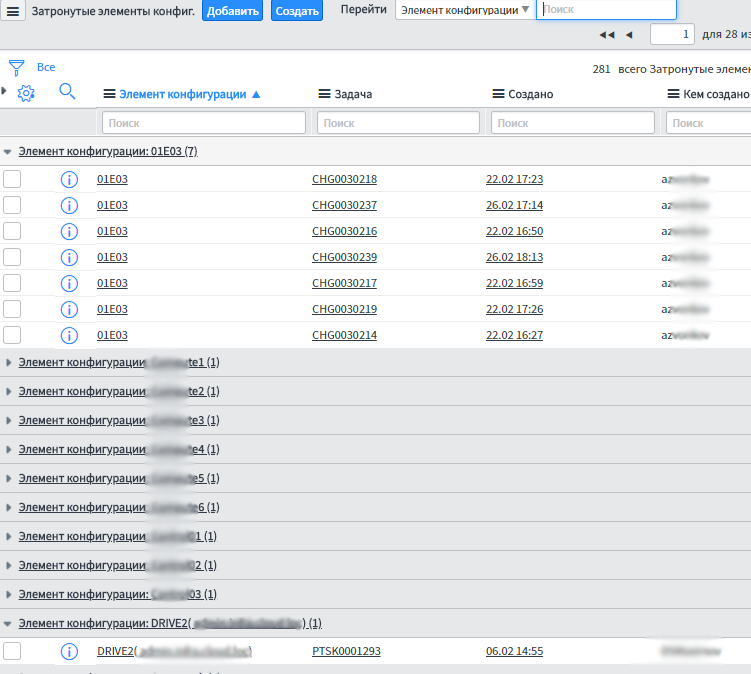
Склад
Следующая часть всей истории — это складское хранение. У нас это ЗИП, инструменты, упаковка от тестового оборудования. Всё это у нас хранилось прямо в кабинетах, где сидела дежурная смена, служба эксплуатации и архитекторы. Когда инженеры собирались на монтаж в ЦОД, то иногда ходили по кабинетам для сбора оборудования и расходников (пачкордов, трансиверов и пр.). Это ведёт к хаосу, а хаос крут только поначалу.
Опять же немного бюрократии — и вот у нас описан ЗИП (точнее, большая часть, ряд вещей всё ещё в состоянии «ящик с мелочовкой»). Есть адресное хранение в ПО, но пока склад не готов его внедрять организационно — у каждой штуки будут координаты в виде места на стеллаже. Когда инженеру ставится задача на монтаж, к заданию прикрепляется что-то вроде «возьми вот этот коммутатор там-то, вот эти SFP тут, вот эти пачкорды. Вот их стеллажи, полки».
Роли на изменения
Частично я уже описал управление изменениями. Ещё одна вещь в этой истории — это то, что у нас есть ролевое распределение:
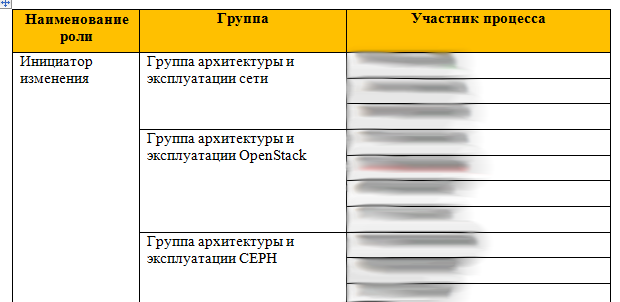
То есть если ты из сетевой группы VMWare, то заявку можешь подать только в зоне VMWare. У каждой роли есть список процессов, которая она может делать, и список задач, которые могут ставить её члены. То есть вся организационная структура компании тоже может быть занесена в ITSM.
Кто борется с хаосом?
Мы боремся всей командой, но отвечаю за результат я. Работы, кстати, ещё много. Должность у меня называется «руководитель программ». Это что-то вроде руководителя проектов с задачей ведения плана и списка взаимозависимых проектов, которые необходимо реализовать для достижения общей цели.
До этого я занимался тем, что наводил порядок в рознице, в частности, автоматизировал учёт и поставки в большой розничной сети магазинов для корректного учёта, снижения затрат на приёмку и учёт товара, сокращения времени подачи товара на полку. Могу сказать, что в ИТ-компании процесс изменений идёт в разы более гладко — все понимают, зачем это.
Когда стало понятно, что любой новый инженер может поднять документацию, поднять, как что делалось, прочитать логи настройщика (не только те, где кто-то позаботился о потомках по доброте душевной, а любые) и не собирать по частям от коллег байки, стало понятно, куда мы идём.
На старте не было ничего, и мы запустили с нескольких сторон работу. Полный результат пока не достигнут, но за полгода мы стали более понятными в работе с железом, процессами и изменениями. Облако развивается, и это его логичный шаг. Сразу так делать было не надо, но сейчас — самое время.
На днях вводим в тестовую эксплуатацию новый склад и продолжаем бороться с хаосом по другим векторам. Работы ещё до забора, но результаты видны всем. Если интересно, могу рассказать пару историй из розницы — там такие же проекты осложняются тем, что им, бывает, активно сопротивляются и конечные юзеры, и руководители других подразделений. Ну и плюс — всех надо учить, а у многих — побеждать мышление «мы и так нормально работали, не трогай».
Текст подготовлен Борисом Косолаповым, руководителем проектов по автоматизации Техносерв Cloud.
