[Перевод] Объяснение эффекта последней строки
Ключевые слова
Микроклоны, клоны кода, обнаружение клонов кода, эффект последней строки, психология, междисциплинарное исследование.
1 Введение
Разработчикам программ часто приходится дублировать одну строку кода несколько раз подряд с небольшими изменениями, как в следующем примере из проекта TrinityCore:
Пример 1
TrinityCore

Пространственные координаты объекта other прибавляются к полям, соответствующим координатам x, y, z, но в последней строке этого фрагмента из трех однотипных строк содержится ошибка: y-координата прибавляется к z-координате. На самом деле последняя строка должна выглядеть так:

Следующий пример взят из популярного веб-браузера Chromium и демонстрирует проявление рассматриваемого эффекта в однотипных инструкциях в пределах одной строки:
Пример 2
Chromium
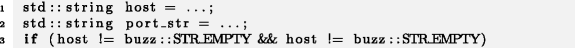
Вместо двойной проверки хоста (host) на равенство пустой строке вторая проверка должна выполняться для port_str:
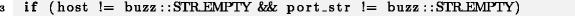
Строки 1–3 из примера 1 похожи между собой, так же как и условия if-оператора в строке 3 примера 2. Такие исключительно короткие блоки кода, состоящие из почти идентичных повторяющихся строк или инструкций, мы будем называть микроклонами. Наш собственный опыт в разработке и консультировании по вопросам качества ПО подсказывал нам на интуитивном уровне, что последняя строка или инструкция в микроклоне с гораздо большей вероятностью содержит ошибку, чем предыдущие строки или инструкции. Цель этой работы состоит в проверке истинности нашего ощущения, и именно этой целью обусловлены два вопроса, поставленные в рамках настоящего исследования:
- RQ 1 Верно ли, что последняя строка в микроклоне из нескольких строк с большей вероятностью будет содержать ошибку?
- RQ 2 Верно ли, что последняя инструкция в микроклоне длиной в одну строку с большей вероятностью будет содержать ошибку?
Поскольку копирование блоков кода при написании программ применяется в большинстве языков программирования, эффекту последней строки может быть подвержен практически каждый разработчик. Если нам удастся доказать, что последняя из нескольких идущих подряд однотипных инструкций больше подвержена ошибке, авторы и инспекторы кода будут знать, каким участкам следует уделять особое внимание, что поможет повысить качество программы за счет сокращения количества ошибок.
Копирование и вставка — один из естественных способов создания кода, подобного примерам 1 и 2. Проведя работу по определению происхождения кода среди дубликатов в отобранных нами примерах, мы пришли к выводу, что разработчики пользуются целым рядом механических приемов их создания, из которых самыми важными являются построчное копирование-вставка и «клонирование» участков кода. Эти методы — одни из самых распространенных идиом программирования (Kim и др. 2004), они требуют минимальных физических и временных затрат, а потому дешевы; кроме того, известно, что такой код работоспособен. Хотя копирование малых участков кода часто рассматривается как вредный прием (Kapser and Godfrey 2008), иногда это единственный способ, позволяющий реализовать желаемое поведение программы, как в рассмотренных выше примерах. Было разработано несколько инструментов для обнаружения и, по возможности, устранения микроклонов (Bellon и др. 2007; Roy и др. 2009). Несмотря на то что эти инструменты продемонстрировали впечатляющие результаты вплоть до уровня методов, они плохо приспособлены для распознавания микроклонов на практике из-за слишком большого количества ложных срабатываний.
После того как мы опубликовали статью об эффекте последней строки в научно-популярном блоге, ее быстро и с большим энтузиазмом стали цитировать на других форумах. Многие программисты соглашались с нашими наблюдениями и высказывали предположение, что за обсуждаемым эффектом стоят психологические причины. Отсюда проистекает наш третий, и последний, вопрос в рамках настоящего исследования:
- RQ 3 Каковы причины существования дефектных микроклонов вообще и эффекта последней строки в частности?
Опираясь на результаты опросов разработчиков, тщательного технического анализа примеров и сотрудничества с психологом, мы попытаемся выяснить, влияют ли психологические аспекты — и если да, то какие — на проявление эффекта последней строки. Изучив явления, давно наблюдаемые когнитивной психологией, мы выясним, можно ли с их помощью объяснить эффект последней строки в микроклонах кода.
Взяв за основу проведенное нами ранее исследование эффекта последней строки (Beller и др. 2015), мы внесли в него следующие дополнения:
- Ввели термин «микроклон» и дали ему определение.
- Представили используемые автоматическим инструментом статического анализа (Beller 2016) PVS-Studio диагностики для обнаружения дефектных микроклонов, которые не могут быть обнаружены традиционными способами.
- Отдельно изучили каждую ошибку во всех 263 микроклонах, отобранных из 219 популярных открытых проектов на основе 1 891 предупреждении анализатора.
- Провели предварительный анализ психологических механизмов, лежащих в основе эффекта последней строки.
- Опросили шестерых разработчиков реальных проектов, допускавших ошибки в микроклонах.
- Изучили репозитории четырех популярных открытых проектов по результатам опросов, которые указали на связь ошибок с аномально большими размерами коммитов.
Наши наблюдения показывают, что последняя строка или инструкция в микроклонах, подобных тем, что представлены в примерах 1 и 2, с гораздо большей вероятностью содержат ошибку, чем любые из предшествующих строк или инструкций. Нам представляется, что существование этого явления обусловлено не технической сложностью микроклонов, а психологическими причинами, которые, в свою очередь, в основном сводятся к перегрузке кратковременной памяти программистов. Предварительное исследование на базе пяти проектов выявило, что все микроклоны с ошибками были написаны в аномально больших коммитах в нестандартное рабочее время. Знание этих особенностей и помощь нашего автоматизированного статического анализатора PVS-Studio могут способствовать сокращению количества тривиальных ошибок, связанных с эффектом последней строки, за счет автоматического их обнаружения.
2 План исследования
Наша работа состоит из двух частей: эмпирических исследований C1 и C2. В данном разделе мы опишем порядок проведения исследований и их объекты.
2.1 План исследования C1: распространенность и преобладание эффекта последней строки в микроклонах
В исследовании C1, состоящем из пяти легко воспроизводимых этапов, мы провели статистический анализ распространенности эффекта последней строки в микроклонах. Более того, в попытке пролить свет на процесс создания микроклонов мы проделали дополнительную работу по выявлению оригинальных участков кода и их копий.
- Провести статический анализ объектов исследования с помощью инструмента PVS-Studio со всеми включенными диагностиками. PVS-Studio — это коммерческий статический анализатор, разработанный российской компанией «ООО Системы Программной Верификации» и включающий в себя десятки диагностических правил — от обнаружения клонированных блоков кода до антипаттернов программирования, использующих специфические библиотечные функции языка C. Желающие воспроизвести наше исследование могут воспользоваться находящейся в открытом доступе бесплатной демонстрационной версией PVS-Studio.
- Изучить отчет PVS-Studio и удалить ложные срабатывания, а также сообщения, не относящиеся к микроклонам.
- Для каждого дефектного микроклона подсчитать общее количество строк кода (RQ 1) или инструкций (RQ 2) и указать, в каких строках или инструкциях появляется ошибка. Если возможно, определить оригинальный участок кода и его копию (так, в примере 6 оригиналом является строка 2, а копией — строка 3).
- Приступая к исследованию, мы по умолчанию исходим из предположения, что в дефектном микроклоне длиной n строк вероятность ошибки для каждой строки равна 1/n независимо от ее номера внутри рассматриваемого фрагмента (нулевая гипотеза H0). Например, строки 1 и 2 в блоке из 2 строк имеют одинаковую вероятность ошибки 0,5. Однако, если на этапе (3) удастся показать, что распределение ошибок по строкам существенно отличается от равномерного распределения с уровнем значимости
, мы откажемся от нулевой гипотезы и примем, что ошибки распределены неравномерно. Для каждой длины n строк используется критерий согласия Пирсона
со степенью свободы n — 1 для установления соответствия между наблюдаемыми данными и нулевой гипотезой (распределение 1/n).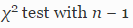
- Если на этапе (4) будет обнаружено значительное расхождение между предполагаемым и реальным распределениями, мы подсчитаем соотношение шансов между ними в качестве интуитивной меры интенсивности проявления эффекта последней строки (Bland and Altman (2000)).
2.2 План исследования C2: анализ причин эффекта последней строки
Установив существование эффекта последней строки в исследовании C1, мы должны теперь попытаться выявить обуславливающие его причины (RQ 3). Для этого мы разработали начальную гипотезу, основываясь на результатах исследований в области когнитивной психологии, в чем нам помогал профессор когнитивной психологии Рольф Цваан. Для подтверждения нашей гипотезы, а также для сбора свидетельств из практики разработчиков мы опросили программистов, ответственных за создание микроклонов, обнаруженных в ходе исследования C1. Их замечания и наблюдения помогут нам разработать предварительную версию, объясняющую существование эффекта последней строки. Сужение круга опрашиваемых исключительно до лиц, чье авторство в отношении дефектных микроклонов точно установлено, позволяет нам: (1) сосредоточиться на конкретных примерах, к которым опрашиваемые имеют непосредственное отношение; (2) получить максимально полезные ответы, поскольку мы знаем наверняка, что именно эти разработчики были ответственны за написание обсуждаемых микроклонов.
На рис. 1 показан общий план нашего исследования. Основная задача состоит в том, чтобы установить контакт с авторами микроклонов (во многих случаях дефектный код отсутствует в последней версии проекта). План включает в себя четыре основных этапа:
- Проекты и примеры микроклонов отбираются случайным образом, поскольку работа над исследованием C2 — трудоемкий процесс, подразумевающий установление контакта с авторами примеров и проведение индивидуальных опросов. Исходя из того что стандартная доля отвечающих на «холодные звонки» составляет 30%, мы можем рассчитывать на три успешных опроса, которые должны дать нам достаточно информации, чтобы сформулировать начальную гипотезу, объясняющую существование эффекта последней строки с точки зрения когнитивной психологии. При анализе каждого из микроклонов необходимо ознакомиться с принятыми в данном проекте правилами разработки и изучить репозиторий.
- Далее, мы определяем местоположение микроклона в дереве исходного кода проекта. Поскольку многие из ошибок были исправлены после публикации наших более ранних наблюдений и в текущей ветке отсутствуют, на этом этапе мы вынуждены применять различные стратегии поиска. Сначала мы изучаем репозиторий, датирующийся тем днем, когда проводилось исследование C1. В случае неудачи — например, если соседний с микроклоном код подвергся рефакторингу (или история изменений была перезаписана) — мы используем поиск по баг-трекеру проекта, чтобы найти коммит, в котором было внесено исправление. Если и этот шаг не приносит результата, мы прибегаем к полнотекстовому поиску (используя инструмент ag) по всем коммитам проекта.
- При обнаружении оригинального микроклона мы прослеживаем его историю с помощью инструмента git blame, чтобы получить сведения о внесенных исправлениях, а также установить авторство этого кода.
- Наконец, мы узнаем электронный адрес разработчика, используя команду git blame -e. Чтобы добиться более высокого процента ответивших, мы собираем дополнительные сведения о респондентах с помощью поиска в Интернете: это позволит нам определить актуальность адреса электронной почты. Чтобы добиться максимально честных ответов, мы гарантируем респондентам, что не будем раскрывать их личные данные. Затем мы посылаем каждому разработчику электронное письмо с текстом микроклона их авторства, историей его изменения/исправления, контекстом ошибки, а также объяснением причины проведения опроса и прилагаем анкету.
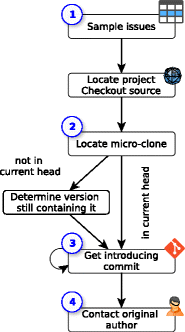
Рис. 1 — План исследования C2
2.3 Объекты исследования
Чтобы облегчить воспроизведение нашей работы другими исследователями, мы отдали предпочтение хорошо известным проектам с открытым кодом. Среди 219 проектов, изученных нами в исследовании C1, ошибочные микроклоны были обнаружены в таких знаменитых проектах как аудиоредактор Audacity (1 пример), веб-браузеры Chromium (9) и Firefox (9), XML-библиотека libxml (1), базы данных MySQL (1) и MongoDB (1), компилятор языка C clang (14), FPS-шутеры Quake III (3) и Unreal 4 (25), пакет для создания компьютерной графики Blender (4), программа для трехмерного моделирования и визуализации VTK (8), сетевые протоколы Samba (4) и OpenSSL (2), видеоредактор VirtualDub (3), а также язык программирования PHP (1). Для исследования C2 мы отобрали 10 микроклонов из проектов Chromium, libjingle, Mesa 3D и LibreOffice.
2.4 Замечания по воспроизведению исследования
Для облегчения работы других исследователей мы подготовили специальный пакет, куда вошли все исходные данные и диагностики. В него включены все неотфильтрованные сообщения PVS-Studio, сгруппированные по двум директориям: findings_old/, где содержатся старые данные, использованные в нашей статье для Международной конференции по обозримости программ (ICPC) (Beller и др. 2015), и findings_new/ с более свежими данными, использованными в настоящей статье. Кроме того, в пакет входят проанализированные нами и отсортированные по проектам микроклоны (analyzed_data.csv), электронная таблица с оценкой данных (evaluation.ods) и результаты анализа репозиториев из исследований C1 и C2. Мы также добавили скрипты на языке R для воспроизведения результатов и диаграмм из данной статьи. Наконец, в пакете содержится шаблон анкеты с вопросами для респондентов.
3 Способы обнаружения микроклонов
В данном разделе мы рассмотрим традиционные способы обнаружения дублированных фрагментов кода, объясним, почему они не подходят для поиска микроклонов, и покажем, каким образом мы смогли обойти эту проблему, используя наши собственные диагностики статического анализа. Кроме того, мы покажем, как определялись оригинальные участки и копии в микроклонах и как учитывались размеры коммитов.
3.1 Почему современные инструменты обнаружения клонов кода не подходят для нашей задачи
Как показывают примеры 1 и 2, фрагменты кода, рассматриваемые в рамках этой статьи, либо полностью совпадают по тексту, либо содержат «клоны с одинаковой синтаксической структурой, отличающиеся только идентификаторами переменных, типов или функций» (Koschke 2007). По этой причине они представляют собой клоны 1 или 2 типа чрезвычайно малого размера (как правило, меньше 5 строк/инструкций) — именно их мы и называем микроклонами.
Традиционные методы обнаружения дублированного кода заключаются в сравнении токенов, строк кода, узлов абстрактного синтаксического дерева (АСД) или графов (Koschke 2007). Однако на практике в любом из этих подходов требуется определить минимальный размер клона в условных единицах измерения (будь то токены, инструкции, строки или узлы АСД) для снижения процента ложных срабатываний. Как правило, это значение берется в районе 5–10 единиц (Bellon и др. 2007; Juergens и др. 2009), что намного превосходит размер рассматриваемых нами микроклонов (2–5 единиц) и делает невозможным их поиск.
Так, в примере 1 строки 1–3 представляют собой класс микроклонов. Поскольку строк три, то данный класс представлен в этом примере в трех экземплярах. В свою очередь, каждый экземпляр состоит из переменной, операции присваивания, присваиваемого объекта и его поля и, таким образом, имеет длину 4 единицы.
3.2 Используемые нами методы обнаружения дефектных микроклонов
Поскольку на практике традиционные методы поиска неспособны надежно обнаруживать микроклоны, мы использовали свой собственный подход. Наша задача состоит в обнаружении не любых микроклонов, а только тех, которые содержат ошибки. Учитывая это дополнительное ограничение, мы смогли разработать целый набор мощных диагностик, обнаруживающих микроклоны по признаку обычного посимвольного совпадения. Эти диагностики способны находить дефектные участки кода, которые с большой вероятностью появились в результате копирования малых фрагментов. В табл. 1 перечислены и описаны все двенадцать диагностик, которые позволили обнаружить ошибки в микроклонах в рамках этого исследования. В последнем столбце показано отношение числа одно- и многострочных клонов к общему количеству предупреждений данного типа. Например, диагностика V501 всего лишь определяет, являются ли идентичными операнды некоторых логических операторов. Если ответ положительный, то в лучшем случае это просто лишний код, который может затруднить поддержку программы в будущем, в худшем — настоящая ошибка. Другие диагностики не настолько узкоспециализированы по отношению к микроклонам, как V501. Мы изучили каждое из 526 предупреждений и отобрали для нашего исследования только 272 случая реальных микроклонов. Из табл. 1 можно также увидеть, что 78% микроклонов были обнаружены одной диагностикой (V501) с очень низким процентом ложных срабатываний — 3%. Другие диагностики с большей вероятностью могут срабатывать на участки кода, не являющиеся микроклонами.
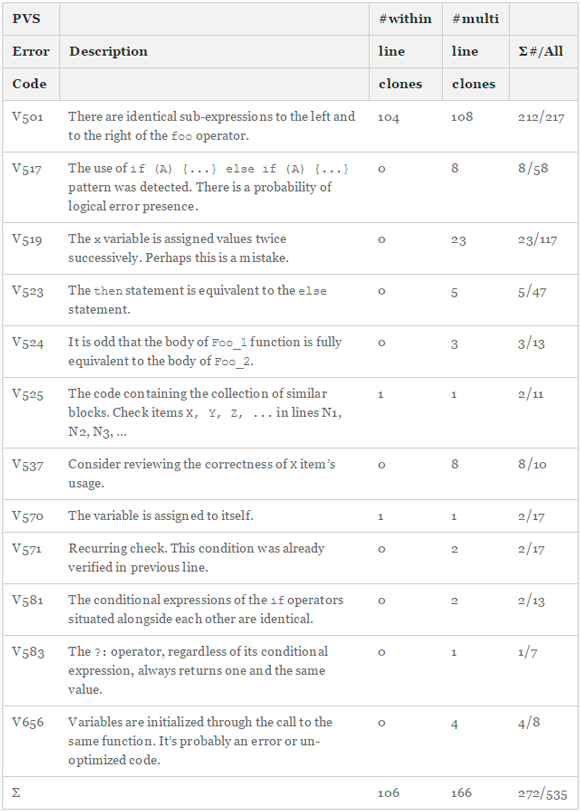
Таблица 1 — Типы ошибок, обнаруживаемых PVS-Studio, и их распределение по 219 открытым проектам
3.3 Как устанавливалось происхождение ошибочных микроклонов
Чтобы компетентно рассуждать о причинах существования эффекта последней строки, отвечая на вопрос RQ 3, мы также нашли в каждом классе микроклонов оригинальный экземпляр кода и экземпляр, который предположительно был скопирован с него. Хотя подобный эмпирический анализ не дает стопроцентную уверенность, что процедура копирования шла именно в таком направлении, у нас имеются достаточные свидетельства, что по крайней мере некоторые разработчики механически клонируют код именно таким образом (см. RQ 3). В большинстве случаев можно сразу определить, какой из двух экземпляров микроклона является оригиналом, а какой — копией. Так, в примере 1 строка 3, содержащая ошибку, включает в себя следы кода из строки 2, что подразумевает влияние строки 2 (оригинал) на строку 3 (копия). Подобный естественный порядок следования оригинальных строк и копий наблюдается в большинстве микроклонов — будь то лексикографический порядок, как, например, в последовательности переменных x, y, z в примере 1, или числовой:
Пример 3
Cmake

Даже в тех случаях, где естественный порядок расположения оригинального экземпляра и копии не выражен явно, как в примерах 1 и 3, его можно восстановить по контексту, как в примере 2: помещение port_str на первое место и host на второе в строке 3 противоречит порядку, в котором эти переменные были определены ранее, — значит, первая инструкция host!= buzz: STR_EMPTY является оригиналом, а вторая — копией.
В процессе установления происхождения копии в рассматриваемых примерах мы сталкиваемся с двумя проблемами, а именно: 1) размер копируемого участка может варьировать; 2) микроклоны длиной свыше 4 дубликатов представлены меньшим числом примеров. Чтобы, тем не менее, иметь возможность обобщить данные для разных размеров микроклонов, для каждого микроклона i мы вычисляем


Степень удаленности 1 говорит о копировании из непосредственно предшествующей строки/инструкции, как в примере 4. Значение 0: ошибка произошла в той же строке микроклона. Значение -1 указывает на обратный порядок копирования: из второй единцы — в первую:
Пример 4
UnrealEngine4

В этом примере в строке 1 естественно ожидать cx ().isRelative вместо cy ().isRelative, что говорит о возможном копировании из второй строки. Логика использования переменных с подобными именами, а также порядок следования строк 3 и 4 говорят о том, что копия должна начинаться с return cx ().isRelative () в первой строке.
Отсюда получаем степень удаленности


3.4 Как учитываются размеры коммитов
Чтобы вычислить и представить отношение размеров каждого из коммитов, содержащих дефектные микроклоны, к остальным коммитам, мы вначале вычисляем изменчивость для каждого коммита в репозитории. Для этого мы используем инструмент git log, который позволяет строить упорядоченные графы всех коммитов (исключая слияния) в репозитории, выявляя, таким образом, число добавленных и число удаленных строк кода в каждом коммите. Сумма этих чисел и дает общее количество измененных строк, т.е. величину изменчивости, для каждого коммита. Затем мы сравниваем изменчивость коммитов, содержащих дефектные микроклоны, с распределением этого параметра в остальных коммитах, а в особенности — с его медианой. Хотя наша выборка (десять примеров) слишком мала для надежного статистического анализа, этот подход все же позволяет нам сделать обоснованные выводы о возможной разнице в размерах коммитов. Мы используем медиану (а не среднее, например), потому что имеем дело с неправильными распределениями; медиана — самостоятельное, реальное значение, с которым мы сравниваем другие такие же значения.
4 Результаты
В этом разделе мы более подробно исследуем дефектные микроклоны, изучив примеры и проведя статистическую оценку.
4.1 Общее описание результатов
В табл. 2 собрана основная статистика по результатам исследования C2. На протяжении периода с середины 2011 года по июль 2015 года мы применяли полный набор диагностик PVS-Studio на выбранных нами 219 открытых проектах. Андрей Карпов, который специализируется на консультации по разработке ПО, выполнял анализ всех этих проектов, используя последние версии PVS-Studio, доступные на момент проверки каждого конкретного проекта. Он отфильтровал ложные срабатывания, в результате чего осталось 1 891 предупреждение, указывающее на потенциальные дефекты в коде. Эти предупреждения были сгруппированы по 162 диагностикам. Затем мы изучили каждое сообщение и обнаружили, что 272 из них были выданы двенадцатью диагностиками и имеют отношение к микроклонам. В девяти случаях сообщения дублировались, поэтому в итоге осталось 263 микроклона. Статистический анализ на уровне проектов показывает, что наши диагностики смогли распознать клоны с дефектами в половине из отобранных проектов. Почти все эти случаи (92%) содержат по меньшей мере один пример с эффектом последней строки.

Таблица 2 — Статистика по результатам исследования
Табл. 3 содержит сводку по обнаруженным ошибкам в 263 микроклонах. В общей сложности, 74% многострочных клонов содержат ошибку в последней строке и 90% однострочных клонов — в последней инструкции.
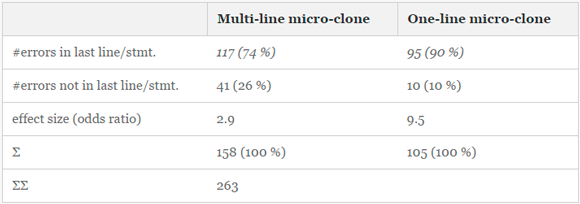
Таблица 3 — Сводка по результатам исследования
4.2 Подробный анализ результатов
Для более полного понимания принципов работы диагностик, которые мы применили для обнаружения микроклонов, ниже мы рассмотрим некоторые наиболее показательные примеры из 263 предупреждений PVS-Studio, относящихся к микроклонам и выявляющих наиболее частые ошибки из табл. 1.
4.2.1 V501 — Одинаковые подвыражения
Как видно из табл. 1, большинство предупреждений о микроклонах были выданы диагностикой V501. Ниже показан типичный пример такой ошибки из браузера Chromium:
Пример 5
Chromium

Это однострочный микроклон, в котором второе и третье подвыражения полностью совпадают, но при этом соединяются логическим оператором ИЛИ (||), что делает выражение избыточным. На самом деле, оно должно было проверять фамилию (NAME_LAST) — так в этом блоке из трех единиц проявляется эффект последней строки.
4.2.2 V517 — Одинаковые условные выражения
Диагностика V517 обнаруживает одинаковые условия для двух веток if-оператора.
Пример 6
linux-3.18.1

Тело оператора else if после третьего микроклона на строке 9 является мертвым кодом, поскольку поток исполнения никогда не достигнет его. Случай, когда значение slot равно 0, будет обработан уже в первом условии.
4.2.3 V519 — Присваивание одинаковых значений переменной
Присваивание переменной двух значений подряд обычно является либо просто избыточной операцией (и, следовательно, создает проблемы при поддержке кода, затрудняя его понимание, так как первое присваивание оказывается недействительным), либо откровенной ошибкой, так как в качестве правого операнда должно было быть другое значение. В следующем примере из проекта MTASA переменной m_ucRed дважды присваивается значение, в то время как переменной m_ucBlue присвоить значение забыли.
Пример 7
MTASA

Диагностика V519 хорошо показала себя при обнаружении дефектов в большинстве «обычных» программ, однако следует с осторожностью подходить к анализу кода прошивок и прочего низкоуровневого кода, как показано в примере 8:
Пример 8
linux-3.18.10
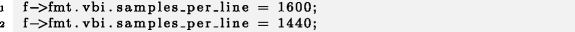
Во второй строке переменной f→fmt.vbi.samples_per_line повторно присваивается значение, несмотря на то что строчкой выше ей уже было присвоено другое значение. Поскольку дальше в потоке управления в данном методе отсутствуют вызовы других методов, может показаться, что присваивание в строке 1 не дает никакого результата. Однако, поскольку это присваивание действует на протяжении по крайней мере одного такта, за это время присвоенное значение может быть прочитано из других потоков (например, сторожевым таймером, отслеживающим состояние буфера) или использоваться каким-либо другим способом. На всякий случай мы компилируем такой код в режиме Release: если компилятор в процессе оптимизации убирает первое присваивание, значит, это действительно ошибка.
4.2.4 V523 — Одинаковое поведение в разных ветках
Микроклоны в разных ветках if-оператора обычно можно упростить, оставив только один блок, как в следующем примере из Haiku:
Пример 9
Haiku
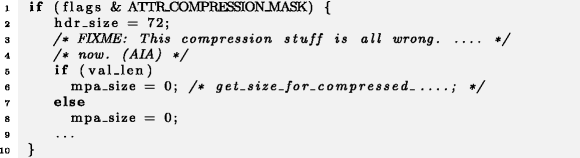
Более вероятно, однако, что в ветке else переменной mpa_size должно было быть присвоено какое-то другое значение. Контекст данного микроклона вызывает подозрения, так как в комментарии в строке 3 сказано, что «с компрессией тут все неправильно», а обнаруженный дефектный микроклон подходит под эту формулировку.
4.2.5 V524 — Одинаковые тела функций
Две дублированные функции с одним и тем же телом очень подозрительны. В примере 10 в строке 5 должен быть вызов PerPtrBottomUp.clear (). Также это один из редких примеров, когда в микроклоне из двух дубликатов копия предшествует оригиналу

Пример 10
Clang

4.2.6 V537 — Подозрительное использование переменной или инструкции
Показательный пример диагностики V537, приведенный ниже, взят из Quake III. В этом случае PVS-Studio предупреждает о необходимости проверить использование rectf.X:
Пример 11
Quake III

Во второй (т.е. последней) строке данного клона y-координата прямоугольника ошибочно задается округленным значением rectf.X.
4.2.7 V656 — Две переменные с одинаковыми значениями
Диагностика V656 выявляет разные переменные, которые инициализируются одной и той же функцией. Однако мы вынуждены проявлять осторожность при анализе таких предупреждений, поскольку среди них потенциально может наблюдться много ложных срабатываний. В качестве подобного примера можно привести случай, когда две переменные инициализируются одним и тем же значением, но затем, ниже по коду, начинают различаться. Все микроклоны нашей выборки, относящиеся к диагностике V656, взяты из проекта LibreOffice.
Пример 12
LibreOffice

В этом случае переменной maSelection.Max () вместо максимального значения aSelection присваивается минимальное, что явно указывает на ошибку.
4.2.8 Контрпример
Как мы уже видели в примере 12, не во всех дефектных микроклонах ошибка локализуется в последней строке или инструкции. Следующий пример из Chromium — один из 12 случаев, когда ошибка проявляется во второй строке трехстрочного микроклона (см. табл. 4):
Пример 13
Chromium

В строке 2 ячейка data_[M02] вычитается сама из себя, хотя на самом деле подразумевалось следующее:
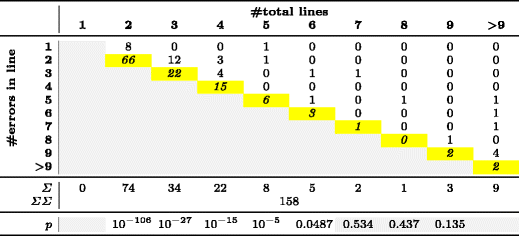
Таблица 4 — Распределение ошибок в микроклонах размером ? 2 строк
4.3 Статистическая оценка
В табл. 4 показано распределение ошибок по строкам для 158 многострочных микроклонов, а в табл. 5 — распределение ошибок по инструкциям внутри одной строки для 105 однострочных микроклонов. Ячейки с серым фоном не содержат значащих данных. Например, в микроклоне длиной 2 строки не может быть ошибок в третьей строке. Ячейки с желтым фоном, расположенные по диагонали, соответствуют ошибкам в последних строках или инструкциях.
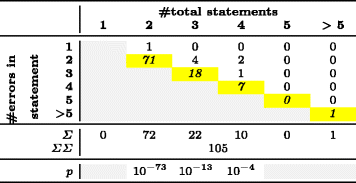
Таблица 5 — Распределение ошибок в однострочных микроклонах
Для каждого столбца табл. 4 и 5 мы применили критерий согласия Пирсона
Отвечая на вопросы RQ1 и RQ2, мы получили статистически значимые p-значения для микроклонов длиной 2, 3, 4, 5 или 6 строк и для микроклонов из 2, 3 или 4 инструкций (p < 0,05). Эти результаты говорят о том, что нулевая гипотеза о равномерном распределении ошибок по строкам/инструкциям неверна и может быть отброшена. В реальности ошибки в гораздо большей степени концентрируются в последней строке или инструкции. Мы предполагаем, что в микроклонах большего размера будет наблюдаться такое же распределение, но подобных примеров в нашей выборке слишком мало, чтобы подтвердить это предположение статистически. Этим случаям соответствуют ячейки с серым фоном в последней строке табл. 4 и 5.
Распределения ошибок в микроклонах разной длин
