Видеоускоритель Intel Arc A770 Limited Edition (16 ГБ): третий реальный игрок на поле 3D-ускорителей для настольных ПК

Intel Arc A770
Сегодня мы рассмотрим долгожданную новинку — дискретную видеокарту компании Intel, предназначенную для игровых ПК — впервые за долгие годы. Первой попыткой выхода на этот рынок была видеокарта под наименованием Intel 740, также известная как i740 — графический ускоритель с интерфейсом AGP, который вышел в далеком 1998 году для популяризации графической шины AGP (не все наши читатели застали ее существование). Особенностью i740 было использование видеопамяти лишь для буфера кадров, а текстуры подкачивались из оперативной памяти — именно в этом быстрый (по тем временам) интерфейс и помогал. Получилось неплохо, но конкуренции с 3dfx, Nvidia и ATI компания не выдержала, после полутора лет производство было прекращено, а последователи i740 не снискали особого успеха, хотя некоторые разработки до сих пор вполне могут жить в интегрированных видеоядрах компании.
Затем Intel предприняла куда менее удачную попытку создания GPU (точнее, GPGPU) с проектом Larrabee. Идея была интересной и во многом опередила свое время: Larrabee предполагалось сделать гибридным, универсальным и куда более гибким по сравнению с тогдашними видеочипами AMD и Nvidia, он поддерживал когерентность кэш-памяти для всех ядер и основывался на ядрах x86-архитектуры с добавленной поддержкой 64-битных команд и многопоточности. Гибрид универсального CPU и GPU с широкими векторными SIMD-блоками и блоками текстурной выборки казался очень красивым на бумаге, но не обеспечивал требуемой производительности в чисто графических задачах, с которыми неплохо справлялись фиксированные аппаратные блоки GPU конкурентов, которые тоже становились всё более гибкими, но постепенно. В итоге в 2010 году проект зарубили, а разработки перешли в чисто вычислительные решения Xeon Phi.
Еще спустя почти 10 лет, в 2018 году, в Intel снова загорелись идеей выхода на рынок дискретных GPU. Тогда компания переманила к себе известных личностей: Раджу Кодури (Vega и Navi), Джима Келлера (архитектура Zen), Криса Хука (который занимался в AMD маркетингом), еще нескольких наших коллег — профильных журналистов из западных изданий, и работа закипела. Проект известен под именами Intel Xe и Intel Arc, сначала вышел DG1 — в мобильных решениях на основе процессоров 11-го поколения Tiger Lake и в виде дискретной видеокарты Iris Xe DG1. Решения были интересными, но не слишком распространенными — скорее, они стали первым шагом в правильном направлении. Рынок устал от конкуренции двух больших игроков и ждал полноценного выхода игровых видеокарт серии Arc, который стал одним из важнейших событий индустрии за последние годы. На создание конкурентоспособного GPU и создание работоспособных драйверов для него способна далеко не каждая компания, и именно Intel всегда казался тем, кто может оживить конкуренцию на этом рынке, ведь у них есть большой опыт по разработке и графических решений, пусть в основном интегрированных, и программного обеспечения.
Для Intel новая линейка — попытка создать конкурентоспособные продукты в сегменте относительно производительных игровых видеокарт. Долгое время графические решения компании относились исключительно к встроенной графике, в процессорах компании были интегрированные ядра в том числе на основе архитектуры Xe, но они подходят разве что для вывода пользовательского интерфейса и веб-серфинга, которые требуют сейчас довольно быстрой обработки большого количества растровых изображений, а серьезно играть на них не получится. (Более того, в единичных моделях процессоров Intel даже применялось видеоядро компании AMD.) Еще один важный момент — высокопроизводительные вычисления на GPU. Рынок этот, может быть, не слишком большой в штуках, но зато жирный по деньгам. На нем давно обосновались Nvidia и AMD, и Intel разработала для него вычислительный процессор Ponte Vecchio на той же новой архитектуре. Создание хорошо масштабируемой архитектуры позволило компании выпустить и дискретные игровые видеокарты, осталось лишь разработать качественное программное обеспечение (драйверы), тем более что некоторые наработки в виде интегрированных решений у них уже были.

Рынок игровых видеокарт в последние годы очень непрост для выхода на него новичков, конкуренция очень серьезная. AMD и Nvidia жестко сражаются много лет, и их GPU добились схожей эффективности в целом, если не брать частности, вроде производительности аппаратной трассировки лучей. По сочетанию сложности чипов, их производительности и цены GeForce и Radeon сейчас довольно близки, и сходу конкурировать с ними абсолютно на равных вряд ли у кого бы получилось. Вот и посмотрим, насколько приблизилась к ним Intel.
Линейка настольных дискретных видеокарт Arc состоит из моделей A770, A750, A580 и A380. Серия Arc A300 нацелена на начальный уровень производительности, A500 — на средний, A700 — на высокий. Несмотря на такое позиционирование, Intel не собирается пока что конкурировать с топовыми моделями AMD и Nvidia, отличающимися очень крупными GPU с потреблением в 350–400 Вт и более. Младшая модель Arc A380 была изначально представлена только в Китае, а вот остальные получили полноценный мировой анонс — так, видеокарты модели Arc A700 вышли на рынок 12 октября. Модель Arc A380 в свое время прошла мимо нас, так как не была представлена на местном рынке, но по производительности она близка к GeForce GTX 1650 и Radeon RX 6400, отличаясь лучшими возможностями по кодированию и декодированию видеоданных, что для этого сегмента довольно важно. На сегодняшний день видеокарты на основе Arc A380 в России купить несложно, в основном производства Gigabyte. А вот про Arc A580 мы ничего так и не знаем — ни цены, ни даты выпуска в продажу, ни того, существуют ли до сих пор планы на эту модель.
Младший представитель серии Arc — A380 — не снискал особой популярности, да и выход этого GPU в целом оказался явно шероховатым, но это позволило Intel разобраться в своих планах и проблемах к выходу продолжения линейки, лучшего представителя которой — Arc A770 — мы сегодня и рассмотрим. Это уже куда более мощная видеокарта, конкурентами которой сходу видятся Nvidia GeForce GTX 3060 и AMD Radeon RX 6600 XT. Именно таким — весьма приличным — уровнем производительности довольствуется наиболее массовая категория пользователей. От пары видеокарт подсерии Arc A700 ждали совсем иного уровня производительности, чем от решения начального уровня, каким была A380. Пока что мы рассмотрим только старшую модель линейки Arc, но чуть позже доберемся и до Arc A750.
Модель Arc A770 отлично подходит для игр при разрешении Full HD и максимальных настройках качества графики, в таких условиях рассмотренная видеокарта должна быть близка к GeForce RTX 3060 и Radeon RX 6600 XT. В разрешении 2560×1440 все эти видеокарты уже потребуют снижения настроек качества в играх и/или включения технологий масштабирования изображения, вроде XeSS, DLSS или FSR. Итак, давайте рассмотрим новинку.

| Графический ускоритель Arc A770 | |
|---|---|
| Кодовое имя чипа | ACM-G10 |
| Технология производства | 7 нм (TSMC N6) |
| Количество транзисторов | 21,7 млрд |
| Площадь ядра | 406 мм² |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12 Ultimate, с поддержкой уровня возможностей Feature Level 12_2 |
| Шина памяти | 256-битная: 8 независимых 32-битных контроллеров памяти с поддержкой памяти типа GDDR6 |
| Частота графического процессора | до 2100 (2400) МГц |
| Вычислительные блоки | 32 мультипроцессора Xe-Core, включающих 4096 ядер для целочисленных расчетов INT32, вычислений с плавающей запятой FP16/FP32 и специальных функций |
| Тензорные блоки | 512 матричных ядер XMX для матричных вычислений INT2/INT4/INT8/FP16/BF16 |
| Блоки трассировки лучей | 32 ядра RTU для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 256 блоков текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 16 широких блоков ROP на 128 пикселей с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка HDMI 2.0b и DisplayPort 1.4a (2.0 10G) |
| Спецификации референсной видеокарты Arc A770 | |
|---|---|
| Частота ядра | 2100 (2400) МГц |
| Количество универсальных процессоров | 4096 |
| Количество текстурных блоков | 256 |
| Количество блоков блендинга | 128 |
| Эффективная частота памяти | 16,0/17,5 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 256 бит |
| Объем памяти | 8/16 ГБ |
| Пропускная способность памяти | 512/560 ГБ/с |
| Вычислительная производительность (FP32) | до 17,2 терафлопс |
| Теоретическая максимальная скорость закраски | 269 гигапикселей/с |
| Теоретическая скорость выборки текстур | 538 гигатекселей/с |
| Шина | PCI Express 4.0×16 |
| Разъемы | один HDMI и три DisplayPort |
| Энергопотребление | до 225 Вт |
| Дополнительное питание | 8-контактный и 6-контактный разъемы |
| Число слотов, занимаемых в системном корпусе | два |
| Рекомендуемая цена | $329/$349 |
Название рассматриваемой сегодня модели видеокарты Intel из нового семейства Arc 7 соответствует принципу наименования решений компании — старшая в подсерии модель получила индекс A770, а младшая, которая стоит на ступень ниже — A750. Еще ниже в линейке есть бюджетная A380, которая уже какое-то время присутствует на рынке, а посередине — A580, но про нее давно ничего не слышно. А вот выше A770 в этом поколении пока что ничего не будет, так что новинку можно назвать условно топовым решением — для Intel, конечно.
Если смотреть только на сложность и площадь GPU, а также на количество исполнительных блоков в нем, довольно высокую частоту и соответствующие высокие значения теоретической производительности, то может показаться, что Arc A770 должен конкурировать чуть ли не с GeForce RTX 3080 и Radeon RX 6800, но это не совсем так. Похоже, что архитектура Xe-HPG не способна столь же эффективно загружать работой исполнительные блоки, как GPU конкурентов, и реальная производительность новинки ниже. Сама Intel считает основным конкурентом для Arc A770 видеокарту GeForce RTX 3060, ну и примерно аналогичную ей по уровню Radeon RX 6600 XT.
Видеокарта Arc A770 вышла в двух версиях, отличающихся объемом видеопамяти: 8 ГБ и 16 ГБ, первая из которых получила рекомендованную цену в $329, а вторая — $349. Младшая же модель Arc A750 получила цену в $289, и о ней мы еще расскажем отдельно. В реальности младшая Arc A770 продается дороже GeForce RTX 3060 и Radeon RX 6600 XT, а старшая Arc A770 с 16 ГБ достает даже до цен GeForce RTX 3060 Ti и Radeon RX 6700 XT. Поэтому и сравнивать новинку мы будем сразу с несколькими моделями видеокарт конкурентов.
Объем видеопамяти новой видеокарты Intel выбран в соответствии с 256-битной шириной шины памяти — 8 или 16 ГБ для разных моделей. 16 ГБ для старшей модели Arc A770, возможно, покажутся небольшим перебором, ведь производительности GPU этого ценового сегмента просто не хватит для тех разрешений и условий, в которых может не хватить 8 ГБ, но всё же это потенциальное преимущество перед конкурентами — некий задел на будущие проекты. Ну, а пока что и 8 ГБ памяти младшей модели вполне достаточно при любых графических настройках, актуальных для GPU такого уровня.
Модель Arc A770 предлагается рынку в варианте самой Intel — в виде видеокарты специального издания Limited Edition, которую мы сегодня как раз и рассматриваем. Правда, речь только о старшей модели с 16 ГБ, младшей 8-гигабайтной в таком дизайне нет. Для своей видеокарты инженеры компании Intel разработали строгий дизайн с аккуратной RGB-подсветкой. Для питания карты модели A770 Limited Edition используется два разъема: 8-контактный и 6-контактный, что вместе с возможностями питания по разъему PCIe составляет ровно те 225 Вт, что заявлены в качестве максимального энергопотребления видеокарты. К слову, это не так уж мало на фоне 160–180 Вт у основных конкурентов.
Из дополнительных плюсов отметим, что Intel расщедрилась на хорошую добавку для покупателей, включив в комплект цифровую версию игры Call of Duty: Modern Warfare II, которая отдельно стоит немалых денег. По понятным причинам, это щедрое предложение не относится к гражданам РФ, ну так и видеокарты к нам сейчас попадают лишь неофициально — через Китай. Кроме специальных версий самой Intel, видеокарты подсерии Arc A700 производятся и продаются под брендами немногочисленных партнеров компании.
Что ж, настало время рассмотреть микроархитектуру, на которой основана Arc A770.
Микроархитектура Xe HPG
Сначала давайте разберемся с терминологией. Arc — это не архитектура, а линейка видеокарт, поделенная на подкатегории: Arc 3, Arc 5 и Arc 7, отличающиеся друг от друга количеством исполнительных блоков. Всё первое поколение дискретных видеокарт Arc основано на графических процессорах семейства Alchemist, а в будущем выйдут Battlemage, Celestial и Druid —, но всех их объединяет микроархитектура Xe HPG.

Семейство видеокарт Intel Arc
В семействе настольных видеокарт Arc «Alchemist» топовой является серия Arc 7, в нее входит две модели: Arc A750 и Arc A770. Обе они основаны на графическом процессоре ACM-G10, но A770 использует полную версию этого чипа с 32 ядрами Xe, а в A750 активны лишь 28 из 32 ядер. Обе модели функционально идентичны, предлагают поддержку DirectX 12 Ultimate и XeSS и ориентированы на пользователей, играющих в разрешениях 1080p и 1440p с высокими или максимальными настройками графики. Вероятно, Intel решила целиться в первую очередь именно в средний ценовой сегмент потому, что большинство геймеров покупает видеокарты именно из него.
Самым большим графическим процессором Alchemist стал чип ACM-G10, на котором основаны модели видеокарт A770 и A750. Структурно чипы архитектуры Xe-HPG схожи с тем, как построены решения Nvidia. Аналогично кластерам GPU в чипах Nvidia, в архитектуре Intel несколько ядер собраны в верхнеуровневый блок организации, называемый Render Slice — каждый из них содержит всё необходимое для независимых вычислений, включая сами вычислительные блоки, текстурные модули, блоки аппаратной трассировки лучей, обработки геометрии и растеризации.

Раздел Render Slice
Каждый такой раздел содержит по четыре Xe-ядра, по четыре блока трассировки лучей, движки обработки геометрии, 32 блоков текстурирования, 16 блоков ROP и т. п. За счет разного количества таких разделов в разных моделях GPU компания Intel масштабирует свои решения от интегрированных до используемых в высокопроизводительных вычислениях. Так можно создавать графические процессоры разного класса, к ним нужно лишь добавить управляющую логику, шину памяти, кэш-память второго уровня и прочее: видеодвижок, контроллер дисплея и другие блоки. Вот из восьми таких разделов Render Slice и собрали чип ACM-G10, ранее известный как DG2–512.
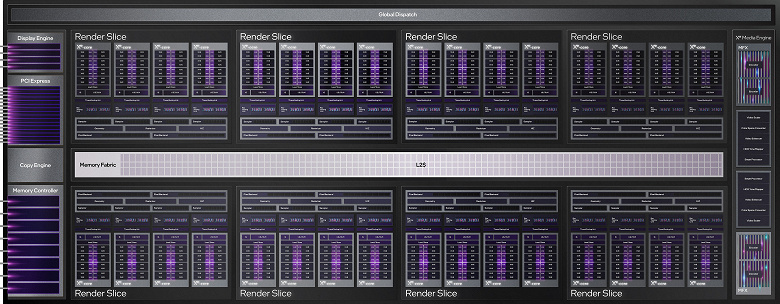
Полная версия графического процессора ACM-G10
Модель Arc A770 использует полную версию чипа, которая имеет восемь блоков Render Slice и 32 Xe-ядра, включающие 4096 шейдерных блоков, 256 блоков текстурирования TMU и 128 блоков растеризации ROP. Кроме него, в линейке есть еще ACM-G11 (DG2–128), на котором основаны видеокарты Arc 3, а старший чип ACM-G10 служит основой и для Arc 5, и для Arc 7. Оба графических процессора производятся по техпроцессу N6 на фабриках TSMC — это техпроцесс 7 нм, но с чуть улучшенными характеристиками по сравнению с 7-нанометровым техпроцессом, по которому производятся графические процессоры Radeon.
Полный чип ACM-G10 состоит из 512 исполнительных устройств, каждый из которых имеет по 8 FP/INT-блоков, что аналогично 4096 шейдерным блокам у AMD и Nvidia. Видеокарта Arc A770 основана на полной версии чипа, а A750 использует урезанную версию чипа с 28 активными Xe-ядрами в семи разделах Render Slice (один из них полностью деактивирован в этой версии GPU), что соответствует 3584 шейдерным блокам.
Основными элементами, из которых собраны новые GPU, являются уже не исполнительные блоки EU, известные нам ранее по интегрированным решениям Intel, а ядра Xe. Аналогично потоковым мультипроцессорам SM в графических процессорах Nvidia, они содержат по несколько векторных движков и движков матричных вычислений. Векторные движки Xe Vector Engine (XVE) включают SIMD-блоки для INT- и FP-вычислений и регистровый файл, они в Xe-ядрах разбиты попарно, используют общий планировщик и работают параллельно — диспетчер эффективно загружает FP- и INT-блоки, а также присоединенные к паре XVE матричные блоки XMX, о которых мы поговорим далее.

Xe-ядро
Xe-ядро по строению схоже с мультипроцессором SM у Nvidia и аналогичным процессором WGP у AMD — все они имеют собственную локальную память и кэш инструкций и служат минимальными блоками при построении GPU. SM и WGP разделены на четыре раздела, каждый из которых имеет свой планировщик и регистровый файл для работы 32 линий FP32. Xe-ядро Intel также имеет 128 линий FP32, но делит их уже на 16 разделов, называемых векторными движками — Xe Vector Engine (XVE).
У Intel всегда были относительно узкие блоки SIMD: в 11-м поколении процессоров они обслуживали всего четыре потока одновременно, в 12-м поколении (Rocket Lake) доросли до восьми. Но индустрия давно пришла к SIMD32 в графических процессорах, и программное обеспечение учитывает это, так что более узкие исполнительные блоки кажутся неоптимальным решением. Если в Ada Lovelace (Nvidia) и RDNA 3 (AMD) блоки могут за цикл запускать по 32 или 64 потока, то архитектура Intel требует четыре цикла для достижения того же результата на одном векторном движке, и не особо важно, что SIMD-блоков в Xe-ядре аж 16 штук.
Если не делать специфических оптимизаций под такую архитектуру для максимально полного использования векторных движков XVE, то часть SIMD и прочих соответствующих ресурсов, вроде кэш-памяти, будет много простаивать, что снизит эффективность в реальных задачах (при высоких пиковых значениях производительности). На практике это выльется в то, что Intel Arc может отставать от конкурентов схожей сложности и теоретической мощности в случае не слишком сложных шейдеров и при общей невысокой нагрузке.

На исполнение одновременно могут запускаться различные инструкции: операции с плавающей запятой, целочисленные операции и специальные функции, а также матричные операции на отдельном блоке — все три типа исполнительных блоков могут быть активными одновременно. Это частично схоже с тем, что есть у Nvidia, но графические процессоры последней используют один порт запуска для INT- и FP-операций, что снижает пиковую FP-производительность в случае запуска целочисленных операций.
Каждая пара векторных движков имеет общий порт для доступа к подсистеме памяти, и L1-кэш каждого Xe-ядра выполняет запросы восьми таких портов, а каждый из этих портов — запросы от двух векторных блоков. В мультипроцессоре SM (Nvidia) L1-кэш обрабатывает запросы только от четырех разделов SM, а в CU (чипов AMD) L1-кэш обрабатывает запросы лишь от двух SIMD-блоков. Так что наверняка система загрузки/сохранения данных в Xe-ядрах усложнена из-за того, что его поделили на большое количество небольших разделов.
Как и современные GPU конкурентов, первый серьезный видеочип компании содержит приличный объем кэш-памяти. Intel использует традиционную двухуровневую иерархию кэш-памяти, как и большинство GPU. Но они решили поместить в чипы больше кэш-памяти по сравнению с конкурентами. Так, каждое Xe-ядро в Arc A770 содержит 192 КБ L1-кэша, а мультипроцессор SM архитектуры Ampere — лишь 128 КБ, общих для L1-кэша и локальной памяти. L2-кэш в графическом процессоре Intel также довольно объемный — 16 МБ, что в несколько раз больше кэшей второго уровня в конкурирующих чипах AMD и Nvidia (но у AMD используется дополнительный L3-кэш), причем при таком большом объеме задержки не слишком велики — даже меньше, чем у RTX 3060 Ti с ее жалкими 2 МБ L2-кэша. Даже в младшей модели графического процессора ACM-G11 поместилось аж 4 МБ L2-кэша!
Такое решение помогает сгладить требования к пропускной способности видеопамяти. Которая у старшего чипа, впрочем, и без того достаточно высока: при 256-битной шине памяти и объеме видеопамяти 8 или 16 ГБ она составляет 512 ГБ/с и 560 ГБ/с для пары Arc A770. Это очень прилично для данного ценового диапазона. В младшей модели с 8 ГБ памяти используются другие чипы GDDR6-памяти — с эффективной частотой в 16 ГГц против 17,5 ГГц у старшей, но обе модификации имеют полноценную 256-битную шину памяти. Ну, а потенциальным плюсом старшего варианта на перспективу является то, что он имеет 16 ГБ локальной памяти, тогда как GeForce RTX 3060 Ti и Radeon RX 6600 XT довольствуются лишь 8 ГБ, что в редких случаях уже может ограничивать производительность.
Аппаратная трассировка лучей
В последнее время все более важной становится аппаратная реализация блоков трассировки лучей. У решений Nvidia они более продвинутые и эффективно производят соответствующие вычисления, а видеокарты AMD в этом плане отстают, так как их блоки трассировки используют продвинутые возможности текстурных модулей, которые аппаратно исполняют лишь часть работы, а остальное перекладывается на плечи обычных шейдерных блоков, что гораздо менее эффективно в целом.
Архитектура Intel Xe-HPG по ускорению трассировки больше похожа на то, что использует Nvidia, причем даже скорее в RTX 40, а не в RTX 30 или RTX 20. В графической архитектуре Intel содержатся выделенные специализированные блоки, занимающиеся поиском пересечения луча и геометрии в иерархической структуре BVH. К каждому Xe-ядру прилагается один блок трассировки, и всего на Render Slice их получается четыре, а в рассматриваемом GPU — 32 штуки. Это близко к количеству соответствующих блоков у конкурирующих GPU AMD и Nvidia: 28 штук у RTX 3060 и 32 штуки у RX 6600 XT. Но Intel заявляет, что с применением трассировки Arc A770 будет ближе к RTX 3060 Ti (38 штук) или даже к RTX 3070 (46 штук), и это мы сегодня проверим.
Известно, что блоки трассировки лучей в графической архитектуре Intel имеют некоторый объем кэш-памяти для хранения структур BVH и работают относительно быстро — как минимум, по сравнению с Radeon. Если RT-блок в архитектуре RDNA 2 способен находить одно пересечение луча с треугольником за такт или четыре пересечения с боксом BVH, то блок трассировки Intel — уже 12 пересечений. Nvidia говорит о том, что RT-ядро в чипах архитектуры Turing рассчитывает одно пересечение с треугольником за такт, а Ampere — два. Недавно вышли старшие решения архитектуры Ada Lovelace, в которых еще раз удвоили скорость поиска пересечений луча с треугольником, но тут Intel пока что бояться нечего — топовые видеокарты GeForce RTX 40 не являются конкурентами для Arc A770. А вот по сравнению с видеокартами архитектуры RDNA 2 решение Intel явно должно быть производительнее — даже по пиковой производительности, хотя на практике важнее эффективность вычислений в реальных условиях, а не теоретический максимум, и тут Intel есть чем похвастать.

Аппаратные блоки архитектуры Xe-HPG не только способны полностью аппаратно находить пересечения лучей и использовать ускоряющие структуры BVH, но также имеют некоторые оптимизации, аналоги которым появились только в последней графической архитектуре Nvidia — Ada Lovelace. Для ускорения операций трассировки лучей используется возможность переупорядочивания шейдерных команд для оптимизации работы блоков SIMD. Мы уже подробно рассказывали о том, как это сделала Nvidia в новейшей архитектуре, но Xe-ядра в этом смысле пошли даже еще чуть дальше: они могут переупорядочивать шейдерные потоки автоматически, без указания со стороны программиста. Nvidia так не делает из-за того, что в некоторых случаях их организация переупорядочивания снижает производительность.
Видимо, в Intel применили более продвинутую управляющую логику, они даже называют свою архитектуру аппаратной трассировки асинхронной. В новом GPU отдельный блок для анализа и сортировки потоков шейдеров занимается переупорядочиванием (реорганизацией) шейдеров для более полного использования возможностей шейдерных блоков SIMD и более эффективного исполнения трассировки лучей в итоге. Как это будет работать на практике — сегодня узнаем.
Аппаратное ускорение матричных операций
Как и в современных графических процессорах Nvidia, в Xe-ядрах есть блоки, занимающиеся матричными (тензорными по терминологии Nvidia) вычислениями. Каждое Xe-ядро содержит 16 матричных движков XMX, которые способны проводить вычисления в форматах FP16/BF16 и INT8/INT4/INT2. Все они используются в нейросетях, и производительность составляет 128 операций FP16, 256 INT8 и 512 INT4/INT2 на такт для каждого XMX.
Intel решила разместить довольно большое количество блоков XMX в своих графических процессорах. Возможно, даже слишком много: эти специализированные блоки часто простаивают, поскольку всё еще редко используются в тех же играх, но на GPU они пожирают много места — даже больше, чем тензорные ядра Nvidia. В случае графических процессоров AMD такие матричные вычисления выполняются на обычных SIMD-блоках, а Nvidia использует по четыре относительно больших тензорных блока на каждый мультипроцессор SM. По пиковым значениям производительности каждое Xe-ядро чипа Intel в теории может обеспечить в 4—8 раз бо́льшую скорость матричных вычислений (FP16, INT8 и INT4) по сравнению с соответствующими функциональными блоками в графических процессорах конкурентов. Так что подход Intel выглядит некоторым перебором для игровых решений — вероятно, такая организация лучше подходит для архитектуры, предназначенной для высокопроизводительных вычислений.
Для чего может понадобиться такая мощь в игровых решениях? При недостатке производительности при трассировке лучей можно использовать аппаратно ускоренное шумоподавление с применением искусственного интеллекта, аналогичное тому, что делает Nvidia при помощи тензорных ядер — у Intel для этого же могут применяться матричные движки XMX. Но это еще в основном дело будущего, а прямо сейчас можно использовать их мощь для технологии увеличения производительности, аналогичной DLSS 2. Intel решила реализовать собственную технологию масштабирования разрешения на основе машинного обучения, разработав для этого свой вариант под названием XeSS.
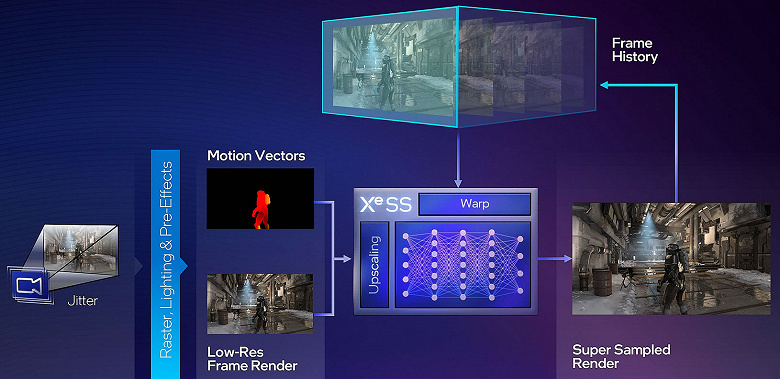
Технология масштабирования XeSS
Опять же, технология масштабирования Intel очень похожа на то, что есть у Nvidia: она реконструирует картинку из низкого разрешения в более высокое, используя информацию из предыдущих кадров (в виде векторов движения) при помощи специально натренированной нейросети — всё как у DLSS 2. В игры технология внедряется примерно так же, как и схожие технологии конкурентов, так что с этим проблем быть не должно. Важно, что XeSS универсальна и работает не только на видеокартах Intel — в случае родных GPU семейства Arc она исполняется в оптимизированном виде на матричных движках XMX, а остальные совместимые графические процессоры используют универсальные DP4a-инструкции (четыре INT8-инструкции, упакованные в один 32-битный регистр), которые поддерживаются большинством современных решений.
Вывод изображения и работа с видеоданными
На фоне конкурентов видеокарты среднего ценового сегмента Intel отличаются поддержкой DisplayPort 2.0 и способностью аппаратного кодирования видеоданных в формате AV1. Но если со вторым всё понятно, то в возможностях вывода изображения на дисплеи есть некоторые нюансы, на которых мы еще остановимся.
Но для начала — обработка видео. Движок обработки медиаданных Xe Media Engine способен аппаратно ускорять кодирование и декодирование роликов в формате AV1, VP9, H.265 HEVC и H.264 AVC. В графических процессорах линейки, даже в том, на котором основана младшая модель Arc A380, таких движков два, каждый из них может обрабатывать свой видеопоток, или они могут совмещать свои мощности при работе над одним потоком. Пока что решения Intel являются единственными в среднеценовом диапазоне, которые умеют аппаратно кодировать видео в формате AV1. Nvidia уже добавила такую возможность в GeForce RTX 40, а AMD сделала это в будущих видеокартах архитектуры RDNA 3, но обе компании пока что даже не анонсировали среднебюджетные решения соответствующих линеек, и если вам нужно кодирование AV1 при бюджете не более $350, то линейка Arc будет единственным выбором.
Что касается вывода информации на дисплеи, то предлагаемые видеокарты имеют выходы DisplayPort и HDMI, а движок Xe Display Engine в новом GPU способен выводить информацию на два монитора с разрешением до 8K при 60 Гц или на четыре 4K с 120 Гц, ну или на четыре 1440p с 360 Гц. Поддерживаются возможности синхронизации кадров VESA Adaptive Sync и Intel Smooth Sync — эта фирменная технология применяется при отключенной вертикальной синхронизации и при помощи специального шейдерного постфильтра размывает границы разрывов, возникающие при выводе нескольких отрендеренных кадров за одно обновление информации на экране — довольно простой и элегантный метод для снижения видимости специфических разрывов.

А теперь о нюансах. Во многих обзорах написано, что видеокарта Intel поддерживает DisplayPort 2.0 и HDMI 2.1, но в этой поддержке есть важные моменты. Во-первых, даже сама Intel пишет о поддержке DisplayPort 1.4a, а про вторую версию скромнее:»2.0 10G Ready» — возможно, из-за того, что дисплеев с поддержкой 2.0 просто нет и совместимость тут условная.
Но еще важнее то, что Intel Arc поддерживают скорость передачи данных по DP лишь до UHBR 10 (10 Гбит/с на линию), но не UHBR 13.5 и UHBR 20. Это всего на 23% больше по сравнению с DisplayPort 1.4a, но UHBR 10 использует более эффективное кодирование, когда в 132 передаваемых битах содержится 128 бит информации (эффективность 97%), а не 8 бит в 10 битах (лишь 80%), поэтому разница в пропускной способности составляет уже около 50%. И поддержка 8K-дисплеев с частотой обновления 60 Гц использует сжатие DSC при кодировании 4:2:2 или 4:2:0.
Второй интересный момент заключается в том, что хотя в самом GPU аппаратно реализована поддержка DisplayPort 2.0 (UHBR 10), но встроенной поддержки HDMI в нем нет, и для реализации соответствующих разъемов производители видеокарт используют чип для преобразования сигнала DP в HDMI — например, Realtek RTD2173, поддерживающий разрешение 4K при частоте обновления 240 Гц и 8K при 60 Гц. И можно говорить о поддержке скорее HDMI 2.0b, чем HDMI 2.1 — всё из-за той же максимальной полосы пропускания по DisplayPort, которая не достигает 48 ГБит/с, требуемых для версии HDMI 2.1.
Краткие выводы по теории
Посчитаем пиковую вычислительную производительность Arc A770 и прикинем, как она сочетается с возможностями конкурентов. ACM-G10 в полной конфигурации состоит из восьми разделов Render Slice, в каждом по четыре Xe-ядра, содержащих 16 векторных движков, каждый из которых способен выполнить по восемь FP32-операций за такт. Удваиваем количество для привычных в 3D-графике FMA-операций, умножаем на частоту в 2,1 ГГц и получаем пиковую вычислительную производительность GPU в 17,2 терафлопса. Показатель неплохой, но реальная производительность будет сильно зависеть от эффективности исполнения — степени загрузки исполнительных блоков GPU. Например, при полуторакратной разнице по пиковым показателям между RTX 3080 и RX 6800 XT, в реальных играх они весьма близки.
Конкурирующая с Arc A770 модель GeForce RTX 3060 имеет только 12,7 терафлопс в пике, а Radeon RX 6650 XT — и того меньше, лишь 10,8 терафлопс. Но по игровым тестам мы знаем, что RX 6650 XT даже чуть быстрее RTX 3060 в среднем, если не брать трассировку лучей, а вот при включении последней ситуация меняется на обратную. Так что пиковые показатели не отражают реальность полностью. На бумаге Arc A770 должна бы конкурировать с RX 6700 XT и RTX 3060 Ti или даже RX 6800 и RTX 3070, но в реальности эффективность нового GPU компании Intel не позволяет добиться этого уровня.
Графический процессор ACM-G10 получился довольно сложным, он состоит из 21,7 млрд транзисторов и имеет площадь кристалла 406 мм². Хотя это и не самый большой GPU, который делает компания Intel в принципе, но для игрового рынка он крупнейший. Navi 22 имеет лишь 335 мм², а GA104 — 393 мм², так что ACM-G10 явно больше конкурента в виде модели AMD RX 6700 XT и схож по площади с чипом Nvidia, на котором основана RTX 3070. По площади он находится, скорее, примерно между Navi 21 и GA104, что довольно много для конкурента GeForce GTX 3060 (Ti) и Radeon RX 6600 XT. А в GeForce RTX 3060 используется чуть ли не вдвое менее сложный графический процессор.
Вероятно, таким большим GPU у Intel получился по нескольким причинам. Во-первых, он содержит приличный объем кэш-памяти второго уровня, чего нет в решениях конкурентов. Во-вторых, структура его Xe-ядер не выглядит идеально сбалансированной именно для игровых применений, часть блоков будет простаивать без работы. Если при простейших FP32-операциях графический процессор ACM-G10 обеспечивает довольно высокую эффективность, близкую к RDNA 2 и Ampere, то из-за разного подхода к делению блоков на SIMD эффективность решения Intel значительно снижается при операциях FMA (fused multiply add — совмещенное умножение-сложение с однократным округлением), которые очень часто используются в графике.
И так как графическая архитектура компании Intel имеет небольшие SIMD, то на сравнительно небольшое количество вычислительных блоков в таком случае приходится больше декодеров, кэшей и прочей обвязки, что делает GPU сложнее и крупнее по площади — без заметного результата в производительности. Ну и еще одно: как мы уже говорили, в каждом Xe-ядре содержится уж слишком много
Полный текст статьи читайте на iXBT
