
[Перевод] Распределённое глубокое обучение: параллелизм моделей и данных в TensorFlow
Значительное количество задач, предусматривающих обучение глубоких нейронных сетей, можно решить на отдельном компьютере, обладающем единственным, сравнительно мощным и быстрым GPU. Но бывает так, что нужно что-то помощнее. Например — данные могут просто не поместиться в память, доступную на отдельной машине. Или окажется, что имеющееся «железо» просто не «потянет» некую задачу. В результате может возникнуть необходимость в горизонтальном масштабировании вычислительных мощностей.

«Горизонтальное масштабирование» — это когда в компьютер добавляют дополнительные GPU, или когда используют несколько машин, входящих в состав кластера. При таком подходе нужен какой-то способ эффективного распределения задач обучения моделей по имеющимся системам. В теории всё просто, но в реальной жизни это — задача нетривиальная. На самом деле — существует несколько стратегий организации распределённого обучения. Выбор конкретной стратегии сильно зависит от конкретной задачи, от данных и от модели.
В этом материале я попытаюсь описать существующие стратегии организации распределённого обучения, раскрыв детали необходимые для того, чтобы читатель смог бы получить общее представление о них. Нашей главной целью будет обретение возможности выбора наилучшей из стратегий для конкретной задачи. Тут я продемонстрирую некоторые примеры кода, основанные на библиотеке TensorFlow. Освоив их, вы разберётесь с тем, как именно устроена программная часть рассматриваемых здесь стратегий распределённого обучения. Но, в любом случае, затрагиваемые здесь концепции применимы не только к TensorFlow, но и к другим библиотекам и фреймворкам глубокого обучения.
Эта публикация входит в серию материалов о глубоком обучении. В предыдущих статьях шла речь о создании собственного цикла обучения для задачи по сегментации изображений с помощью U-net. Мы развернули модель в Google Cloud для того чтобы получить возможность удалённого запуска обучения. Здесь я буду использовать тот же код.
Параллелизм данных и моделей
В сфере распределённого обучения существует две основные школы. Первая основана на параллелизме данных. Вторая — на параллелизме моделей.
Первый сценарий распределённого обучения предусматривает распределение данных по нескольким видеоускорителям или компьютерам и запуск циклов обучения на всех этих системах — либо синхронно, либо асинхронно (с этими терминами мы разберёмся ниже). Я возьму на себя смелость заявить, что 95% сеансов распределённого обучения используют именно этот подход.
Конечно, он сильно зависит от скорости соединений между системами, так как предусматривает передачу больших объёмов данных. Но этот подход, чаще всего, можно признать идеальным решением задачи распределённого обучения. Среди его сильных сторон можно отметить следующие:
Универсальность — так как его можно использовать для любой модели и в любом кластере.
Быстрая компиляция — так как программы написаны в расчёте на выполнение на конкретном кластере.
Полное использование ресурсов аппаратного обеспечения.
И, чтобы дать вам некоторое представление о том, о чём мы будем говорить, отмечу, что большая часть этой статьи посвящена именно параллелизму данных, а не параллелизму моделей. Но в некоторых ситуациях модели оказываются слишком большими, отдельного компьютера для их обучения недостаточно. В таких случаях параллелизм моделей может оказаться предпочтительнее параллелизма данных.
Параллелизм моделей позволяет разделять модели на отдельные фрагменты и обучать каждый из них на отдельной системе.
Чаще всего этот подход используется в современных моделях обработки естественного языка, в таких, как GPT-2 и GPT-3. Такие модели имеют миллиарды параметров (в GPT-2, например, используется 1,5 миллиарда параметров).
Обучение на одном компьютере
Прежде чем продолжать — предлагаю ненадолго притормозить и вспомнить о том, как выглядит обучение моделей на отдельном компьютере, обладающем единственным GPU. Представим, что у нас есть простая нейронная сеть с двумя слоями и тремя узлами в каждом из слоёв. У каждого узла имеются веса и смещения, представляющие собой обучаемые параметры сети. Шаг обучения начинается с препроцессинга данных. После этого данные передают сети, а она выдаёт прогноз (выполняется прямой проход). Затем прогноз сравнивают с ожидаемым результатом, вычисляя значение функции потерь. Далее — выполняется обратный проход, вычисляются градиенты, с их использованием обновляются веса. Потом этот процесс повторяется.
В простейшем сценарии для обеспечения обучения вычислительными ресурсами достаточно одного CPU с несколькими ядрами. Тут стоит помнить и о том, что при таком подходе в нашем распоряжении оказывается многопоточность, что позволяет ускорить обучение. Если нужно ещё больше скорости — можно прибегнуть к видеоускорителю, что приводит к необходимости передавать изучаемые моделью данные и результаты вычисления градиентов между оперативной памятью компьютера и видеоускорителя. Следующий шаг — оснащение компьютера несколькими GPU. Следующий — обучение моделей на нескольких компьютерах, объединённых сетью, каждый из которых оснащён несколькими видеоускорителями.
Для того чтобы быть уверенными в том, что мы друг друга понимаем — дадим некоторые определения:
Воркер — отдельная машина, содержащая CPU и один или большее количество GPU.
Ускоритель — отдельный GPU (или TPU).
All-reduce — распределённый алгоритм, агрегирующий обучаемые параметры, взятые у отдельных воркеров или ускорителей. В подробности работы этого алгоритма я вдаваться не буду. Если описать его в двух словах, то окажется, что он основан на получении данных о весах от всех воркеров и на их агрегировании для вычисления итоговых весов.
Так как большинство стратегий применимы и на уровне воркера, и на уровне ускорителя, в тексте вы можете встретиться с конструкцией «воркер/ускоритель». Это указывает на то, что распределение вычислений может быть выполнено между различными компьютерами или между различными GPU. То же самое означает и слово «устройство». В результате эти термины мы будем использовать как взаимозаменяемые.
Хорошо. Теперь, когда мы освоили основы, пришло время поговорить о различных стратегиях, которые можно использовать для организации обучения с параллелизмом по данным.
Стратегии распределённого обучения
Стратегии распределённого обучения можно грубо разделить на две большие категории: синхронные и асинхронные.
При синхронном обучении все воркеры/ускорители работают над разными фрагментами входных данных и на каждом шаге обучения агрегируют градиенты. При асинхронном обучении все воркеры/ускорители независимо обучают модель на входных данных и обновляют значения переменных в асинхронной форме.
Ну, это и так понятно… Спасибо, Шерлок… А теперь давайте в этом разберёмся.
Синхронное обучение
При синхронном обучении каждому воркеру/ускорителю отправляют разные фрагменты данных. У каждого устройства имеется полная копия модели, которая обучается лишь на части данных. Прямой проход во всех этих моделях начинается в одно и то же время. Все они вычисляют различные выходные данные и градиенты.
В этот момент все устройства обмениваются друг с другом информацией, осуществляется агрегирование градиентов с использованием вышеописанного алгоритма all-reduce. После того, как все градиенты окажутся скомбинированными, их отправляют обратно на устройства. Теперь все устройства выполняют обратный проход и, в обычном режиме, обновляют локальную копию весов. Следующий прямой проход не начнётся до тех пор, пока все переменные не будут обновлены. Именно поэтому такая схема обучения и называется «синхронной». В каждый момент времени в распоряжении всех устройств имеются в точности одни и те же веса, несмотря на то, что модели, работающие на них, выдают разные градиенты, так как обучаются они на разных данных. Но обновление весов производится с учётом всех данных.
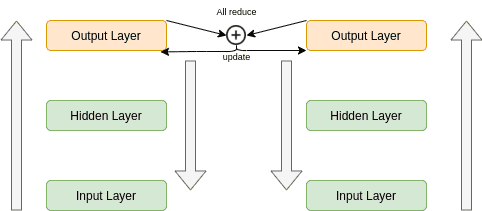 Синхронное распределённое обучение
Синхронное распределённое обучение
В TensorFlow эта стратегия называется «mirrored strategy» (стратегия, использующая зеркалирование), поддерживается два типа этой стратегии.
Стратегия tf.distribute.MirroredStrategy предназначена для организации обучения на нескольких ускорителях в пределах одного и того же воркера. А стратегия tf.distribute.experimental.MultiWorkerMirroredStrategy, как можно догадаться из её названия, предназначена для применения на нескольких воркерах. В основе этих стратегий лежат одни и те же принципы.
Теперь посмотрим на код. Наш цикл обучения собственной разработки состоит из двух функций — train и train_step. Первая проходится по заданному количеству эпох, вызывая в каждой из них функцию train_step. А вторая выполняет один проход по одному пакету данных.
def train_step(self, batch):
trainable_variables = self.model.trainable_variables
inputs, labels = batch
with tf.GradientTape() as tape:
predictions = self.model(inputs)
step_loss = self.loss_fn(labels, predictions)
grads = tape.gradient(step_loss, trainable_variables)
self.optimizer.apply_gradients(zip(grads, trainable_variables))
return step_loss, predictions
def train(self):
for epoch in range(self.epoches):
for step, training_batch in enumerate(self.input):
step_loss, predictions = self.train_step(training_batch)Организация распределённого обучения с использованием цикла обучения собственной разработки — задача не такая уж и простая. Для её решения, в частности, нужно использовать особые функции для агрегирования результатов вычисления функций потерь и градиентов. Поэтому я воспользуюсь высокоуровневым API Keras. Ведь наша цель — рассмотрение концепций распределённого обучения, а не исследование тонкостей TensorFlow. Если же вы, всё же, хотите узнать о том, как организовать такое обучение с использованием собственного цикла — взгляните на этот раздел официальной документации по TensorFlow.
Итак, если подумать о коде для обучения моделей, то можно представить себе нечто такое:
def train(self):
"""Компилирует и обучает модель"""
self.model.compile(optimizer=self.config.train.optimizer.type,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=self.config.train.metrics)
model_history = self.model.fit(self.train_dataset, epochs=self.epoches,
steps_per_epoch=self.steps_per_epoch,
validation_steps=self.validation_steps,
validation_data=self.test_dataset)
return model_history.history['loss'], model_history.history['val_loss']Для построения нашей U-net-модели можно воспользоваться такой командой:
self.model = tf.keras.Model(inputs=inputs, outputs=x)Полный код можно найти в нашем GitHub-репозитории.
Стратегия MirroredStrategy
В документации по TensorFlow говорится следующее: «Каждая переменная в модели дублируется (зеркалируется) в каждой из копий. Все вместе эти переменные формируют единственную абстрактную переменную, называемую MirroredVariable. Синхронизация этих переменных друг с другом поддерживается благодаря применению к ним одинаковых изменений, обновляющих их значения». Полагаю, эта выдержка из документации объясняет причину того, что в названии обсуждаемой тут стратегии есть слово «зеркалирование».
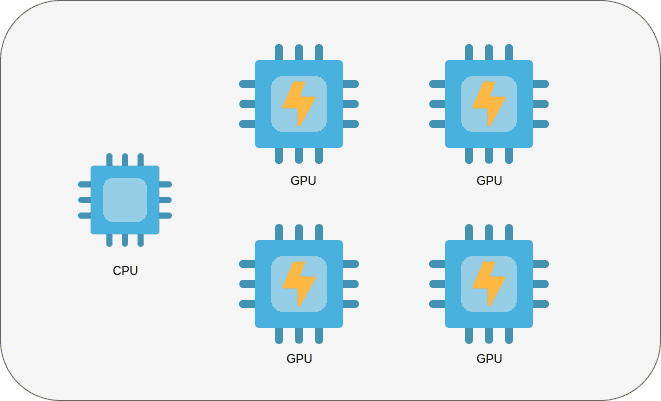 Система с несколькими GPU
Система с несколькими GPU
Инициализировать стратегию MirroredStrategy можно так:
mirrored_strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])Как вы уже, наверное, поняли, мы собираемся запустить обучение на двух GPU, имена которых передаём в качестве аргументов при создании экземпляра класса. После этого остаётся лишь обернуть наш код в mirrored_strategy:
with mirrored_strategy.scope():
self.model = tf.keras.Model(inputs=inputs, outputs=x)
self.model.compile(...)
self.model.fit(...)Вызов scope() позволяет обеспечить зеркалирование всех переменных на всех устройствах, и то, что блоки, находящиеся ниже, будут знать о том, что они работают в распределённой среде обучения модели.
Стратегия MultiWorkerMirroredStrategy
Стратегия MultiWorkerMirroredStrategy, по аналогии с MirroredStrategy, позволяет организовать обучение моделей с использованием нескольких воркеров. При её использовании, как и прежде, создаются копии всех переменных на всех воркерах, а обучение выполняется синхронно.
 Кластер вычислительных систем
Кластер вычислительных систем
В этот раз мы, для определения воркеров, будем использовать JSON-настройки:
os.environ["TF_CONFIG"] = json.dumps(
{
"cluster":{
"worker": ["host1:port", "host2:port", "host3:port"]
},
"task":{
"type": "worker",
"index": 1
}
}
)А всё остальное выглядит точно так же, как прежде:
multi_worker_mirrored_strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
with multi_worker_mirrored_strategy.scope():
self.model = tf.keras.Model(inputs=inputs, outputs=x)
self.model.compile(...)
self.model.fit(...)Стратегия CentralStorageStrategy
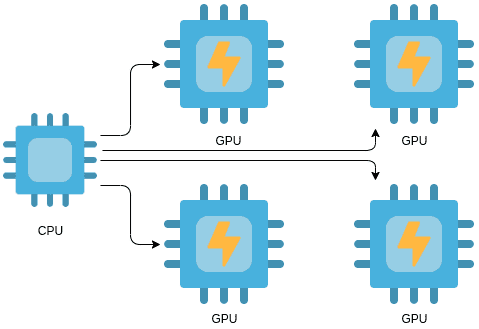 Стратегия CentralStorageStrategy
Стратегия CentralStorageStrategy
Ещё одна стратегия, о которой стоит упомянуть — это «central storage strategy» (стратегия, использующая центральное хранилище). Она применима лишь в окружениях, где имеется единственный компьютер с несколькими GPU. Если имеющиеся в нашем распоряжении GPU не могут хранить всю модель, мы назначаем CPU центральным «хранителем» информации, ответственным за поддержание глобального состояния модели. В этой связи переменные не зеркалируются на различных устройствах, вместо этого все они находятся в ведении CPU.
В результате CPU отправляет переменные видеоускорителям, которые выполняют обучение модели, вычисляют градиенты, обновляют веса и отправляют их обратно центральному процессору, который комбинирует их с использованием операции reduce.
central_storage_strategy = tf.distribute.experimental.CentralStorageStrategy()Асинхронное обучение
У синхронного обучения есть множество сильных сторон, но системы, основанные на таком обучении, может быть достаточно трудно масштабировать. Более того, масштабирование таких систем может привести к тому, что некоторые воркеры длительное время будут пребывать в состоянии простоя. Если воркеры различаются в плане функциональных возможностей, если некоторые из них отключаются для выполнения их обслуживания, или если им назначены различные приоритеты — это означает, что асинхронный подход может оказаться более удачным выбором, так как воркерам не придётся друг друга ждать.
Принимая решение о том, какой подход к обучению выбрать — синхронный или асинхронный, можно пользоваться следующими рекомендациями, основанными на практике, которые, конечно, не являются универсальными:
Если имеется множество маленьких, ненадёжных устройств с ограниченными возможностями — лучше прибегнуть к асинхронному подходу.
Если в нашем распоряжении есть мощные устройства, связанные быстрой сетью, то, возможно, лучше будет применить синхронный подход к обучению.
Теперь предлагаю выразить суть асинхронного подхода к обучению простыми словами.
Отличие асинхронного обучения от синхронного заключается в том, что воркеры выполняют обучение модели с разной скоростью, при этом каждому из них не нужно ждать остальных. Как реализовать это на практике?
Стратегия ParameterServerStrategy
Самой распространённой стратегией асинхронного обучения является «parameter server strategy» (стратегия, использующая сервер параметров). Когда имеется кластер воркеров, им можно назначать разные роли. Другими словами, некоторые устройства делают серверами параметров, а остальные — воркерами, занимающимися обучением модели.
Серверы параметров хранят параметры (глобальное состояние) модели и ответственны за их обновление.
Воркеры, занимающиеся обучением модели, выполняют код цикла обучения и выдают результаты вычисления градиентов и функций потерь на основе обрабатываемых ими данных.
Вот как выглядит схема работы системы, использующей стратегию ParameterServerStrategy:
Мы, как и прежде, создаём копии модели на всех воркерах.
Каждый «обучающий» воркер загружает параметры с сервера параметров.
Эти воркеры выполняют цикл обучения.
После завершения работы они отправляют градиенты серверу параметров, который обновляет веса модели.
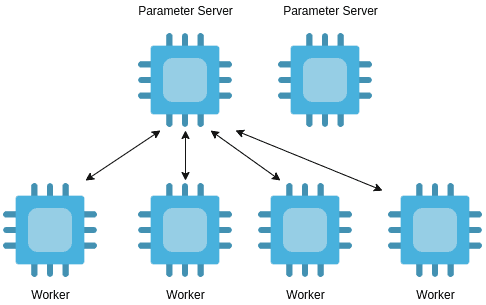 Стратегия ParameterServerStrategy
Стратегия ParameterServerStrategy
Вы, глядя на это, возможно, уже сделали вывод о том, что такой подход позволяет проводить обучение модели в пределах одного воркера независимо от других воркеров, и о том, что его применение позволяет масштабировать обучение. В TensorFlow это может выглядеть так:
ps_strategy = tf.distribute.experimental.ParameterServerStrategy()
parameter_server_strategy = tf.distribute.experimental.ParameterServerStrategy()
os.environ["TF_CONFIG"] = json.dumps(
{
"cluster": {
"worker": ["host1:port", "host2:port", "host3:port"],
"ps": ["host4:port", "host5:port"]
},
"task": {
"type": "worker",
"index": 1
}
}
)Параллелизм моделей
До сих пор мы говорили о распределении данных по разным устройствам и о том, как обучать на них модели, передавая им разные данные. А нельзя ли разделять на части не данные, а сами модели? Именно на это направлено то, что называют «параллелизмом моделей». Хотя этот подход и сложнее в плане реализации, о нём, определённо, стоит упомянуть.
Если модель столь велика, что не помещается в память отдельного устройства, можно разделить её на части, распределить эти части между несколькими устройствами и обучать каждую из частей независимо от других, используя одни и те же данные.
Интуитивно понятным примером такого подхода может стать обучение разных слоёв нейронной сети на разных устройствах. Или, возможно, если говорить об архитектуре, где используются энкодер и декодер, это будет обучение на разных машинах декодера и энкодера.
Помните о том, что в 95% случаев в распоряжении GPU имеется достаточно памяти для того чтобы разместить в ней всю модель.
Изучим очень простой пример параллелизма моделей для того чтобы описать эту концепцию предельно ясно. Представьте, что у нас имеется простая нейронная сеть, у которой есть входной, скрытый и выходной слои.
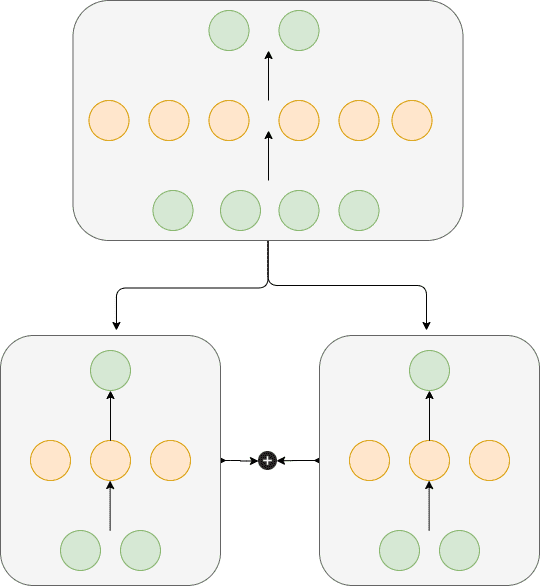 Параллелизм моделей
Параллелизм моделей
Скрытый слой может состоять из 10 узлов. Хорошо будет, если организовать распараллеливание этой модели так: первые 5 узлов скрытого слоя обучаем на одной машине, а остальные 5 — на другой. Конечно, я понимаю, что для такой маленькой модели это перебор, но перед нами — всего лишь учебный пример, поэтому представим, что в этом есть смысл и продолжим анализ нашей системы. Работает она так:
Передаём на обе машины одни и те же пакеты данных.
Каждую часть модели обучаем отдельно от другой.
Комбинируем полученные градиенты с использованием подхода all-reduce, так же, как при обучении моделей с применением параллелизма данных.
Запускаем на обеих машинах обратный проход алгоритма обратного распространения ошибки.
И наконец — обновляем веса на основании агрегированных градиентов.
Обратите внимание на то, что первая машина будет обновлять лишь первую половину весов, а вторая — только вторую половину.
Как уже было сказано, параллелизм моделей чаще всего используется в сфере обработки естественных языков, в моделях, где используются трансформеры, в таких проектах, как GPT-2, BERT, и в других подобных. На самом деле, многие инженеры комбинируют, при обучении таких моделей, распараллеливание данных и моделей, поступая так для того, чтобы обучать эти модели настолько быстро и эффективно, насколько это возможно. В этой связи я вспомнил, что существует TensorFlow-библиотека, которая пытается избавить разработчиков от сложностей, связанных с разделением моделей. Речь идёт о TensorFlow Mesh. Если вам это интересно — обязательно взгляните на эту библиотеку. Я не буду углубляться в эту тему, так как, если честно, у меня до сих пор не возникало необходимости в применении параллелизма моделей, да и большинству из вас это, вероятно, тоже не понадобится (по крайней мере — в ближайшем будущем).
Итоги
В этом материале мы исследовали различные подходы к организации распределённого обучения моделей с использованием нескольких устройств. Мы рассказали о применении параллелизма данных и моделей. Хочется надеяться, что то, что вы сегодня узнали, пригодится вам при организации эффективного обучения ваших моделей.
О, а приходите к нам работать?
Habrahabr.ru прочитано 106097 раз
