
[Перевод] Создаем свой аналог sqlite c нуля. Часть #1
Будучи веб разработчиком, я регулярно использую реляционные базы данных в своей работе, но я не понимаю как они работают. Возникают следующие вопросы:
В каком формате данные будут сохранены (в памяти или на диске)
Когда они должны сохраняться на диск?
Почему первичный ключ (primary key) является единственным на одну таблицу?
Как происходит отмена транзакции?
Как формируются индексы?
Когда и как происходит полное сканирование таблицы?
Что такое подготовленное выражение (prepared statement)?
Другими словами, как работают базы данных?
Чтобы разобраться в этом, я создам базу данных с нуля. В качестве образца я использую sqlite, потому что он создан быть небольшим с меньшим количеством возможностей, чем mysql или postgresql, так что я надеюсь что я пойму как это работает. Вся база данных хранится в одном файле!
Sqlite
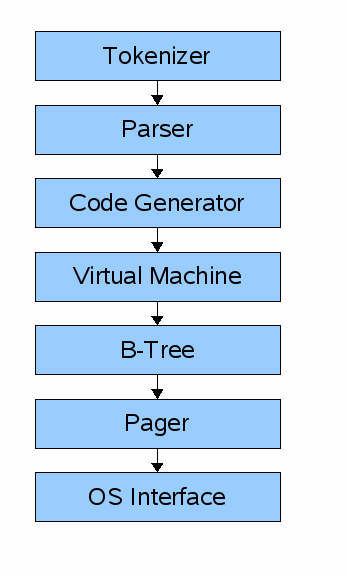
Более подробное внутренней работы sqlite находиться на ихсайте.
Архитектура sqlite
Запрос проходит по порядку через компоненты для получения или модификации данных. Фронтенд состоит из:
На входе у нас sql запрос, на выходе байт код виртуальной машине sqlite (по сути скомпилированная программа которая может работать над базой данных).
Бэкенд состоит из:
Виртуальной машины (virtual machine)
Би-дерево (B-tree)
Pager
Интерфейса системы (os interface)
Виртуальная машина воспринимает байт код сгенерированный фронтендом как инструкции. Она затем может выполнят операции на одной или более таблиц или индексов, каждые из которых хранятся в структуре данных названной b-tree. По сути это машина является большим switch`ом, где каждый case отвечает за определенную инструкцию.
Каждое Би-дерево состоит из множества нод. Каждая нода длинной в один page. Би-дерево может получить страницы (page) из файла или сохранить это назад в файл благодаря выдаче команд pager`у.
Pager получает команды на чтение или запись данных. Он отвечает за чтение/запись по соответствующим смещениям (offsets) в файле базы данных. Он также сохраняет в кэше недавно открытые страницы (page) в памяти, и определяет когда эти страницы должны записаны обратно в файл.
Интерфейса системы это слой который отличается в зависимости для какой операционной системы sqlite был скомпилирован. В этом туториале, я не собираюсь добавлять поддержку для множества устройств.
Путь в тысячу вёрст начинается с первого шага, так что давайте начнём чего то менее простого: REPL
Создаем простой REPL
Sqlite запускает собственный repl когда мы запускаем его из командной строки:
~ sqlite3
SQLite version 3.16.0 2016-11-04 19:09:39
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
sqlite> create table users (id int, username varchar(255), email varchar(255));
sqlite> .tables
users
sqlite> .exit
~Чтобы сделать также, наша главная функция будет иметь бесконечный который печатает коммандную строку, получает строку от пользователя, затем обрабатывает эту строку:
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
}Мы определим InputBuffer как маленькую обертку вокруг состояния, которое нам необходимо хранить для взаимодействия с getline (). (подробнее об этом через минуту)
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = (InputBuffer*)malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}Далее, print_prompt () выводит строку пользователю. Мы делаем это перед чтением каждой строки ввода.
void print_prompt() { printf("db > "); }Чтобы прочитать строку ввода, используем getline ()
ssize_t getline(char **lineptr, size_t *n, FILE *stream);lineptr: указатель на переменную которую мы используем как буфер содержащий прочитанную строку. Если он NULL, то память на него выделяет getline и таким образом память должна быть освобождена пользователем, даже если команда не выполниться.
n: Указатель на переменную, где сохраняется размер буфера.
stream: Что эта функция будет читать. Мы будем читать стандартный поток.
возвращаемое значение: Число прочитанных байт, которое может быть меньше, чем размер буфера.
Мы говорим getline сохранять прочитанную строку в input_buffer→buffer и размер выделенного буфера в input_buffer→buffer_length. Мы храним возвращаемое значение в input_buffer→input_length
buffer начинается как null, так что getline выделяет достаточно памяти чтобы держать строку ввода и делает buffer указателем на нее.
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
// Игнорировать символ новой строки
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}Сейчас по хорошему создать функцию которая освобождает выделенную память для экземпляра InputBuffer и buffer элемента это же структуры (getline выделяет память для input_buffer→buffer в read_input).
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}В конце, мы парсим и выполняем команду. Пока что распознается только одна команда: .exit, которая закрывает программу. В противном случае мы выводим сообщение ошибки и продолжаем цикл.
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}Давайте попробуем что мы написали!
~ ./db
db > .tables
Unrecognized command '.tables'.
db > .exit
~Хорошо, мы имеем работающий REPL. В следующей части, мы начнем разработку нашего языка команд. Тем временем, вот вся программа этой части:
#include
#include
#include
#include
typedef struct {
char* buffer;
size_t buffer_length;
ssize_t input_length;
} InputBuffer;
InputBuffer* new_input_buffer() {
InputBuffer* input_buffer = malloc(sizeof(InputBuffer));
input_buffer->buffer = NULL;
input_buffer->buffer_length = 0;
input_buffer->input_length = 0;
return input_buffer;
}
void print_prompt() { printf("db > "); }
void read_input(InputBuffer* input_buffer) {
ssize_t bytes_read =
getline(&(input_buffer->buffer), &(input_buffer->buffer_length), stdin);
if (bytes_read <= 0) {
printf("Error reading input\n");
exit(EXIT_FAILURE);
}
// Ignore trailing newline
input_buffer->input_length = bytes_read - 1;
input_buffer->buffer[bytes_read - 1] = 0;
}
void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer->buffer);
free(input_buffer);
}
int main(int argc, char* argv[]) {
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
exit(EXIT_SUCCESS);
} else {
printf("Unrecognized command '%s'.\n", input_buffer->buffer);
}
}
} Habrahabr.ru прочитано 30156 раз
