
LangBar++. Автоматическое исправление раскладки набранного текста с использованием словарей Hunspell
В предыдущей статье о программе LangBar++, занятой ручным исправлением раскладки и преобразованием текста, говорилось, что в автоматическом исправлении раскладки «нет добра», и что идейно я против такого главенства машины над духом. Но вопрос остался, и не давал покоя. И если уж машина все равно берет свое, почему бы мне и не принять в этом посильное участие?
Первой моей мыслью было то, как это сделать максимально просто и без ненужного кровопролития. И если уж что-то делать, то не копию Punto Switcher, а нечто достаточно универсальное, чем можно будет пользоваться не только с сочетанием языков английский-русский.
Представлений о принципе работы таких программ у меня не было, но постепенно стало ясно, что в основе процесса автоматического исправления раскладки лежат три вещи:
Хук, перехватывающий нажатия клавиш
Параллельная запись текста на двух языках — текущем и альтернативном, какой вводился бы, будь активна другая раскладка
Сверка этих двух текстовых потоков с соответствующими словарями, и, в случае отсутствия совпадений в текущей раскладке и наличия в альтернативной, исправление раскладки с затиранием старого текста и вводом нового
Хук в программе уже был, используемый для ручного преобразования набранного текста. Со вторым вопросом все было сложнее. Сочетание русский-английский представляет из себя наиболее тривиальный вариант, поскольку английские и русские клавиши имеют взаимно-однозначное соответствие, пусть и меняющееся в зависимости от используемых раскладок. Когда речь заходит о языках вроде французского или немецкого, все становится куда сложнее. Появляются мертвые клавиши и диакритические знаки, набираемые, с правым Alt. Вдобавок, сама клавиатура меняет виртуальные коды клавиш, так что почва уходит из-под ног.
Со словарями тоже не было никакой ясности. Для преобразования достаточно сравнительно простых словарей, благо преобразование большей частью происходит в первые три-четыре символа. Для начальных опытов было решено взять словари Hunspell, представляющие собой списки слов, убрать в них все, относящееся к аффиксам, т. е. к образованию словоформ, и пользоваться.
После первых опытов с сочетанием английский-русский стало ясно, что даже на обрезках в первые три-четыре-пять, максимум шесть знаков происходит потеря слов, на которых должно происходить срабатывание автоматики. Распаковка русского словаря Hunspell в 150000 строк дает миллион триста тысяч словоформ! Надо пользоваться самим Hunspell, и от этого никуда не деться.
Здесь следует сказать о преимуществах, которые дает использование Hunspell в программном варианте. Предназначенный для проверки правописания, он может проверять конечную форму слова, и одновременно давать подсказки-исправления для неверно написанных или незавершенных слов. Мы загружаем введенные символы как есть, а так же, если слово незавершено, проверяем версию со звездочкой * в конце и извлекаем необходимые подсказки. Следует только отфильтровать их, и вердикт «подходит-не подходит» у нас в руках.
Отдельно следует сказать о том, что дает использование Hunspell применительно к языкам, использующим диакритику и мертвые клавиши. Дело в том, что словари составлены для наших сумбурно-либеральных времен, и предполагают наибольший пользовательский произвол. Хотите пользоваться диакритикой, умлаутами и всем прочим — пользуйтесь, а нет — мы будем проверять ваш упрощенный текст, лишь бы он не выходил за известные рамки. Например, символы с диакритикой, повешенные на отдельные клавиши, часто нельзя игнорировать. В то же время в русском языке замена ё на е допустима, а в белорусском — нет. Словари Hunspell аккумулируют общепринятые представления о такой пользовательской свободе и ее границах.
Отсюда фундаментальный принцип построения программы: мы будем отслеживать ввод текста на двух языках, загружать в Hunspell эти параллельные тексты, а также их лишенные диакритики дубликаты (в словарях ее мало!) и производить их верификацию. При этом преобразованный текст будет результатом записи физических (!) нажатий клавиш в новой раскладке, а не этих, возможно не совсем точных, попыток определения альтернативного текста. Так что во всяком случае, пользователь получает именно то, что он ввел.
Проблема мертвых клавиш решается вместе с этим: диагностировать их программно несложно, нам нужно будет лишь исключить их нажатия и скормить Hunspell символы, лишенные диакритических знаков. Таким образом можно обойтись без конфигурационных файлов, в которых будут прописываться особенности раскладок (а их множество, официальных и нет).
Результатом должно быть получение универсального средства для исправления раскладки набранного текста между достаточно различными языками. Например, сочетания русский-белорусский или русский-украинский работают посредственно из-за сходств лексикона и раскладок, но сочетания английский-русский или французский-немецкий работают без проблем, в последнем случае исключая некоторые общепринятые или новомодные слова. Имеются словари Hunspell для почти сотни языков. Я не полиглот, чтобы это проверять, но при достаточном лексическом различи все должно работать применительно к языкам Европы (+Америки, из нее родом) и бывшего СССР.
Еще одной возможностью, предоставляемой программой, является режим одного языка. То есть вы набираете, например, английское слово на русской, украинской или белорусской раскладке клавиатуры, и оно автоматически исправляется с переключением на английскую раскладку. При этом обратное преобразование не производится! Важно лишь чтобы к каждому из этих языков у вас стояли словари, поскольку иначе будет множество ложных срабатываний (программа проверяет их наличие).
Настройки программы достаточно просты:

Здесь имеется озвучка, уведомления на экране, возможность отмены преобразования и обработка слов с трех символов (во избежание ложных срабатываний). Также можно выключить обработку аббревиатур и выключить обработку отдельных букв (Punto Switcher не обрабатывает отдельные буквы, здесь это возможно, в худшем случае, с минимальной правкой словаря). Можно явно задавать границы слов, можно предотвращать автопреобразование после некоторых действий редактирования текста.
Включенность автоматики отображается на иконке в трее и флажке у текстового курсора. Плюс имеется средство, позволяющее активировать или, наоборот, выключать работу автоматики в окнах интересующих программ.
Теперь о возможности расширения словарного состава, который наверняка несовершенен. Во времена, когда еще предполагалось использование простых текстовых словарей, было создано средство для их создания из подручного материала. Вы загружаете текстовый файл или несколько файлов, оно разбивает его на слова, фильтрует по определенному принципу и выдает словарь с одним словом на строку. Называется это средство Конвертер словарей и выглядит вот так:
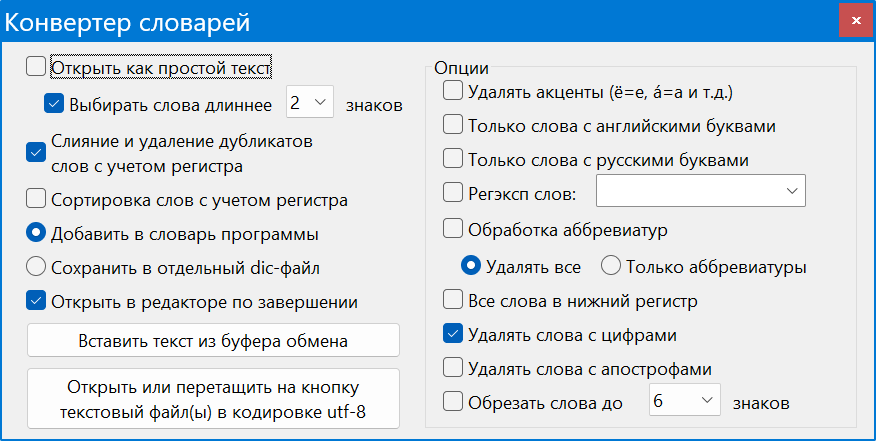
Для использования достаточно перетащить файл (ы) на кнопку или вставляете содержимое из буфера обмена чтобы получить результат. Можно просто разобрать на слова текст с необходимой лексикой и добавить в основной словарь, поместив файл в соответствующий каталог. Дубликаты общеупотребительных слов при этом будут поглощены при загрузке словаря, а все уникальное будет участвовать в обработке текста. Можно, включив соответствующую фильтрацию, получить словарь аббревиатур и т. д…
Вопрос: и что, это так и работает, из коробки?
Ответ: в целом, да. С шестью языками, идущими с программой (русский, белорусский, украинский, английский, французский, немецкий) все должно идти без проблем, с оговоркой о сходстве первых трех и за исключением редких совпадений, мешающих автоматическому исправлению раскладки.
Для их отлова сделано средство визуализации работы программы в виде тултипа, выводящего найденные слова в основной и альтернативной раскладках, и, в скобках, подходящие словарные статьи :
en-US tot tot (tot, toto)
ru-Ru еще еще (еще)
Здесь случай английской и русской раскладок, поясняющий, почему набор символов tot не ведет к преобразованию в слово еще (нужно закомментировать слово tot в английском словаре). Подобные случаи малочисленны и относятся только к коротким словам. За все время работы в паре английский-русский мне встретилось с полдюжины таких слов.
Что еще? Имеется словарь исключений, куда можно вписать зловредные слова (до сих пор не пользуюсь этим), история отмен автопреобразования и простая статистика работы автоматики, которой пользовался при доводке программы:

В итоге получилось развитие идей «Punto Switcher и K», но открытое, более настраиваемое, расширяемое и многоязычное. В сочетании с много лучшей визуализацией, мощным ручным преобразованием текста и приспособленностью к работе с множеством раскладок.
Можете попробовать это на вкус
Habrahabr.ru прочитано 52043 раза
