
Кто круче rsync? Интересные алгоритмы для синхронизации данных

Тридж, автор rsync
Что может быть приятнее, чем минимизировать объём бэкапа или апдейта? Это не просто экономия ресурсов, а чистая победа интеллекта над энтропией Вселенной. Исключительно силой разума мы уменьшаем размер файла, сохраняя прежний объём информации в нём, тем самым уменьшая поток фотонов в оптоволокне и снижая температуру CPU. Реальное изменение физического мира силой мысли.
Если без шуток, то все знают rsync — инструмент для быстрой синхронизации файлов и каталогов с минимальным трафиком, который пришёл на замену rcp и scp. В нём используется алгоритм со скользящим хешем, разработанный австралийским учёным, программистом и хакером Эндрю Триджеллом по кличке Тридж (на фото).
Алгоритм эффективный, но не оптимальный.
rsync
Эндрю Триджелл разработал rsync в 1996 году для своей кандидатской диссертации, которую защитил в 1999-м.
Архитектура, реализация и производительность алгоритма rsync описана в 3-м разделе диссертации (pdf), то есть с 49 по 69 страницы.
Ниже вкратце изложена суть алгоритма в части определения, какие части файла нуждаются в синхронизации между компьютерами А и Б:
Получатель А разделяет файл на куски фиксированного размера S, для каждого вычисляет MD4-хеш и скользящий хеш (rolling hash). Хеши отправляются Б.На своей стороне отправитель Б вычисляет хеши для всех перекрывающихся кусков файла, начиная с первого байта. Если хеш какого-то фрагмента совпал с хешем на стороне А, то этот кусок является кандидатом на исключение из синхронизации. Таким образом, вычисляются фрагменты файла для передачи.
Эффективность алгоритма обеспечивается особым свойством скользящего хеша, который использует предыдущие значение, поэтому вычисление является крайне дешёвым.
Скользящий хешНапример, если скользящий хеш байт с 1 по 10000 байты равен
R, то для расчёта скользящего хеша со 2 по 10001 байты достаточно значенияRи значений двух байтов (1 и 10001).
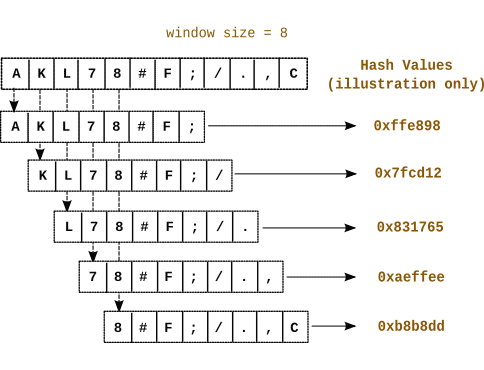
Как видим, ключевая особенность алгоритма rsync — понятие скользящего хеша, который оптимизирует вычисления, существенно ускоряя процесс синхронизации. В остальном идея и реализация довольно простые.
Сам Эндрю Триджелл (Тридж) хорошо известен в сообществе Linux. Он разработал ещё много полезных инструментов, в том числе участвовал в создании Samba, написал архиватор rzip на основе rsync и шахматный движок KnightCap (обучение с подкреплением). Тридж также известен как хакер, взломавший телеприставку TiVo, чтобы она работала в Австралии, где телесигнал транслируется в формате PAL.
Считается, что одна из его работ привела к конфликту сообщества Linux с разработчиком системы управления версиями BitKeeper. В результате конфликта впоследствии пришлось написать Git и Mercurial. Впрочем, это уже отступление от нашей темы…
Итак, алгоритм rsync и концепция скользящего хеша используется во многих программах для синхронизации файлов, резервного копирования (инкрементальный бэкап), контроля версий и так далее. Он реализован в десятках инструментов, в том числе:
- rdiff,
- librsync (Dropbox, rdiff-backup, duplicity и другие приложения),
- acrosync (приложение Acrosync),
- вышеупомянутый duplicity применяется для инкрементальных бэкапов в простых хранилищах файлов, таких как локальная файловая система, sftp, Amazon S3 и многие другие. Используется librsync для генерации дельт, а потом выполняется их шифрование с помощью GPG и передача на бэкенд для хранения,
- macOS 10.5 и позже,
- zsync (Ubuntu и другие Linux-дистрибутивы для передачи апдейтов к образам ISO),
 Rclone (S3, Google Drive и более 50 других облачных провайдеров),
Rclone (S3, Google Drive и более 50 других облачных провайдеров), - rsnapshot.
… и многих других. По сути, это один из важных кирпичиков современного технологического стека.
Но оказывается, что rsync тоже можно улучшить.
Оптимизации
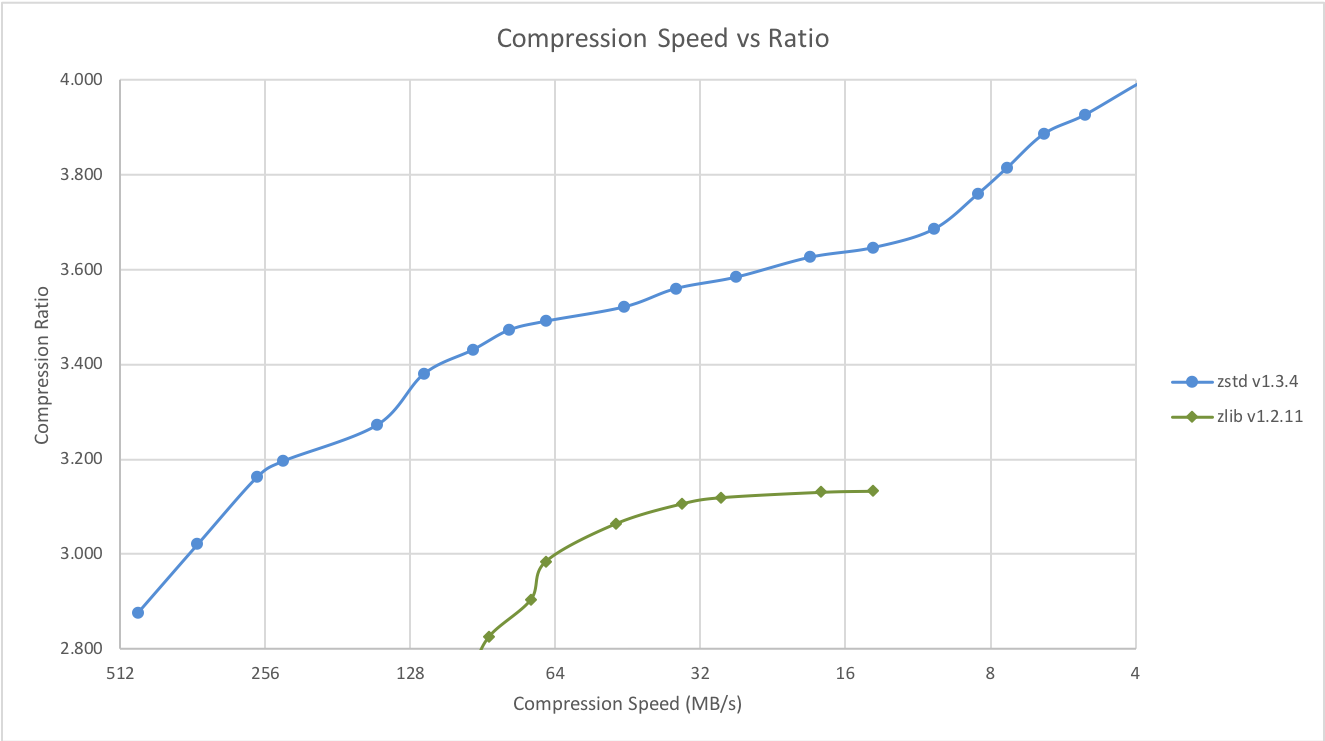
Во-первых, его можно лучше приспособить для специфических применений, таких как обновление сжатых (архивированных) данных. В данном случае нам нужен формат хранения, позволяющий эффективно декомпрессировать отдельные части архива без необходимости декомпрессии всего документа. Например, в архиваторе Zstandard Seekable Format (используется в Facebook) входные данные разбиваются на кадры, каждый из которых сжимается независимо и может быть распакован независимо. Затем декомпрессор по «таблице поиска» немедленно переходит к нужным данным.
Формат опенсорсный, так что этот архиватор zstd можно использовать как более эффективную альтернативу zlib и brotli.
Отсюда уже остался один шаг до введения хранилища данных с дедупликацией ненужных фрагментов.
Блоки переменного размера
Оказывается, если сдвигать границы блоков хотя бы на границы файлов, то выявляется на 10–20% больше избыточных данных, чем стандартным способом с блоками одинакового размера в потоке данных. Поэтому разбиение на фрагменты переменного размера (Content-Defined Chunking, CDC) традиционно используется в системах дедупликации, то есть поиска и удаления дубликатов.

Блоки переменного размера и смещение границ. Зелёным цветом отмечены дубликаты. Как видим, при смещении границ и увеличении отдельных блоков удаётся сохранить эффективность дедупликации.
Есть также проблема производительности, потому что непрерывное вычисление скользящего хеша сильно нагружает CPU. Например, в системе Gear-based CDC (GC) для снижения нагрузки используется несколько разных хешей и другие трюки.
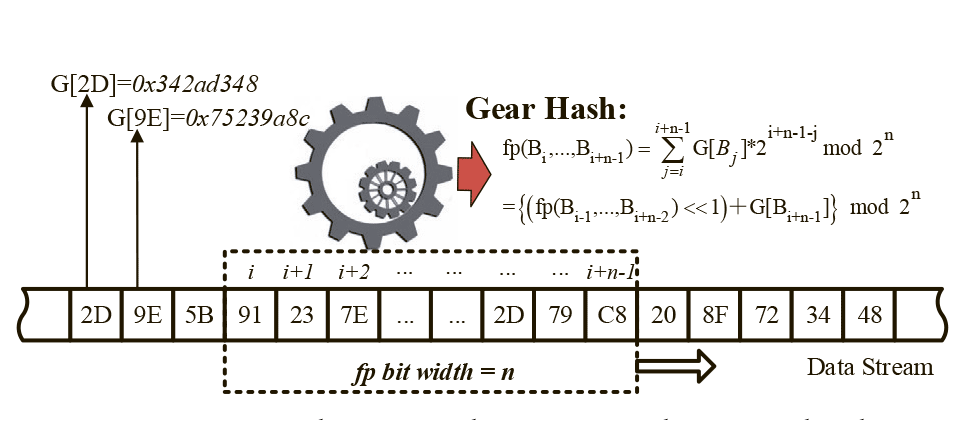
Схематическая диаграмма GC
Вскоре после появления GC разработчики FastCDC предложили ряд существенных оптимизаций, и с тех пор именно FastCDC считается оптимальным алгоритмом CDC.
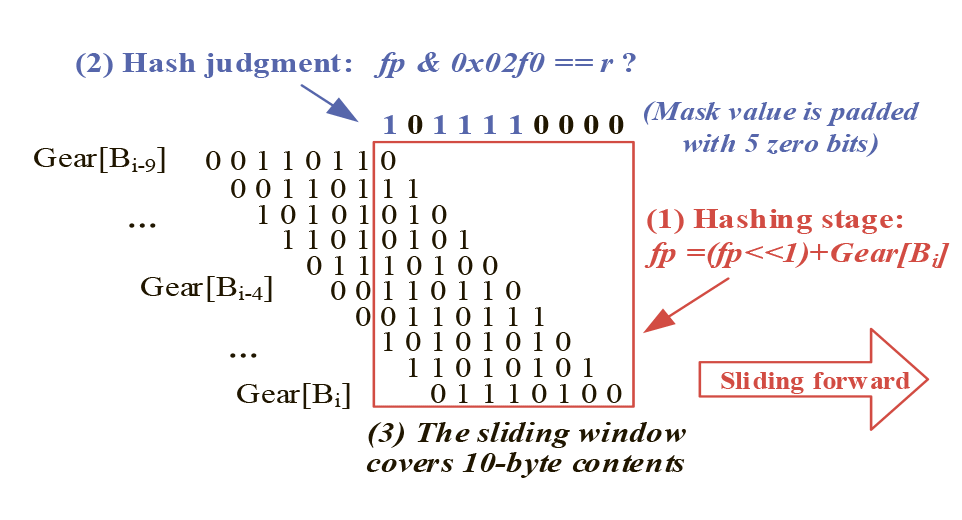
Набивка пяти нулевых битов в маску для расширения скользящего окна FastCDC
FastCDC значительно снижает нагрузку на CPU: он позволил отказаться от вычисления скользящего хеша для всех байтов в потоке данных (то есть некоторые фрагменты игнорируются), увеличил средний размер блоков и скорость дедупликации.
Синхронизация по контенту
Вышеописанные концепции оптимизируют дедупликацию данных с учётом контента, то есть границ файлов и других фрагментов данных. Но задача дедупликации схожа с задачей сжатия данных, когда повторяющиеся фрагменты потока данных просто заменяются ссылками на них.
А сжатие можно использовать везде, где мы храним и передаём данных, в том числе для синхронизации файлов, резервного копирования и обновлений. Именно для этого создана утилита casync, сокращённо от «синхронизация с адресацией по контенту» (Content Addressable Data Synchronize).
Утилита casync использует базовый алгоритм rsync с блоками переменного размера, как описано выше. Ко всем этим оптимизациям кодирования разработчики добавили ещё одну — удаление границ файлов перед разбивкой на блоки. То есть раньше разбивка на блоки переменного размера специально учитывала границы файлов, чтобы оптимизировать дедупликацию. А сейчас для дополнительной оптимизации эти границы, наоборот, не учитываются в некоторых случаях.
Это означает, что маленькие файлы объединяются с близкими похожими файлами, а большие файлы разбиваются на части, что позволяет системе находить дубликаты за пределами границ файлов и каталогов. Это также гарантирует, что размеры фрагментов распределены относительно равномерно, без влияния границ файлов.
Примерно так выглядит процесс кодирования:
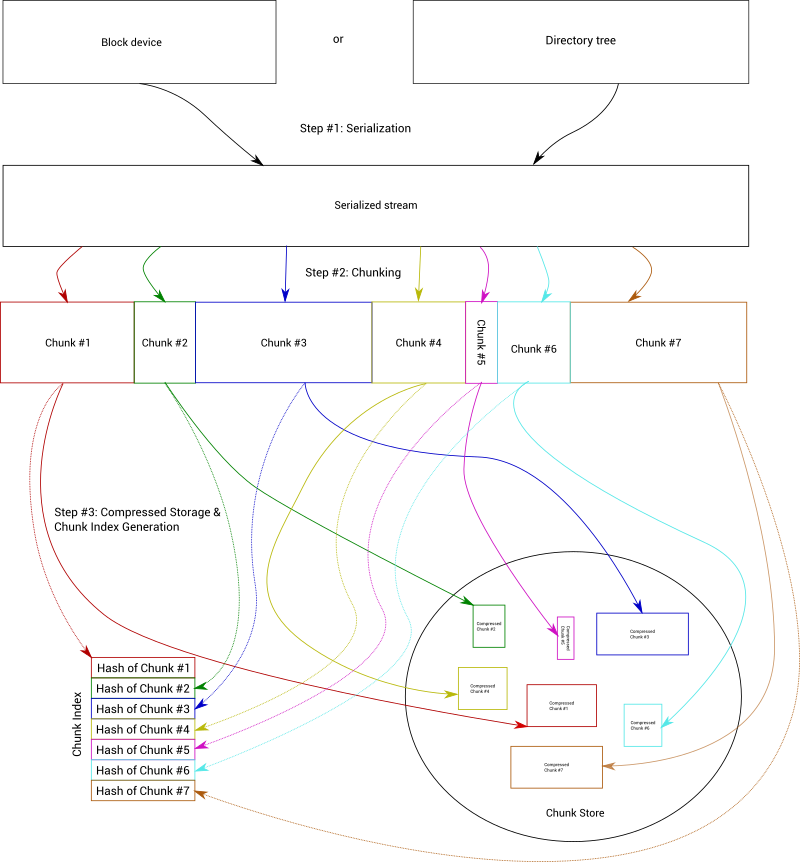
В casync алгоритм разбиения на блоки использует функцию Buzhash. Это хеш циклическими полиномами, который использует только быстрые побитовые операции и подходит для скользящего хеширования. В качестве сильного хеша для генерации дайджестов используется SHA512/256 (альтернатива: SHA256). Для сжатия отдельных фрагментов используется вышеупомянутый формат zstd от Facebook (альтернатива: xz или gzip).
Кроме того, разработчик ввёл более чёткий собственный формат сериализации деревьев каталогов с произвольным доступом (как он выражается, «современный tar»).
Всё это повышает процент дедупликации. В конечном итоге, эта программа максимально сжимает данные, особенно если у нас много однотипных версий. Она идеально для хранения и передачи файлов.
Примеры команд casync
Как показано на рисунке выше, программа кодирует поток данных или файловую систему, разбивает файлы на фрагменты (чанки), генерирует индекс — и складывает чанки в хранилище. С этим хранилищем мы можем работать через хеши (из индекса).
Грубо говоря, у себя на сервере мы можем хранить не сами файлы, а лишь хеши соответствующих фрагментов — и передавать клиенту только их.
Использовать программу максимально просто:
$ casync make foobar.caidx /some/directory— генерация индексаfoobar.caidxдля всех файлов в указанной директории. Автоматически создаётся хранилище фрагментов в локальной директории,$ casync extract foobar.caidx /some/other/directory— реконструкция оригинального дерева директорий из индекса и хранилища фрагментов,$ casync extract http://example.com/images/foobar.caidx /some/other/directory— то же самое, только индекс берётся не локально, а с удалённого сервера (там же должно лежать хранилище фрагментов),$ casync mount http://example.comf/images/foobar.caidx /mnt/foobar— примонтировать индекс хешей к локальной файловой системе без извлечения файлов.
Разработчики позаимствовали лучшие оптимизации из других алгоритмов дедупликации, в том числе BorgBackup, bup, CAFS, dedupfs, LBFS, restic, Tahoe-LAFS, tarsnap, Venti, zsync. Всё это по сути разновидности rsync (со скользящим хешем и блоками переменного размера), с имеющимися особенностями.
Сферы использования casync:
- Эффективное хранение множества версий файловой системы и каталогов.
- Эффективное обновление образов ОС, VM, IoT и контейнеров через интернет по HTTP и CDN.
- Эффективное резервное копирование.
То есть хранение, апдейты и бэкап.
Casync разрабатывался как универсальный инструмент синхронизации. В первую очередь — для передачи апдейтов ОС. При этом он не может генерировать дельты минимального размера, тут вообще без конкуренции Google Courgette (который в девять раз эффективнее bsdiff). Задача casync другая — найти некий компромисс между эффективной дедупликацией и удобством использования, без строгой необходимости контроля версий и прочих усложнений.
Да, casync похож на rsync, zsync, git и всех остальных, перечисленных выше. Но не является полноценной заменой. У них разная семантика и способы использования.
Сейчас автор хочет расширить область применения. Чтобы в полной мере охватить резервное копирование, нужно добавить шифрование — и тогда программа станет реальной альтернативой tarsnap, BorgBackup и restic.
Какое решение применяете вы?
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
Habrahabr.ru прочитано 42677 раз
