
Книга «Apache Kafka. Потоковая обработка и анализ данных»
 При работе любого enterprise-приложения образуются данные: это файлы логов, метрики, информация об активности пользователей, исходящие сообщения и т. п. Правильные манипуляции над всеми этими данными не менее важны, чем сами данные. Если вы — архитектор, разработчик или выпускающий инженер, желающий решать подобные проблемы, но пока не знакомы с Apache Kafka, то именно из этой замечательной книги вы узнаете, как работать с этой свободной потоковой платформой, позволяющей обрабатывать очереди данных в реальном времени.
При работе любого enterprise-приложения образуются данные: это файлы логов, метрики, информация об активности пользователей, исходящие сообщения и т. п. Правильные манипуляции над всеми этими данными не менее важны, чем сами данные. Если вы — архитектор, разработчик или выпускающий инженер, желающий решать подобные проблемы, но пока не знакомы с Apache Kafka, то именно из этой замечательной книги вы узнаете, как работать с этой свободной потоковой платформой, позволяющей обрабатывать очереди данных в реальном времени.
Для кого предназначена эта книга
«Apache Kafka. Потоковая обработка и анализ данных» написана для разработчиков, использующих в своей работе API Kafka, а также инженеров-технологов (именуемых также SRE, DevOps или системными администраторами), занимающихся установкой, конфигурацией, настройкой и мониторингом ее работы при промышленной эксплуатации. Мы не забывали также об архитекторах данных и инженерах-аналитиках — тех, кто отвечает за проектирование и создание всей инфраструктуры данных компании. Некоторые главы, в частности 3, 4 и 11, ориентированы на Java-разработчиков. Для их усвоения важно, чтобы читатель был знаком с основами языка программирования Java, включая такие вопросы, как обработка исключений и конкурентность.
В других главах, особенно 2, 8, 9 и 10, предполагается, что у читателя есть опыт работы с Linux и он знаком с настройкой сети и хранилищ данных на Linux. В оставшейся части книги Kafka и архитектуры программного обеспечения обсуждаются в более общих чертах, поэтому каких-то специальных познаний от читателей не требуется.
Еще одна категория людей, которых может заинтересовать данная книга, — руководители и архитекторы, работающие не непосредственно с Kafka, а с теми, кто работает с ней. Ничуть не менее важно, чтобы они понимали, каковы предоставляемые платформой гарантии и в чем могут заключаться компромиссы, на которые придется идти их подчиненным и сослуживцам при создании основанных на Kafka систем. Эта книга будет полезна тем руководителям, которые хотели бы обучить своих сотрудников работе с Kafka или убедиться, что команда разработчиков владеет нужной информацией.
Глава 2. Установка Kafka
Apache Kafka представляет собой Java-приложение, которое может работать на множестве операционных систем, в числе которых Windows, MacOS, Linux и др. В этой главе мы сосредоточимся на установке Kafka в среде Linux, поскольку именно на этой операционной системе платформу устанавливают чаще всего. Linux также является рекомендуемой операционной системой для развертывания Kafka общего назначения. Информацию по установке Kafka на Windows и MacOS вы найдете в приложении A.
Установить Java
Прежде чем установить ZooKeeper или Kafka, необходимо установить и настроить среду Java. Рекомендуется использовать Java 8, причем это может быть версия, как включенная в вашу операционную систему, так и непосредственно загруженная с сайта java.com. Хотя ZooKeeper и Kafka будут работать с Java Runtime Edition, при разработке утилит и приложений удобнее использовать полный Java Development Kit (JDK). Приведенные шаги установки предполагают, что у вас в каталоге /usr/java/jdk1.8.0_51 установлен JDK версии 8.0.51.
Установить ZooKeeper
Apache Kafka использует ZooKeeper для хранения метаданных о кластере Kafka, а также подробностей о клиентах-потребителях (рис. 2.1). Хотя ZooKeeper можно запустить и с помощью сценариев, включенных в дистрибутив Kafka, установка полной версии хранилища ZooKeeper из дистрибутива очень проста.

Kafka была тщательно протестирована со стабильной версией 3.4.6 хранилища ZooKeeper, которую можно скачать с сайта apache.org.
Автономный сервер
Следующий пример демонстрирует установку ZooKeeper с базовыми настройками в каталог /usr/local/zookeeper с сохранением данных в каталоге /var/lib/zookeeper:
# tar -zxf zookeeper-3.4.6.tar.gz
# mv zookeeper-3.4.6 /usr/local/zookeeper
# mkdir -p /var/lib/zookeeper
# cat > /usr/local/zookeeper/conf/zoo.cfg << EOF
> tickTime=2000
> dataDir=/var/lib/zookeeper
> clientPort=2181
> EOF
# /usr/local/zookeeper/bin/zkServer.sh start
JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
# export JAVA_HOME=/usr/java/jdk1.8.0_51
# /usr/local/zookeeper/bin/zkServer.sh start
JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
#
Теперь можете проверить, что ZooKeeper как полагается работает в автономном режиме, подключившись к порту клиента и отправив четырехбуквенную команду srvr:
# telnet localhost 2181
Trying ::1...
Connected to localhost.
Escape character is '^]'.
srvr
Zookeeper version: 3.4.6-1569965, built on 02/20/2014 09:09 GMT
Latency min/avg/max: 0/0/0
Received: 1
Sent: 0
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: standalone
Node count: 4
Connection closed by foreign host.
#
Ансамбль ZooKeeper
Кластер ZooKeeper называется ансамблем (ensemble). Из-за особенностей самого алгоритма рекомендуется, чтобы ансамбль включал нечетное число серверов, например, 3, 5 и т. д., поскольку для того, чтобы ZooKeeper мог отвечать на запросы, должно функционировать большинство членов ансамбля (кворум). Это значит, что ансамбль из трех узлов может работать и при одном неработающем узле. Если в ансамбле три узла, таких может быть два.
Для настройки работы серверов ZooKeeper в ансамбле у них должна быть единая конфигурация со списком всех серверов, а у каждого сервера в каталоге данных должен иметься файл myid с идентификатором этого сервера. Если хосты в ансамбле носят названия zoo1.example.com, zoo2.example.com и zoo3.example.com, то файл конфигурации может выглядеть приблизительно так:
tickTime=2000
dataDir=/var/lib/zookeeper
clientPort=2181
initLimit=20
syncLimit=5
server.1=zoo1.example.com:2888:3888
server.2=zoo2.example.com:2888:3888
server.3=zoo3.example.com:2888:3888
В этой конфигурации initLimit представляет собой промежуток времени, на протяжении которого ведомые узлы могут подключаться к ведущему. Значение syncLimit ограничивает отставание ведомых узлов от ведущего. Оба значения задаются в единицах tickTime, то есть initLimit = 20 · 2000 мс = 40 с. В конфигурации также перечисляются все серверы ансамбля. Они приводятся в формате server.X=hostname: peerPort: leaderPort со следующими параметрами:
- X — идентификатор сервера. Обязан быть целым числом, но отсчет может вестись не от нуля и не быть последовательным;
- hostname — имя хоста или IP-адрес сервера;
- peerPort — TCP-порт, через который серверы ансамбля взаимодействуют друг с другом;
- leaderPort — TCP-порт, через который осуществляется выбор ведущего узла.
Достаточно, чтобы клиенты могли подключаться к ансамблю через порт clientPort, но участники ансамбля должны иметь возможность обмениваться сообщениями друг с другом по всем трем портам.
Помимо единого файла конфигурации у каждого сервера в каталоге dataDir должен быть файл myid. Он должен содержать идентификатор сервера, соответствующий приведенному в файле конфигурации. После завершения этих шагов можно запустить серверы, и они будут взаимодействовать друг с другом в ансамбле.
Установка брокера Kafka
После завершения настройки Java и ZooKeeper можно приступать к установке Apache Kafka. Актуальный выпуск Apache Kafka можно скачать по адресу kafka.apache.org/downloads.html.
В следующем примере установим платформу Kafka в каталог /usr/local/kafka, настроив ее для использования запущенного ранее сервера ZooKeeper и сохранения сегментов журнала сообщений в каталоге /tmp/kafka-logs:
# tar -zxf kafka_2.11-0.9.0.1.tgz
# mv kafka_2.11-0.9.0.1 /usr/local/kafka
# mkdir /tmp/kafka-logs
# export JAVA_HOME=/usr/java/jdk1.8.0_51
# /usr/local/kafka/bin/kafka-server-start.sh -daemon
/usr/local/kafka/config/server.properties
#
После запуска брокера Kafka можно проверить его функционирование, выполнив какие-либо простые операции с кластером, включающие создание тестовой темы, генерацию сообщений и их потребление.
Создание и проверка темы:
# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181
--replication-factor 1 --partitions 1 --topic test
Created topic "test".
# /usr/local/kafka/bin/kafka-topics.sh --zookeeper localhost:2181
--describe --topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
#
Генерация сообщений для темы test:
# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list
localhost:9092 --topic test
Test Message 1
Test Message 2
^D
#
Потребление сообщений из темы test:
# /usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper
localhost:2181 --topic test --from-beginning
Test Message 1
Test Message 2
^C
Consumed 2 messages
#
Конфигурация брокера
Пример конфигурации брокера, поставляемый вместе с дистрибутивом Kafka, вполне подойдет для пробного запуска автономного сервера, но для большинства установок его будет недостаточно. Существует множество параметров конфигурации Kafka, регулирующих все аспекты установки и настройки. Для многих из них можно оставить значения по умолчанию, поскольку они относятся к нюансам настройки брокера Kafka, не применяемым до тех пор, пока вы не будете работать с требующим их использования конкретным сценарием.
Основные настройки брокера
Существует несколько настроек брокера Kafka, которые желательно обдумать при развертывании платформы в любой среде, кроме автономного брокера на отдельном сервере. Эти параметры относятся к основным настройкам брокера, и большинство из них нужно обязательно поменять, чтобы брокер мог работать в кластере с другими брокерами.
broker.id
У каждого брокера Kafka должен быть целочисленный идентификатор, задаваемый посредством параметра broker.id. По умолчанию это значение равно 0, но может быть любым числом. Главное, чтобы оно не повторялось в пределах одного кластера Kafka. Выбор числа может быть произвольным, причем при необходимости ради удобства сопровождения его можно переносить с одного брокера на другой. Желательно, чтобы это число было как-то связано с хостом, тогда более прозрачным окажется соответствие идентификаторов брокеров хостам при сопровождении. Например, если у вас имена хостов содержат уникальные числа (например, host1.example.com, host2.example.com и т. д.), эти числа будут удачным выбором для значений broker.id.
port
Типовой файл конфигурации запускает Kafka с прослушивателем на TCP-порту 9092. Этот порт можно изменить на любой другой доступный путем изменения параметра конфигурации port. Имейте в виду, что при выборе порта с номером менее 1024 Kafka должна запускаться от имени пользователя root. А запускать Kafka от имени пользователя root не рекомендуется.
zookeeper.connect
Путь, который ZooKeeper использует для хранения метаданных брокеров, задается с помощью параметра конфигурации zookeeper.connect. В образце конфигурации ZooKeeper работает на порту 2181 на локальной хост-машине, что указывается как localhost:2181. Формат этого параметра — разделенный точками с запятой список строк вида hostname: port/path, включающий:
- hostname — имя хоста или IP-адрес сервера ZooKeeper;
- port — номер порта клиента для сервера;
- /path — необязательный путь ZooKeeper, используемый в качестве нового корневого (chroot) пути кластера Kafka. Если он не задан, используется корневой путь.
Если заданный путь chroot не существует, он будет создан при запуске брокера.
log.dirs
Kafka сохраняет все сообщения на жесткий диск, и хранятся эти сегменты журналов в каталогах, задаваемых в настройке log.dirs. Она представляет собой разделенный запятыми список путей в локальной системе. Если задано несколько путей, брокер будет сохранять разделы в них по принципу наименее используемых, с сохранением сегментов журналов одного раздела по одному пути. Отметим, что брокер поместит новый раздел в каталог, в котором в настоящий момент хранится меньше всего разделов, а не используется меньше всего пространства, так что равномерное распределение данных по разделам не гарантируется.
num.recovery.threads.per.data.dir
Для обработки сегментов журналов Kafka использует настраиваемый пул потоков выполнения. В настоящий момент он применяется:
- при обычном запуске — для открытия сегментов журналов каждого из разделов;
- запуске после сбоя — для проверки и усечения сегментов журналов каждого из разделов;
- останове — для аккуратного закрытия сегментов журналов.
По умолчанию задействуется только один поток на каждый каталог журналов. Поскольку это происходит только при запуске и останове, имеет смысл использовать большее их количество, чтобы распараллелить операции. При восстановлении после некорректного останова выгоды от применения такого подхода могут достичь нескольких часов в случае перезапуска брокера с большим числом разделов! Помните, что значение этого параметра определяется из расчета на один каталог журналов из числа задаваемых с помощью log.dirs. То есть если значение параметра num.recovery.threads.per.data.dir равно 8, а в log.dirs указаны три пути, то общее число потоков — 24.
auto.create.topics.enable
В соответствии с конфигурацией Kafka по умолчанию брокер должен автоматически создавать тему, когда:
- производитель начинает писать в тему сообщения;
- потребитель начинает читать из темы сообщения;
- любой клиент запрашивает метаданные темы.
Во многих случаях такое поведение может оказаться нежелательным, особенно из-за того, что не существует возможности проверить по протоколу Kafka существование темы, не вызвав ее создания. Если вы управляете созданием тем явным образом, вручную или посредством системы инициализации, то можете установить для параметра auto.create.topics.enable значение false.
Настройки тем по умолчанию
Конфигурация сервера Kafka задает множество настроек по умолчанию для создаваемых тем. Некоторые из этих параметров, включая число разделов и параметры сохранения сообщений, можно задавать для каждой темы отдельно с помощью инструментов администратора (рассматриваются в главе 9). Значения по умолчанию в конфигурации сервера следует устанавливать равными эталонным значениям, подходящим для большинства тем кластера.
num.partitions
Параметр num.partitions определяет, с каким количеством разделов создается новая тема, главным образом в том случае, когда включено автоматическое создание тем (что является поведением по умолчанию). Значение этого параметра по умолчанию — 1. Имейте в виду, что количество разделов для темы можно лишь увеличивать, но не уменьшать. Это значит, что если для нее требуется меньше разделов, чем указано в num.partitions, придется аккуратно создать ее вручную (это обсуждается в главе 9).
Как говорилось в главе 1, разделы представляют собой способ масштабирования тем в кластере Kafka, поэтому важно, чтобы их было столько, сколько нужно для уравновешивания нагрузки по сообщениям в масштабах всего кластера по мере добавления брокеров. Многие пользователи предпочитают, чтобы число разделов было равно числу брокеров в кластере или кратно ему. Это дает возможность равномерно распределять разделы по брокерам, что приведет к равномерному распределению нагрузки по сообщениям. Однако это не обязательное требование, ведь и наличие нескольких тем позволяет выравнивать нагрузку.
log.retention.ms
Чаще всего продолжительность хранения сообщений в Kafka ограничивается по времени. Значение по умолчанию указано в файле конфигурации с помощью параметра log.retention.hours и равно 168 часам, или 1 неделе. Однако можно использовать и два других параметра — log.retention.minutes и log.retention.ms. Все эти три параметра определяют одно и то же — промежуток времени, по истечении которого сообщения удаляются. Но рекомендуется использовать параметр log.retention.ms, ведь в случае указания нескольких параметров приоритет принадлежит наименьшей единице измерения, так что всегда будет использоваться значение log.retention.ms.
log.retention.bytes
Еще один способ ограничения срока действия сообщений — на основе общего размера (в байтах) сохраняемых сообщений. Значение задается с помощью параметра log.retention.bytes и применяется пораздельно. Это значит, что в случае темы из восьми разделов и равного 1 Гбайт значения log.retention.bytes максимальный объем сохраняемых для этой темы данных будет 8 Гбайт. Отметим, что объем сохранения зависит от отдельных разделов, а не от темы. Это значит, что в случае увеличения числа разделов для темы максимальный объем сохраняемых при использовании log.retention.bytes данных также возрастет.
log.segment.bytes
Упомянутые настройки сохранения журналов касаются сегментов журналов, а не отдельных сообщений. По мере генерации сообщений брокером Kafka они добавляются в конец текущего сегмента журнала соответствующего раздела. По достижении сегментом журнала размера, задаваемого параметром log.segment.bytes и равного по умолчанию 1 Гбайт, этот сегмент закрывается и открывается новый. После закрытия сегмент журнала можно выводить из обращения. Чем меньше размер сегментов журнала, тем чаще приходится закрывать файлы и создавать новые, что снижает общую эффективность операций записи на диск.
Подбор размера сегментов журнала важен в случае, когда темы отличаются низкой частотой генерации сообщений. Например, если в тему поступает лишь 100 Мбайт сообщений в день, а для параметра log.segment.bytes установлено значение по умолчанию, для заполнения одного сегмента потребуется 10 дней. А поскольку сообщения нельзя объявить недействительными до тех пор, пока сегмент журнала не закрыт, то при значении 604 800 000 (1 неделя) параметра log.retention.ms к моменту вывода из обращения закрытого сегмента журнала могут скопиться сообщения за 17 дней. Это происходит потому, что при закрытии сегмента с накопившимися за 10 дней сообщениями его приходится хранить еще 7 дней, прежде чем можно будет вывести из обращения в соответствии с принятыми временными правилами, поскольку сегмент нельзя удалить до того, как окончится срок действия последнего сообщения в нем.
log.segment.ms
Другой способ управления закрытием сегментов журнала — с помощью параметра log.segment.ms, задающего отрезок времени, по истечении которого сегмент журнала закрывается. Как и параметры log.retention.bytes и log.retention.ms, параметры log.segment.bytes и log.segment.ms не являются взаимоисключающими. Kafka закрывает сегмент журнала, когда или истекает промежуток времени, или достигается заданное ограничение по размеру, в зависимости от того, какое из этих событий произойдет первым. По умолчанию значение параметра log.segment.ms не задано, в результате чего закрытие сегментов журналов обусловливается их размером.
message.max.bytes
Брокер Kafka позволяет с помощью параметра message.max.bytes ограничивать максимальный размер генерируемых сообщений. Значение этого параметра по умолчанию равно 1 000 000 (1 Мбайт). Производитель, который попытается отправить сообщение большего размера, получит от брокера извещение об ошибке, а сообщение принято не будет. Как и в случае всех остальных размеров в байтах, указываемых в настройках брокера, речь идет о размере сжатого сообщения, так что производители могут отправлять сообщения, размер которых в несжатом виде гораздо больше, если их можно сжать до задаваемых параметром message.max.bytes пределов.
Увеличение допустимого размера сообщения серьезно влияет на производительность. Больший размер сообщений означает, что потоки брокера, обрабатывающие сетевые соединения и запросы, будут заниматься каждым запросом дольше. Также бо'льшие сообщения увеличивают объем записываемых на диск данных, что влияет на пропускную способность ввода/вывода.
Выбор аппаратного обеспечения
Выбор подходящего аппаратного обеспечения для брокера Kafka — скорее искусство, чем наука. У самой платформы Kafka нет каких-либо строгих требований к аппаратному обеспечению, она будет работать без проблем на любой системе. Но если говорить о производительности, то на нее влияют несколько факторов: емкость и пропускная способность дисков, оперативная память, сеть и CPU.
Сначала нужно определиться с тем, какие типы производительности важнее всего для вашей системы, после чего можно будет выбрать оптимальную конфигурацию аппаратного обеспечения, вписывающуюся в бюджет.
Пропускная способность дисков
Пропускная способность дисков брокера, которые используются для хранения сегментов журналов, самым непосредственным образом влияет на производительность клиентов-производителей. Сообщения Kafka должны фиксироваться в локальном хранилище, которое бы подтверждало их запись. Лишь после этого можно считать операцию отправки успешной. Это значит, что чем быстрее выполняются операции записи на диск, тем меньше будет задержка генерации сообщений.
Очевидное действие при возникновении проблем с пропускной способностью дисков — использовать жесткие диски с раскручивающимися пластинами (HDD) или твердотельные накопители (SSD). У SSD на порядки ниже время поиска/доступа и выше производительность. HDD же более экономичны и обладают более высокой относительной емкостью. Производительность HDD можно улучшить за счет большего их числа в брокере, или используя несколько каталогов данных, или устанавливая диски в массив независимых дисков с избыточностью (redundant array of independent disks, RAID). На пропускную способность влияют и другие факторы, например, технология изготовления жесткого диска (к примеру, SAS или SATA), а также характеристики контроллера жесткого диска.
Емкость диска
Емкость — еще один аспект хранения. Необходимый объем дискового пространства определяется тем, сколько сообщений необходимо хранить одновременно. Если ожидается, что брокер будет получать 1 Тбайт трафика в день, то при 7-дневном хранении ему понадобится доступное для использования хранилище для сегментов журнала объемом минимум 7 Тбайт. Следует также учесть перерасход как минимум 10% для других файлов, не считая буфера для возможных колебаний трафика или роста его с течением времени.
Емкость хранилища — один из факторов, которые необходимо учитывать при определении оптимального размера кластера Kafka и принятии решения о его расширении. Общий трафик кластера можно балансировать за счет нескольких разделов для каждой темы, что позволяет использовать дополнительные брокеры для наращивания доступной емкости в случаях, когда плотности данных на одного брокера недостаточно. Решение о том, сколько необходимо дискового пространства, определяется также выбранной для кластера стратегией репликации (подробнее обсуждается в главе 6).
Память
В обычном режиме функционирования потребитель Kafka читает из конца раздела, причем потребитель постоянно наверстывает упущенное и лишь незначительно отстает от производителей, если вообще отстает. При этом читаемые потребителем сообщения сохраняются оптимальным образом в страничном кэше системы, благодаря чему операции чтения выполняются быстрее, чем если бы брокеру приходилось перечитывать их с диска. Следовательно, чем больший объем оперативной памяти доступен для страничного кэша, тем выше быстродействие клиентов-потребителей.
Для самой Kafka не требуется выделения для JVM большого объема оперативной памяти в куче. Даже брокер, который обрабатывает X сообщений в секунду при скорости передачи данных X мегабит в секунду, может работать с кучей в 5 Гбайт. Остальная оперативная память системы будет применяться для страничного кэша и станет приносить Kafka пользу за счет возможности кэширования используемых сегментов журналов. Именно поэтому не рекомендуется располагать Kafka в системе, где уже работают другие важные приложения, так как им придется делиться страничным кэшем, что снизит производительность потребителей Kafka.
Передача данных по сети
Максимальный объем трафика, который может обработать Kafka, определяется доступной пропускной способностью сети. Зачастую это ключевой (наряду с объемом дискового хранилища) фактор выбора размера кластера. Затрудняет этот выбор присущий Kafka (вследствие поддержки нескольких потребителей) дисбаланс между входящим и исходящим сетевым трафиком. Производитель может генерировать 1 Мбайт сообщений в секунду для заданной темы, но количество потребителей может оказаться каким угодно, привнося соответствующий множитель для исходящего трафика. Повышают требования к сети и другие операции, такие как репликация кластера (см. главу 6) и зеркальное копирование (обсуждается в главе 8). При интенсивном использовании сетевого интерфейса вполне возможно отставание репликации кластера, что вызовет неустойчивость его состояния.
CPU
Вычислительные мощности не так важны, как дисковое пространство и оперативная память, но они тоже в некоторой степени влияют на общую производительность брокера. В идеале клиенты должны сжимать сообщения ради оптимизации использования сети и дискового пространства. Брокер Kafka, однако, должен разархивировать все пакеты сообщений для проверки контрольных сумм отдельных сообщений и назначения смещений. Затем ему нужно снова сжать пакет сообщений для сохранения его на диске. Именно для этого Kafka требуется бо'льшая часть вычислительных мощностей. Однако не следует рассматривать это как основной фактор при выборе аппаратного обеспечения.
Kafka в облачной среде
Kafka часто устанавливают в облачной вычислительной среде, например, Amazon Web Services (AWS). AWS предоставляет множество виртуальных вычислительных узлов, все с различными комбинациями CPU, оперативной памяти и дискового пространства. Для выбора подходящей конфигурации виртуального узла нужно учесть в первую очередь факторы производительности Kafka. Начать можно с необходимого объема хранения данных, после чего учесть требуемую производительность генераторов. В случае потребности в очень низкой задержке могут понадобиться виртуальные узлы с оптимизацией по операциям ввода/вывода с локальными хранилищами на основе SSD. В противном случае может оказаться достаточно удаленного хранилища (например, AWS Elastic Block Store). После принятия этих решений можно будет выбрать из числа доступных вариантов CPU и оперативной памяти.
На практике это означает, что в случае задействования AWS можно выбрать виртуальные узлы типов m4 или r3. Виртуальный узел типа m4 допускает более длительное хранение, но при меньшей пропускной способности записи на диск, поскольку основан на адаптивном блочном хранилище. Пропускная способность виртуального узла типа r3 намного выше благодаря использованию локальных SSD-дисков, но последние ограничивают доступный для хранения объем данных. Преимущества обоих этих вариантов сочетают существенно более дорогостоящие типы виртуальных узлов i2 и d2.
Кластеры Kafka
Отдельный сервер Kafka хорошо подходит для локальной разработки или создания прототипов систем, но настроить несколько брокеров для совместной работы в виде кластера намного выгоднее (рис. 2.2). Основная выгода от этого — возможность масштабировать нагрузку на несколько серверов. Вторая по значимости — возможность использования репликации для защиты от потери данных вследствие отказов отдельных систем. Репликация также дает возможность выполнить работы по обслуживанию Kafka или нижележащей системы с сохранением доступности для клиентов. В этом разделе мы рассмотрим только настройку кластера Kafka. Более подробную информацию о репликации данных вы найдете в главе 6.
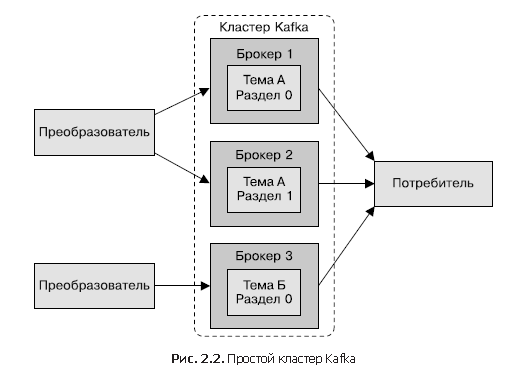
Сколько должно быть брокеров?
Размер кластера Kafka определяется несколькими факторами. Первый из них — требующийся для хранения сообщений объем дискового пространства и объем доступного места на отдельном брокере. Если кластеру необходимо хранить 10 Тбайт данных, а отдельный брокер может хранить 2 Тбайт, то минимальный размер кластера — пять брокеров. Кроме того, использование репликации может повысить требования к хранилищу минимум на 100% (в зависимости от ее коэффициента) (см. главу 6). Это значит, что при использовании репликации тот же кластер должен будет содержать как минимум десять брокеров.
Еще один фактор, который нужно учесть, — возможности кластера по обработке запросов. Например, каковы возможности сетевых интерфейсов и способны ли они справиться с трафиком клиентов при нескольких потребителях данных или колебаниями трафика на протяжении хранения данных (то есть в случае всплесков трафика в период пиковой нагрузки). Если сетевой интерфейс отдельного брокера используется на 80% при пиковой нагрузке, а потребителя данных два, то они не смогут справиться с пиковым трафиком при менее чем двух брокерах. Если в кластере используется репликация, она играет роль дополнительного потребителя данных, который необходимо учесть. Может быть полезно увеличить количество брокеров в кластере, чтобы справиться с проблемами производительности, вызванными понижением пропускной способности дисков или объема доступной оперативной памяти.
Конфигурация брокеров
Есть только два требования к конфигурации брокеров при их работе в составе одного кластера Kafka. Первое — в конфигурации всех брокеров должно быть одинаковое значение параметра zookeeper.connect. Он задает ансамбль ZooKeeper и путь хранения кластером метаданных. Второе — у каждого из брокеров кластера должно быть уникальное значение параметра broker.id. Если два брокера с одинаковым значением broker.id попытаются присоединиться к кластеру, то второй брокер запишет в журнал сообщение об ошибке и не запустится. Существуют и другие параметры конфигурации брокеров, используемые при работе кластера, а именно параметры для управления репликацией, описываемые в дальнейших главах.
Тонкая настройка операционной системы
Хотя в большинстве дистрибутивов Linux есть готовые конфигурации параметров конфигурации ядра, которые довольно хорошо подходят для большинства приложений, можно внести в них несколько изменений для повышения производительности брокера Kafka. В основном они относятся к подсистемам виртуальной памяти и сети, а также специфическим моментам, касающимся точки монтирования диска для сохранения сегментов журналов. Эти параметры обычно настраиваются в файле /etc/sysctl.conf, но лучше обратиться к документации конкретного дистрибутива Linux, чтобы выяснить все нюансы корректировки настроек ядра.
Виртуальная память
Обычно система виртуальной памяти Linux сама подстраивается под нагрузку системы. Но можно внести некоторые корректировки в работу как с областью подкачки, так и с «грязными» страницами памяти, чтобы лучше приспособить ее к специфике нагрузки Kafka.
Как и для большинства приложений, особенно тех, где важна пропускная способность, лучше избегать подкачки (практически) любой ценой. Затраты, обусловленные подкачкой страниц памяти на диск, существенно влияют на все аспекты производительности Kafka. Кроме того, Kafka активно использует системный страничный кэш, и если подсистема виртуальной памяти выполняет подкачку на диск, то страничному кэшу выделяется недостаточное количество памяти.
Один из способов избежать подкачки — не выделять в настройках никакого места для нее. Подкачка — не обязательное требование, а скорее страховка на случай какой-либо аварии в системе. Она может спасти от неожиданного прерывания системой выполнения процесса вследствие нехватки памяти. Поэтому рекомендуется делать значение параметра vm.swappiness очень маленьким, например 1. Этот параметр представляет собой вероятность (в процентах) того, что подсистема виртуальной памяти воспользуется подкачкой вместо удаления страниц из страничного кэша. Лучше уменьшить размер страничного кэша, чем использовать подкачку.
Корректировка того, что ядро системы делает с «грязными» страницами, которые должны быть сброшены на диск, также имеет смысл. Быстрота ответа Kafka производителям зависит от производительности дисковых операций ввода/вывода. Именно поэтому сегменты журналов обычно размещаются на быстрых дисках: или отдельных дисках с быстрым временем отклика (например, SSD), или дисковых подсистемах с большим объемом NVRAM для кэширования (например, RAID). В результате появляется возможность уменьшить число «грязных» страниц, по достижении которого запускается фоновый сброс их на диск. Для этого необходимо задать значение параметра vm.dirty_background_ratio меньшее, чем значение по умолчанию (равно 10). Оно означает долю всей памяти системы (в процентах), и во многих случаях его можно задать равным 5. Однако не следует делать его равным 0, поскольку в этом случае ядро начнет непрерывно сбрасывать страницы на диск и тем самым потеряет возможность буферизации дисковых операций записи при временных флуктуациях производительности нижележащих аппаратных компонентов.
Общее количество «грязных» страниц, при превышении которого ядро системы принудительно инициирует запуск синхронных операций по сбросу их на диск, можно повысить и увеличением параметра vm.dirty_ratio до значения, превышающего значение по умолчанию — 20 (тоже доля в процентах от всего объема памяти системы). Существует широкий диапазон возможных значений этого параметра, но наиболее разумные располагаются между 60 и 80. Изменение этого параметра является несколько рискованным в смысле как объема не сброшенных на диск действий, так и вероятности возникновения длительных пауз ввода/вывода в случае принудительного запуска синхронных операций сброса. При выборе более высоких значений параметра vm.dirty_ratio настойчиво рекомендуется использовать репликацию в кластере Kafka, чтобы защититься от системных сбоев.
При выборе значений этих параметров имеет смысл контролировать количество «грязных» страниц в ходе работы кластера Kafka под нагрузкой при промышленной эксплуатации или имитационном моделировании. Определить его можно с помощью просмотра файла /proc/vmstat:
# cat /proc/vmstat | egrep "dirty|writeback"
nr_dirty 3875
nr_writeback 29
nr_writeback_temp 0
#
Диск
Если не считать выбора аппаратного обеспечения подсистемы жестких дисков, а также конфигурации RAID-массива в случае его использования, сильнее всего влияет на производительность применяемая для этих дисков файловая система. Существует множество разных файловых систем, но в качестве локальной чаще всего задействуется EXT4 (fourth extended file system — четвертая расширенная файловая система) или XFS (Extents File System — файловая система на основе экстентов). EXT4 работает довольно хорошо, но требует потенциально небезопасных параметров тонкой настройки. Среди них установка более длительного интервала фиксации, чем значение по умолчанию (5), с целью понижения частоты сброса на диск. В EXT4 также появилось отложенное выделение блоков, повышающее вероятность потери данных и повреждения файловой системы в случае системного отказа. В файловой системе XFS также используется алгоритм отложенного выделения, но более безопасный, чем в EXT4. Производительность XFS для типичной нагрузки Kafka тоже выш
Habrahabr.ru прочитано 40174 раза
