
[Перевод] Еще раз о перформансе стримов в Java
Время от времени я наблюдаю или даже бываю втянутым в спор о перформансе стримов в джаве. Общеизвестно, что стримы это компромисс между перформансом и удобством. Однако я не нашел вменяемого набора бенчмарков, которые бы показали, насколько именно медленны (или быстры) стримы. Поэтому я решил написать эти бенчмарки сам.
Что и как проверяли
Я измерил перформанс нескольких типичных юзкейсов для цикла forEach: применение некой функции к множеству, суммирование, фильтрация и группировка. В общем рутинные задачи. Те же задачи были решены через стримы.
Над выбором тула для бенчмарка долго думать не пришлось. JMH — проверенное в бою решение, развиваемое под эгидой команды OpenJDK. Фреймворк очень гибкий и простой в использовании.
Полный код тестов можно найти на Github.
Бенчмарки запускалиcь на 4-ядерной виртуальной машине на Java 21 с параметрами JVM: -Xms2G -Xmx2G. Операции выполнялись на листах размером 1000, 10 000, 100 000, 1 000 000. Для каждого кейса использованы как последовательные, так и параллельные стримы.
Результаты представлены на графиках как проценты от лучшего результата в пределах размера выборки. Графики нормализованы таким образом, что для заданного размера списка находится лучший результат среди различных реализаций, и каждый результат делится на него. Лучший результат — 100%. Оценка 50% означает, что эта реализация наполовину «медленнее», чем лучшая в данном тесте.
Суммирование целых чисел
Код
@State(Scope.Benchmark)
public static class Params {
@Param({"1000", "10000", "100000", "1000000"})
public int size;
public List items;
@Setup
public void setUp() {
items = IntStream.range(0, size)
.mapToObj(i -> i)
.collect(Collectors.toList());
}
}
@Benchmark
public int forEach(Params params) {
int res = 0;
for (Integer item : params.items) {
res += item;
}
return res;
}
@Benchmark
public int collect(Params params) {
return params.items.stream()
.collect(Collectors.summingInt(i -> i));
}
@Benchmark
public int collectPar(Params params) {
return params.items.parallelStream()
.collect(Collectors.summingInt(i -> i));
}
@Benchmark
public int reduce(Params params) {
return params.items.stream()
.reduce(0, Integer::sum);
}
@Benchmark
public int reducePar(Params params) {
return params.items.parallelStream()
.reduce(0, Integer::sum);
}
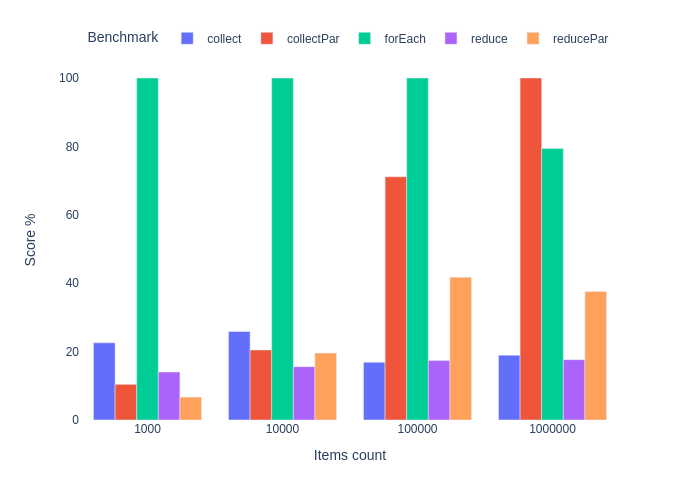
Суммирование целых чисел
Это было ожидаемо. Мы имеем победителя в лице forEach, но его преимущество падает с ростом размера коллекции. Особенно в сравнении с параллельным стримом. Подход сreduce самый медленный и даже распараллеливание не спасает ситуацию.
Если ваша программа по какой-то причине крутится вокруг суммирования целых чисел, то отдайте предпочтение классике. Если это звучит саркастично, то так оно и есть. На практике весь выигрыш в перформансе теряется в мире REST API, микросервисов и event driven архитектур. Если мы заменим Stream.collect() на forEach в рестовом сервисе, который суммирует целые и складывает результат в базу данных, то мы, возможно, выиграем какие-то десятые доли микросекунд, которые потеряются на фоне сериализации, десериализации, передаче «по проводу», обращению к БД и т.д.
Вычисление и суммирование
Давайте рассмотрим чуть более реалистичный пример. Выполним математическую операцию на коллекции случайно сгенерированных чисел с плавающией точкой и сложим результат.
Код
@State(Scope.Benchmark)
public static class Params {
@Param({"1000", "10000", "100000", "1000000"})
public int size;
public List items;
@Setup
public void setUp() {
Random random = new Random();
items = random.doubles(size).mapToObj(i -> i)
.collect(Collectors.toList());
}
}
private static double calculate(double value) {
return Math.sqrt(Math.sin(Math.log(value)));
}
@Benchmark
public Double forEach(Params params) {
Double res = 0d;
for (Double item : params.items) {
res += calculate(item);
}
return res;
}
@Benchmark
public Double collect(Params params) {
return params.items.stream()
.map(DoubleCalculationBenchmark::calculate)
.collect(Collectors.summingDouble(i -> i));
}
@Benchmark
public Double collectPar(Params params) {
return params.items.parallelStream()
.map(DoubleCalculationBenchmark::calculate)
.collect(Collectors.summingDouble(i -> i));
}
@Benchmark
public Double reduce(Params params) {
return params.items.stream()
.map(DoubleCalculationBenchmark::calculate)
.reduce(0d, Double::sum);
}
@Benchmark
public Double reducePar(Params params) {
return params.items.parallelStream()
.map(DoubleCalculationBenchmark::calculate)
.reduce(0d, Double::sum);
} 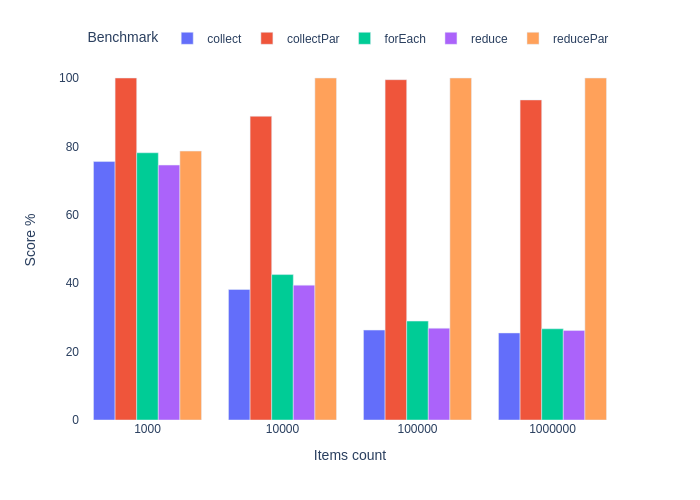
Вычисление и суммирование
Что ж, сюрприз. Результат forEach плюс-минус такой же, как и у последовательного стрима. Параллельный же стрим вырывается вперед на больших коллекциях и работает в 3–5 раз быстрее. Это объясняется довольно просто.
Этого не было видно в предыдущем бенчмарке, т.к. чем бОльшая часть программы выполняется последовательно, тем такая программа хуже распараллеливается. См. закон Амдала. Это как раз случай суммирования. Сложение двух чисел — очень быстрая операция, поэтому мы потратили больше времени на распараллеливание и последующую синхронизацию результата. Особенно в случае небольших коллекций.
Тот же принцип привел к немного лучшему перформансу функции reduce в этом бенчмарке. Эта функция высшего порядка принимает бинарные ассоциативные функции без побочных эффектов, работающие с иммутабельными объектами. Double.sum() попадает под это определение. Если мы выполняет этот контракт, то объединение результатов отлично распараллеливается и не требует синхронизации.
Группировка
Группировка с помощью стримов поистине лаконична и наглядна, поэтому широко используется в повседневных задачах. На результат влияет много факторов: стрим может быть последовательным или паралельным, упорядоченным или неупорядоченным. Мы имеем несколько опций выбора коллектора, или вообще можем использовать Stream.reduce() вместо Stream.collect() . Также можем использовать разные вспомогательные структуры данных и контейнеры, куда будут помещены результаты группировки. Поэтому далее так много кода.
Собственно задача бенчмарка: взять лист случайно сгенерированных чисел с плавающей точкой и сгруппировать результат по результату деления на 10, округленного до целого. Тип результата — Map
Код
static final double DIVISOR = 100.0;
@State(Scope.Benchmark)
public static class Params {
@Param({"1000", "10000", "100000", "1000000"})
public int size;
public List items;
@Setup
public void setUp() {
Random random = new Random();
items = random.doubles(size)
.mapToObj(i -> i)
.collect(Collectors.toList());
}
}
@Benchmark
public Map> forEach(Params params) {
Map> res = new HashMap<>();
for (Double item : params.items) {
Long key = Math.round(item / DIVISOR);
List list = res.get(key);
if (list != null) {
list.add(item);
} else {
list = new ArrayList<>();
list.add(item);
res.put(key, list);
}
}
return res;
}
@Benchmark
public Map> forEachLinked(Params params) {
Map> res = new HashMap<>();
for (Double item : params.items) {
Long key = Math.round(item / DIVISOR);
List list = res.get(key);
if (list != null) {
list.add(item);
} else {
list = new LinkedList<>();
list.add(item);
res.put(key, list);
}
}
return res;
}
@Benchmark
public Map> forEachLinkedCompute(Params params) {
Map> res = new HashMap<>();
for (Double item : params.items) {
res.compute(Math.round(item / DIVISOR), (k, v) -> {
if (v == null) {
LinkedList list = new LinkedList<>();
list.add(item);
return list;
}
v.add(item);
return v;
});
}
return res;
}
@Benchmark
public Map> collect(Params params) {
return params.items.stream()
.collect(Collectors
.groupingBy(n -> Math.round(n / DIVISOR)));
}
@Benchmark
public Map> collectLinked(Params params) {
return params.items.stream()
.collect(Collectors.groupingBy(
n -> Math.round(n / DIVISOR),
Collectors.toCollection(LinkedList::new)));
}
@Benchmark
public Map> collectPar(Params params) {
return params.items.parallelStream()
.collect(Collectors
.groupingBy(n -> Math.round(n / DIVISOR)));
}
@Benchmark
public Map> collectParLinked(Params params) {
return params.items.parallelStream()
.collect(Collectors.groupingBy(
n -> Math.round(n / DIVISOR),
Collectors.toCollection(LinkedList::new)));
}
@Benchmark
public Map> collectParOpt(Params params) {
return params.items.parallelStream()
.unordered()
.collect(Collectors.groupingByConcurrent(
n -> Math.round(n / DIVISOR),
Collectors.toCollection(LinkedList::new)));
}
@Benchmark
public io.vavr.collection.HashMap> reducePar(Params params) {
return params.items.parallelStream()
.reduce(
io.vavr.collection.HashMap.empty(),
(m, n) -> {
Long key = Math.round(n / DIVISOR);
return m.put(key, m.get(key)
.map(l -> l.prepend(n))
.getOrElse(() -> io.vavr.collection.List.of(n)));
},
(l, r) -> l.merge(r, io.vavr.collection.List::prependAll));
}
@Benchmark
public io.vavr.collection.HashMap> reduceParUnord(Params params) {
return params.items.parallelStream()
.unordered()
.reduce(
io.vavr.collection.HashMap.empty(),
(m, n) -> {
Long key = Math.round(n / DIVISOR);
return m.put(key, m.get(key)
.map(l -> l.prepend(n))
.getOrElse(() -> io.vavr.collection.List.of(n)));
},
(l, r) -> l.merge(r, io.vavr.collection.List::prependAll));
} 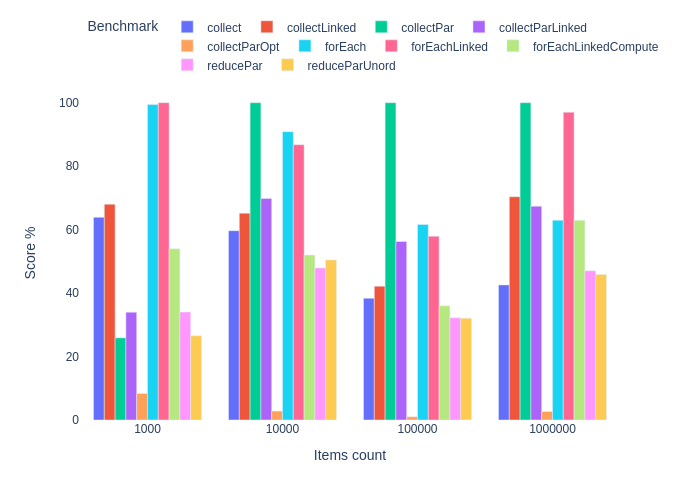
Группировка
Среди последовательных реализаций forEach немного быстрее стримов, группирующих результат в Map . Использование LinkedList в теории может улучшить результат, но не для параллельных стримов. На деле при использовании Collectors.toCollection (LinkedList: new) наблюдается серьезная потеря производительности.
Для испытания Stream.reduce() на параллельных стримах мы должны использовать иммутабельные структуры. Обычная HashMap — мутабельная, поэтому на помощь спешат Map и List из библиотеки Vavr. Правда, без особого успеха. Честно говоря, я ждал большего от reduce на параллельных стримах, но потом я понял, что ожидания были беспочвенными. У Map из Varv функции get и put имеют константную сложность, но нам приходится каждый раз вызывать их обе, т.к. нет удобной функции Map.compute(), как в стандартном API.
Мне не хотелось бы делать существенных выводов относительно причин достигнутых результатов. Собранных данных недостаточно. На вопрос «стримы или не стримы», похоже, есть следующие ответы. Если нас волнует производительность на уровне микросекунд, мы должны использовать последовательный forEach или параллельный Stream.collect() . И нам лучше оставить попытки преждевременной оптимизации, если мы не собираемся проверять их в реальных сценариях.
Фильтрация и сортировка
Еще один юзкейс для стримов — фильтрация, сортировка и выборка уникальных элементов из коллекции. Конечно, не всегда всё вместе. Бенчмарк берет случайные числа, фильтрует их по попаданию между минимальным и максимальным значениями, выбирает уникальные значения и сортирует в натуральном порядке.
Код
static final double MIN = 0.0;
static final double MAX = 10.0;
@State(Scope.Benchmark)
public static class Params {
@Param({"1000", "10000", "100000", "1000000"})
public int size;
public List items;
@Setup
public void setUp() {
Random random = new Random();
List values = random.doubles(500, MIN, MAX + 5)
.mapToObj(i -> i)
.collect(Collectors.toList());
items = random.ints(size, 0, values.size())
.mapToObj(values::get)
.collect(Collectors.toList());
}
}
@Benchmark
public Collection forEach(Params params) {
Set set = new HashSet<>();
for (Double item : params.items) {
if (item > MIN && item < MAX) {
set.add(item);
}
}
List res = new ArrayList<>(set);
Collections.sort(res);
return res;
}
@Benchmark
public Collection forEachTreeSet(Params params) {
Set set = new TreeSet<>();
for (Double item : params.items) {
if (item > MIN && item < MAX) {
set.add(item);
}
}
return set;
}
@Benchmark
public Collection collect(Params params) {
return params.items.stream()
.filter(n -> n > MIN && n < MAX)
.distinct()
.sorted()
.collect(Collectors.toList());
}
@Benchmark
public Collection collectPar(Params params) {
return params.items.parallelStream()
.filter(n -> n > MIN && n < MAX)
.distinct()
.sorted()
.collect(Collectors.toList());
} 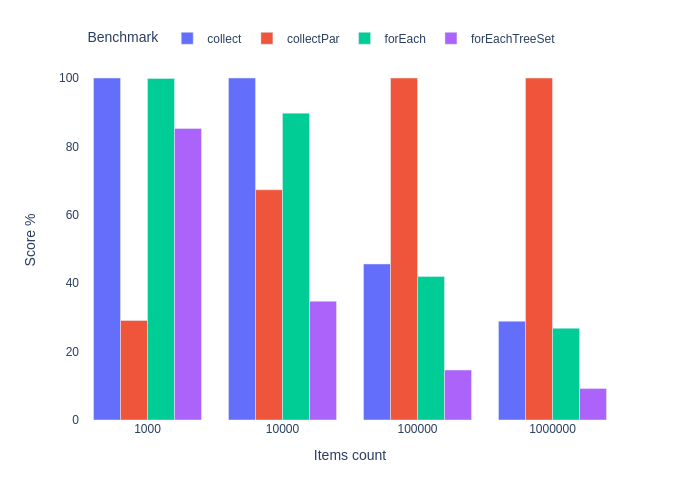
Фильтрация и сортировка
Видим знакомый паттерн: чем длиннее коллекция, тем эффективнее параллельные стримы. Попытка оптимизировать сортировку через TreeSet не имела успеха.
Заключение
Похоже, обойдемся без откровений. Стримы в разных ситуациях могут быть и быстрее и медленнее императивных циклов. И я действительно рад, что стримы в целом хороши. По крайней мере в области ежедневных задач в энтерпрайзе. Если бы я был вынужден прекратить использования стримов из-за слабого перфоманса, мне бы не хватало этой красивой и наглядной абстракции.
Один момент, оставшийся без внимания. Все параллельные стримы используют один и тот же ForkJoinPool (если только вы не задали пул явно — прим. пер.). Все слышали, что поэтому мы должны быть осторожнее при массовом использовании параллельных стримов -, но что сказали бы цифры?
Апдейт
В комментариях меня спросили насчет влияния JIT-компилятора на перформанс forEach. Ниже результаты прогонов бенчмарка с выключенным JIT-компилятором (параметр JVM -Xint)
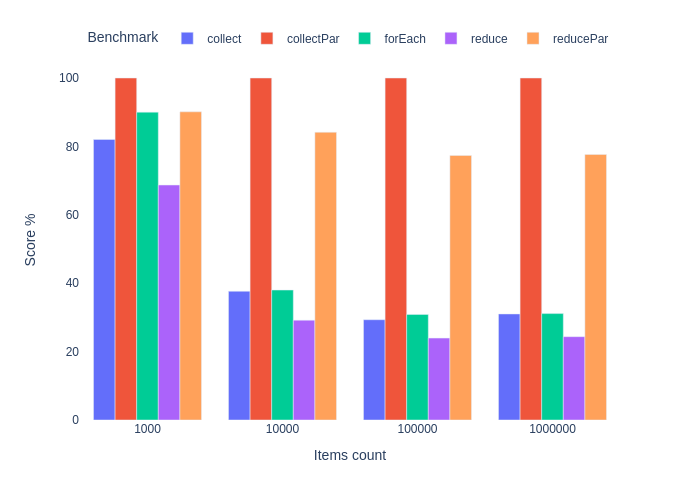
Суммирование. JIT выключен
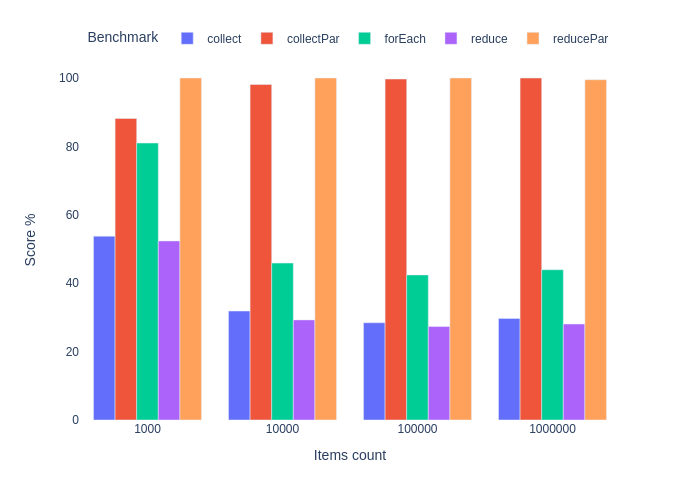
Вычисление и суммирование. JIT вылючен.
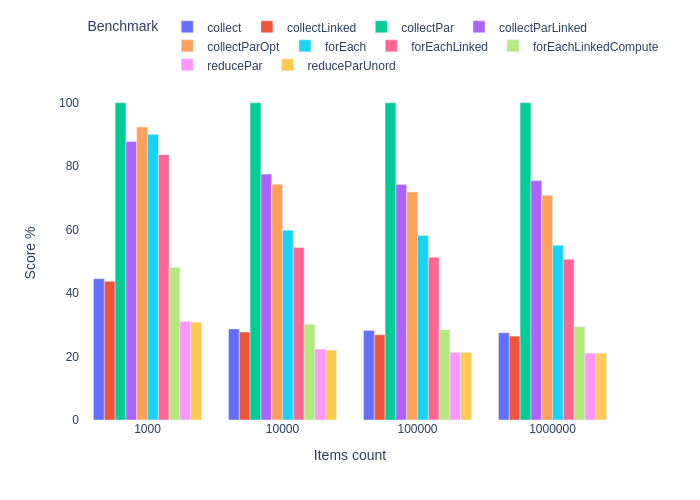
Группировка. JIT выключен.
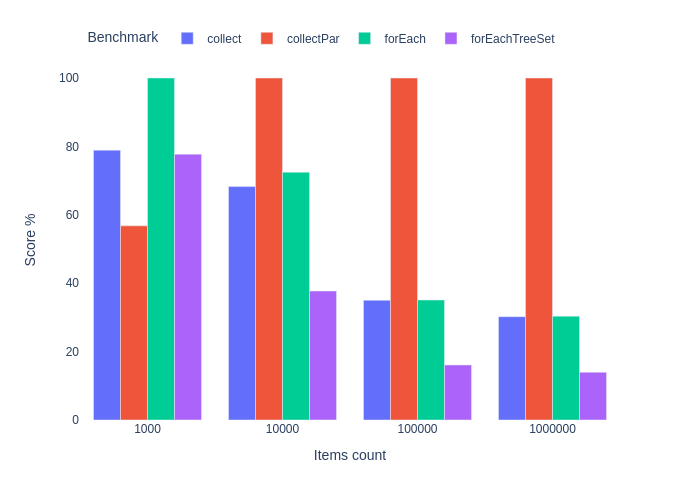
Фильтрация и сортировка. JIT выключен.
Habrahabr.ru прочитано 41560 раз
