
Векторное представление товаров Prod2Vec: как мы улучшили матчинг и избавились от кучи эмбеддингов
Привет! Меня зовут Александр, я работаю в команде матчинга Ozon. Ежедневно мы имеем дело с десятками миллионов товаров, и наша задача — поиск и сопоставление одинаковых предложений (нахождение матчей) на нашей площадке, чтобы вы не видели бесконечную ленту одинаковых товаров.
На странице любого товара на Ozon есть картинки, заголовок, описание и дополнительные атрибуты. Всю эту информацию мы хотим извлекать и обрабатывать для решения разных задач. И особенно она важна для команды матчинга.
Чтобы извлекать признаки из товара, мы строим его векторные представления (эмбеддинги), используя различные текстовые модели (fastText, трансформеры) для описаний и заголовков и целый набор архитектур свёрточных сетей (ResNet, Effnet, NFNet) — для картинок. Далее эти векторы используются для генерации фичей и товарного сопоставления.
На Ozon ежедневно появляются миллионы обновлений — и считать эмбеддинги для всех моделей становится проблематично. А что, если вместо этого (где каждый вектор описывает отдельную часть товара) мы получим один вектор для всего товара сразу? Звучит неплохо, только как бы это грамотно реализовать…
Чтобы построить векторное представление товара, мы можем использовать:
- Контент — информацию о картинках, тексты, названия и атрибуты товара.
- Пользовательские сессии — история о том, какие товары смотрят/покупают наши пользователи.
Мы уже писали статью о том, как пытались подойти к задаче Prod2Vec на основе второго способа, а сегодня поговорим, как мы решили эту проблему первым (используя контент).

Схема
Помимо того, что такая архитектура может быть полезной для рекомендаций, поиска, матчинга, она позволяет объединить всю информацию о товаре (картинки, заголовок, описания, атрибуты) в один вектор и, следовательно, упростить некоторые пайплайны (ранжирование, поиск и подбор кандидатов-товаров).
Архитектура
К данной задаче логично подойти со стороны Metric Learning: сближать похожие товары и отдалять разные, используя, например, triplet loss. Там есть много интересных вопросов (как семплировать негативы, что в данной задаче считать позитивными примерами, как грамотно собрать датасет), но, так как у нас уже есть некоторые модели подобного типа, мы решили подойти к проблеме с точки зрения supervised подхода — предсказания самого низкого уровня категории в категорийном дереве.
Каждый товар относится к целому дереву категорий — начиная с высокоуровневой (одежда, книги, электроника) и заканчивая низкоуровневой (шорты, кружки, чехлы для смартфонов). Таких низкоуровневых категорий у нас несколько тысяч.
Например, Электроника (cat1) → Телефоны, планшеты (cat2) → Смартфон Apple (cat3).

Для классификации такого большого количества категорий вместо обычного софтмакса (показавшего не очень хорошие результаты) мы решили попробовать подход, который изначально был предложен для задачи face recognition — ArcFace.
Классический софтмакс напрямую не влияет на близость выученных эмбеддингов внутри одного класса и отдалённость в разных. ArcFace же предназначен именно для этого: выбирая параметр margin penalty m, мы можем регулировать, насколько сильно мы хотим сближать/отдалять эмбеддинги одного/разных классов.
Первый вариант архитектуры модели выглядел так:
Различать для модели сразу cat3 оказалось слишком сложно: на каждой итерации мы пытаемся обучать и картиночную, и текстовую, и атрибутную модели по одному финальному лоссу CrossEntropy для cat3. Это приводило к тому, что их веса плохо и медленно сходились. Поэтому мы решили усовершенствовать модель:
- Из каждого энкодера, навешивая дополнительный слой с Softmax, получаем промежуточные выходы — предсказания cat1 (более высокоуровневой категории).
- Итоговый лосс — взвешенная сумма всех лоссов, причём сначала придаём больший вес лоссам cat1, а потом постепенно смещаем его в сторону лосса cat3.
В итоге получили следующую архитектуру:
В качестве коэффициента взвешивания берём обычную экспоненциальную функцию:
Во время инференса нас интересует уже не предсказание cat3, а векторное представление товара, поэтому мы берём выход слоя до ArcFace — это и есть нужный нам эмбеддинг.
Как готовим данные
Если просто взять категории всех товаров, то мы получим около 6000, при этом одни невероятно похожи (витаминно-минеральные комплексы и БАД), вторые вложены друг в друга (кофе капсульный и кофе), а третьи содержат слишком мало примеров товаров (физиотерапевтический аппарат).
Поэтому брать сырые категории в качестве таргета не вариант — пришлось сделать довольно объёмную предобработку, склеив похожие категории. В итоге получили датасет примерно 5 млн с 1300 категориями cat3 и минимумом 500 семплов на каждую категорию.
Сами данные обрабатывали следующим образом:
- Тексты привели к нижнему регистру и убрали лишние знаки.
- Картинки аугментировали стандартными способами (горизонтальные, вертикальные отображения, изменения яркости и контраста).
- Из атрибутов убрали те, которые не несут особого смысла и встречаются почти у всех товаров (например, серийный номер). После этого попробовали разные варианты: подавать на вход каждый атрибут «ключ: значение» отдельно или же все атрибуты объединить в одну строку. В итоге разницы особой не было, но второй вариант выглядел изящнее в пайплайне обучения, поэтому остановились на нём.
Процесс обучения
Мы решили посмотреть в сторону более лёгких архитектур, потому что данных получилось достаточно много, а в пайплайне обучения нужно было вместить две текстовые модели и одну — картиночную. В качестве CNN взяли ResNet34, а для текстов использовали два Rubert-Tiny — для заголовков и атрибутов (вот крутая статья про этот маленький трансформер).
Так как модели у нас и текстовые, и картиночные, для каждой мы настроили свой оптимизатор: AdamW — для бертов и SGD — для resnet и головы модели. Суммарно обучали 60 эпох: сначала 15 эпох с learning rate побольше, потом продолжили с меньшим, параллелили на GPU с помощью horovod.
В результате на валидации получили 85% Acc@1 и 94% Acc@5. Для сравнения: обученный на заголовках fastText давал точность 60% Acc@1.
Но, чтобы понять, получилось ли у нас сгенерировать хорошие эмбеддинги для товаров, точности предсказаний категорий недостаточно. Мы дополнительно использовали проджектор с 3D-визуализацией векторов: в нём можно выбрать разные способы понижения размерности и посмотреть, как наши векторы выглядят в проекции на сферу.
Вот, например, визуализации t-SNE и UMAP:
Если заглянуть поближе, то увидим, что в каждом кластере оказываются товары одной и той же категории:
А вот что происходит, если посмотреть на ближайших соседей товаров из пайплайна работы в продакшне:
Самое главное — время инференса ранжирующей модели кратно уменьшилось: используя эмбеддинги Prod2Vec вместо картиночных и текстовых, мы получили ускорение более чем в три раза:
Заключение и планы
Результаты нам понравились, мы запустили готовую архитектуру в продакшн — и теперь ежедневно насчитываем миллионы таких эмбеддингов через Spark Structured Streaming. Далее их можно смело подавать на вход в ранжирующую модель, получая в результате хороших кандидатов для матчей.
Помимо этого, эмбеддинги можно использовать в ряде других задач, которые возникают в нашей или смежных командах.
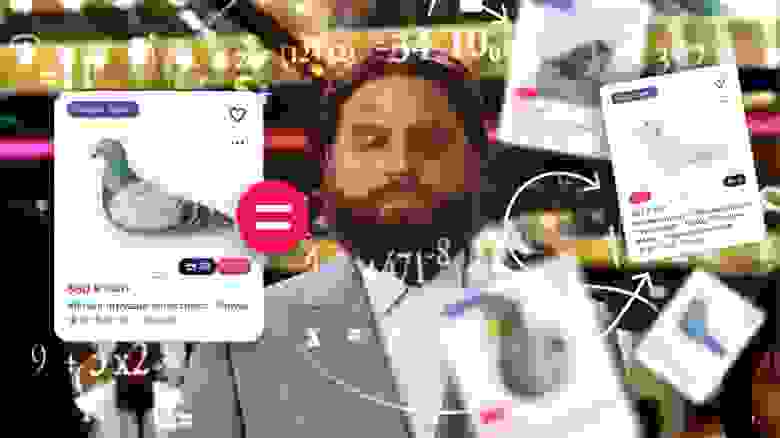
Вот так в том числе выглядит результат работы матчинга: если бы мы не склеили все предложения в одно, в ленте были бы видны три одинаковые карточки товара, что неудобно для пользователей.

Также остаётся открытым вопрос, насколько хорошо подобная архитектура будет работать, если обучить её с помощью Metric Learning. Всё это предстоит выяснить в дальнейшем.
Если вы делали что-то похожее или знаете, как можно по-другому подойти к решению подобной задачи, то приходите к нам в гости, пишите в комментариях или в ODS (alex_golubev) :)
А если вам интересно, как мы сделали большую часть ETL на базе Spark Structured Streaming, напишите в комментарии, — и мы подготовим про это отдельный пост :)
Habrahabr.ru прочитано 7986 раз
