
Системному администратору и нагрузочному тестировщику: статистика ввода-вывода в ядре Linux под капотом
 Автор статьи — Александр Пищулин
Автор статьи — Александр ПищулинИнженер-консультант по системам хранения данных
Подсчет статистики — это не сильно затратный с точки зрения производительности способ получить информацию о нагруженности системы с активным вводом-выводом. Но он имеет недостатки: усреднение, отсутствие бакетов, малая гранулярность системного таймера.
Нам, как конечным пользователям, будет полезно понимать, как устроен механизм сбора и накопления статистики внутри ядра и как читает и интерпретирует данные популярная утилита iostat. Что именно значат aqu-sz, util и другие данные из режима расширенной статистики? Почему многие значения усреднены? Чтобы ответить на эти и другие вопросы, мы пройдем путь от системного вызова до момента, когда запрос ушел в диск и вернулся, —, а счетчики обновились. Поехали!

Иллюстрация сгенерирована нейросетью
Материал подготовлен на базе ядра 5.15.
Для тех, кто любит смотреть видео: доклад на эту тему Александр рассказывал на Перфоманс конф #8.
Вводная. Как проходит операция ввода-вывода и какие структуры описывают основные сущности
1. Блочный стек ядра Linux
Прежде чем идти дальше, нам стоит познакомиться с блочным стеком ядра Linux. Это набор кода в поддиректории block исходного кода ядра. Он предоставляет абстрактный интерфейс доступа для взаимодействия с разнообразными физическими устройствами хранения.
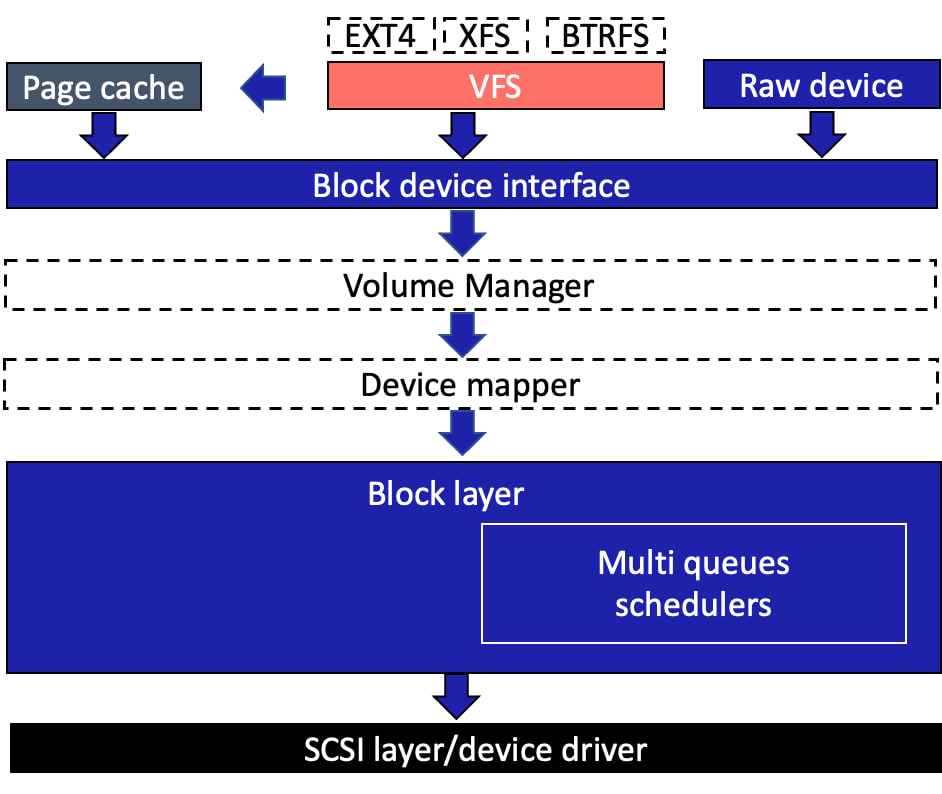
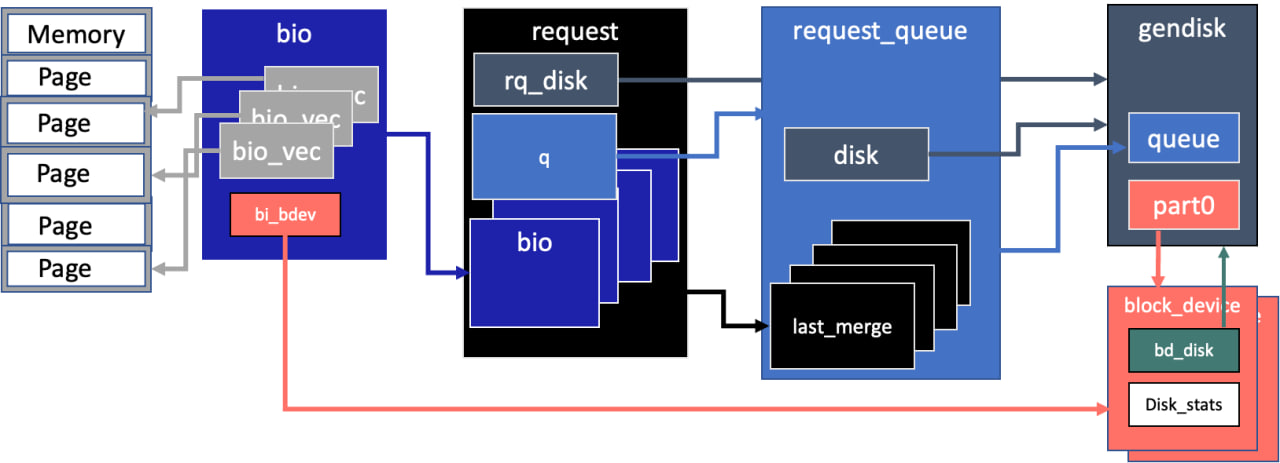
Путь данных через блочный стек
Вот как устроен путь данных через блочный стек. У нас есть:
Приложение, использующее прямой доступ к «сырому» устройству (raw device).
Файловая система или сама ОС, которые выгружают данные из страничного кэша (page cache).
Используя интерфейс доступа к диску, они передают данные либо в один из промежуточных уровней, реализованных вокруг device mapper (DM Crypt, LVM и т.п.), либо напрямую в блочный уровень — подсистему управления очередями.
Интерфейс доступа к блочному устройству описывается структурами gendisk (непосредственно устройство хранения) и blockdevice (таблица разделов) и представляет из себя файл устройства в директории /dev.
Фрагмент структуры gendisk:
struct gendisk {
…
int major; /* major number of driver */
int first_minor;
int minors;
/* maximum number of minors, =1 for disks that can't be partitioned. */
char disk_name[DISK_NAME_LEN];
/* name of major driver */
struct xarray part_tbl;
struct block_device *part0;
struct request_queue *queue;
…
};Фрагмент структуры blockdevice:
struct block_device {
...
struct disk_stats __percpu *bd_stats;
u8 bd_partno;
struct gendisk *bd_disk;
...
};Минимальной структурой, описывающей операцию ввода-вывода, является bio. Она описывает тип операции, содержит указатель на массив с пользовательскими данными в памяти и логически включается в запрос (request), как в единственном числе, так и в составе списка.
struct bio {
…
struct block_device *bi_bdev;
struct bvec_iter bi_iter;
unsigned short bi_vcnt; /* how many bio_vec's */
struct bio_vec bi_inline_vecs[];
…
};Стоит отметить, что bio не обязательно входит в состав запроса. Допускается реализация bio-based архитектуры, в таком случае система управления очередями не будет задействована.
Запрос (request) формируется на входе в блочный уровень (block layer). bio с пользовательскими данными включается в запрос. В зависимости от условий, запрос размещается либо в одной из очередей программной подготовки (software staging queue) для оптимизации слиянием, либо передаётся сразу в аппаратную очередь (hardware dispatch queue) — для передачи в устройство.
Фрагмент структуры request_queue:
struct request_queue {
struct request *last_merge;
…
struct blk_queue_stats *stats;
/* sw queues */
struct blk_mq_ctx __percpu *queue_ctx;
unsigned int queue_depth;
/* hw dispatch queues */
struct blk_mq_hw_ctx **queue_hw_ctx;
unsigned int nr_hw_queues;
struct gendisk *disk;
unsigned long nr_requests;
…
};Software staging queue пропускается при отсутствии планировщика (none) или готовности драйвера принять запрос — иначе говоря, если есть свободная hardware dispatch queue.
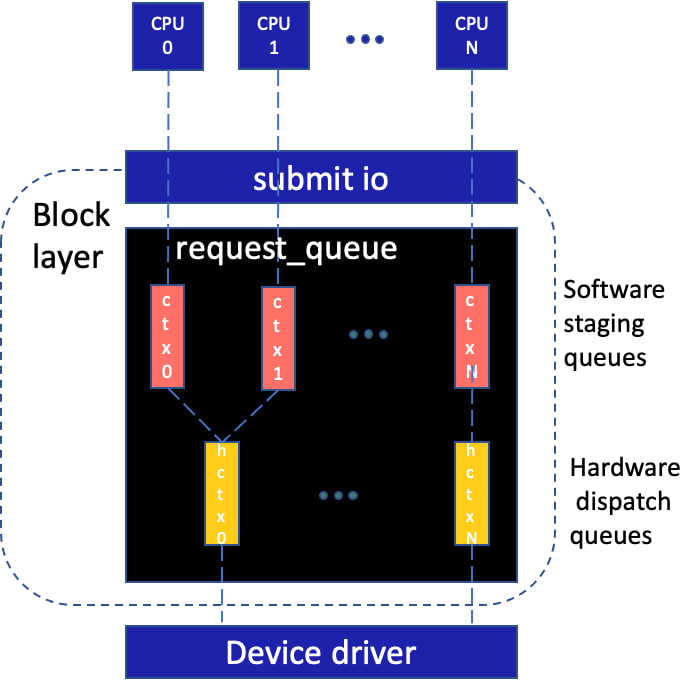
Двухуровневая архитектура блочного уровня
Для реализации системы управления с множеством очередей blk‑mq, которая является реализацией по умолчанию в ядрах 5.X, software staging queue создаётся для каждого CPU в системе. Количество hardware dispatch queueзависит от реализации драйвера.
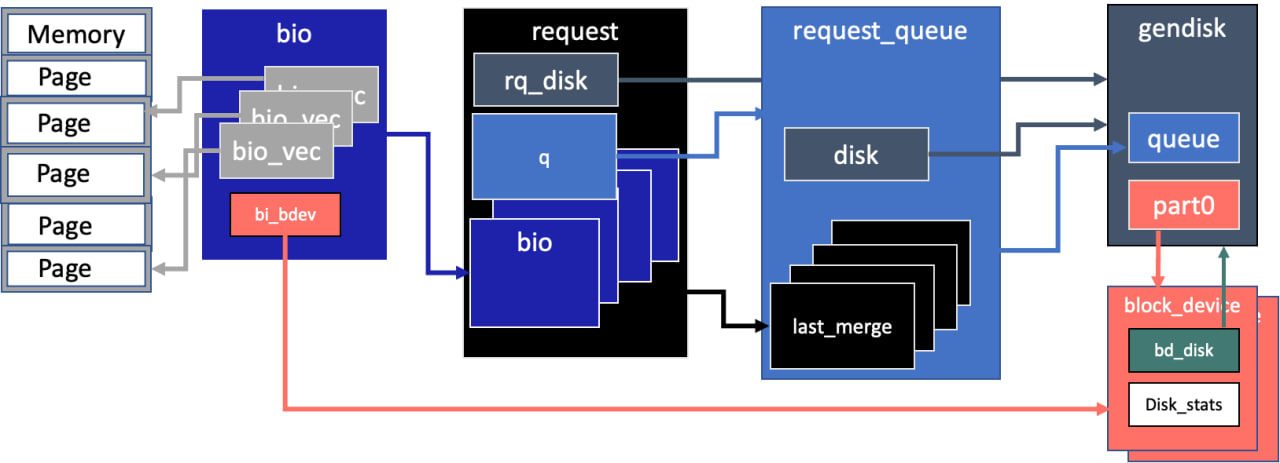
Взаимосвязь структур данных блочного стека
Обобщенная схема взаимосвязи основных структур блочного уровня будет выглядеть так:
Структура bio содержит указатели на данные в памяти.
Структура request содержит список bio, указатель на основное дисковое устройство и очередь, которой он принадлежит.
Структура request_queue содержит список запросов и указатель на основное дисковое устройство, которому принадлежит.
Структура gendisk содержит указатели на очередь запросов и на массив структур block_device, описывающий геометрию раздела.
2. Отправка запроса

Последовательность вызова функций ядра при отправке команды ввода-вывода
Приложение пишет в сырое устройство. Вслед за системным вызовом write в ядре вызывается функция blkdev_direct_IO, которая подготавливает структуру bio, заполняет её данными, а затем вызывает функцию submit_bio, передавая подготовленную структуру далее по стеку. Точкой входа в систему управления очередями служит функция blk_mq_submit_bio, которая принимает на входе структуру bio.
Если размер bio превышает максимальный для устройства, bio разделяется в функции __blk_queue_split и ее пытаются оптимизировать:
слиянием на этапе подключения к очереди (plugging []) в функции blk_mq_attempt_plug,
или слиянием c уже имеющимся запросом и bio внутри этого запроса в функции blk_mq_sched_bio_merge.
Если ни одна из оптимизаций не сработала, в функции _blk_mq_alloc_request выделяется память под структуру нового запроса, а в функции blk_mq_bio_to_request привязывается bio.
Далее, если задан один планировщиков ввода-вывода, запрос добавляется в очередь программной подготовки. Если планировщика нет, запрос отправляется сразу в нижележащее устройство.
3. Завершение запроса
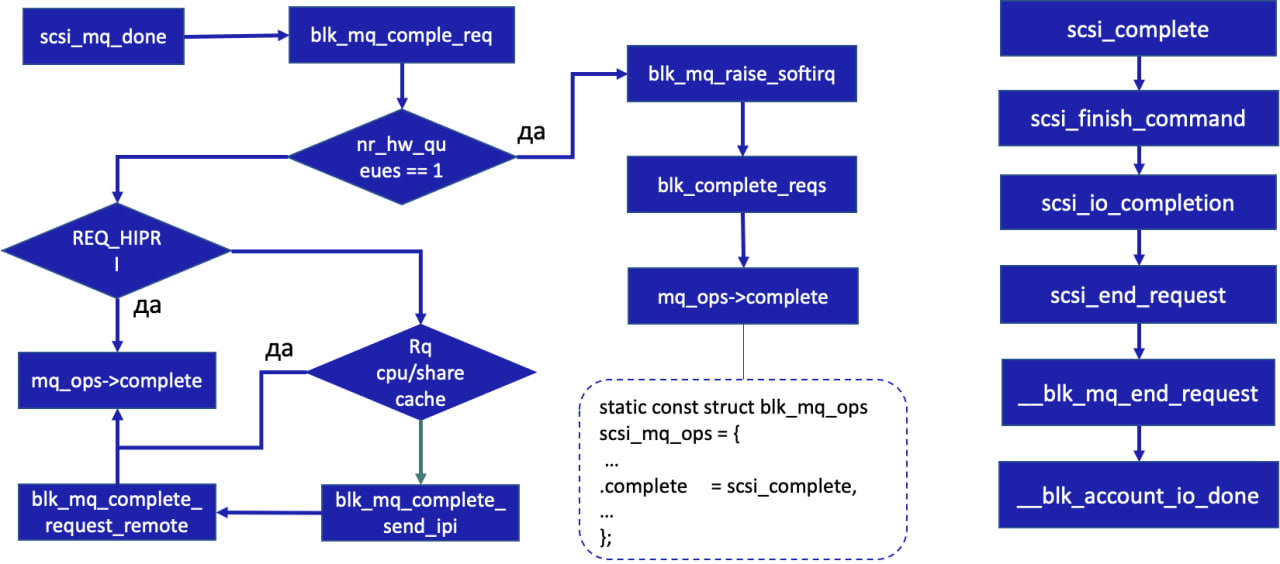
Последовательность вызова функций при завершении запроса
Когда нижележащий драйвер завершил выполнение операции, он вызывает функцию scsi_mq_done, которая, в свою очередь, вызывает blk_mq_complete_request.
Далее возможны варианты, зависящие от количества аппаратных очередей:
При одной аппаратной очереди выполняется программное прерывание. Оно вызывает функцию blk_complete_reqs, а внутри неё callback complete.
Если очередей больше одной и установлен флаг REQ_HIPRI, сразу вызывается callback функция complete. В случае scsi complete указывает на функцию scsi_complete, цепочка вызовов внутри которой приводит к __blk_mq_end_request — завершению выполнения запроса в блочном уровне.
Если очередей больше одной, но запрос имеет нормальный приоритет, всё зависит от того, на каком ядре была выполнена отправка запроса и где был произведен вызов scsi_mq_done. Если ядра совпадают, выполняется функция complete. В остальных случаях вызывается межпроцессороное прерывание и запрос завершается на том же ядре, где произведена его отправка.
Теперь, когда у нас есть общее понимание, о том, каким образом пользовательский запрос ввода-вывода проходит через блочный уровень, можно сфокусироваться непосредственно на механизме сбора и накопления статистики.
К делу! Как собирается и копится статистика ввода-вывода внутри ядра
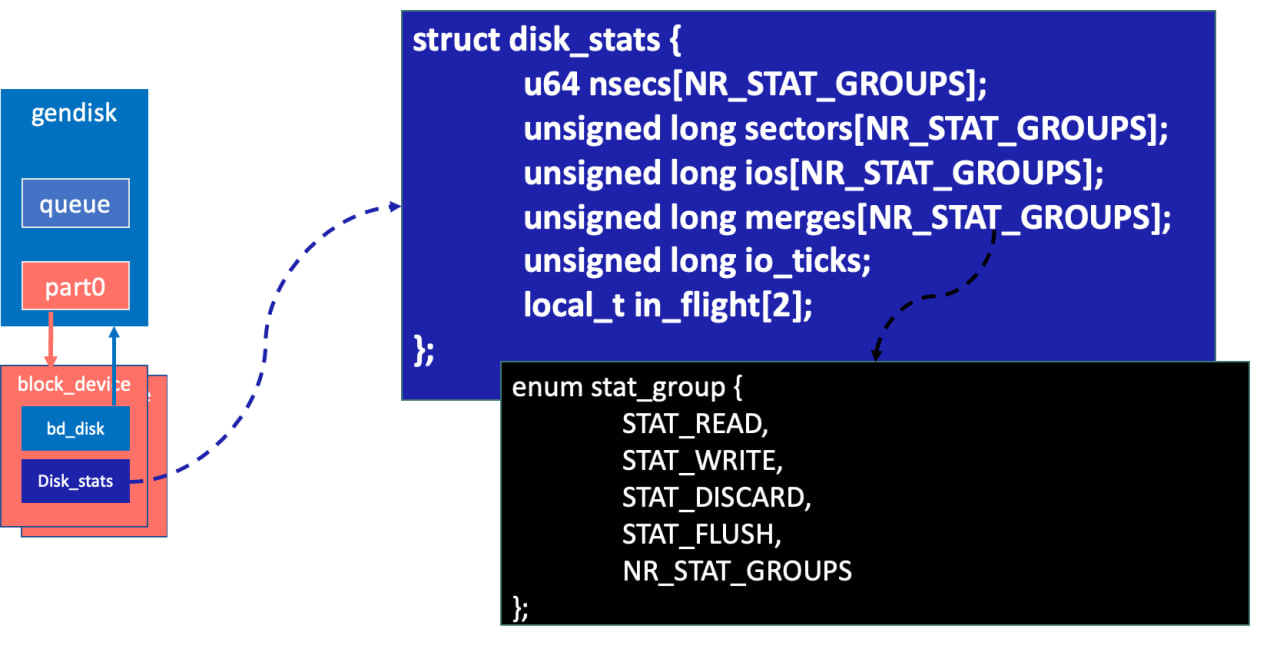
Вернемся на шаг назад, к блочному стеку. Каждая из структур block_device, описывающих патриции на физическом устройстве, включает в себя указатель на структуру disk_stats.
Поля структуры имеют следующие значения:
nsecs — суммарное время выполнения IO,
sectors — количество обслуженных секторов,
ios — количество операций ввода-вывода,
merges — количество слияний,
io_ticks — количество импульсов системного таймера,
in_flight[2] — количество операций в процессе выполнения ([0] — Read [1] — Write).
Все поля, кроме io_ticks, являются массивом. Каждый элемент массива соответствует определенному типу операции ввода-вывода.
Disk_stats представляет собой per-cpu структуру, для работы с которой реализован набор макросов. Он строится вокруг двух основных макросов — part_stat_add и part_stat_read:
#define __part_stat_add(part, field, addnd) \
__this_cpu_add((part)->bd_stats->field, addnd)
#define part_stat_add(part, field, addnd) do { \
__part_stat_add((part), field, addnd); \
if ((part)->bd_partno) \
__part_stat_add(bdev_whole(part), field, addnd); \
} while (0)
#define __part_stat_add(part, field, addnd) \
__this_cpu_add((part)->bd_stats->field, addnd)
#define part_stat_add(part, field, addnd) do { \
__part_stat_add((part), field, addnd); \
if ((part)->bd_partno) \
__part_stat_add(bdev_whole(part), field, addnd); \
} while (0)
#define part_stat_dec(part, field) \
part_stat_add(part, field, -1)
#define part_stat_inc(part, field) \
part_stat_add(part, field, 1)
#define part_stat_sub(part, field, subnd) \
part_stat_add(part, field, -subnd)
#define part_stat_read(part, field) \
({ \
typeof((part)->bd_stats->field) res = 0; \
unsigned int _cpu; \
for_each_possible_cpu(_cpu) \
res += per_cpu_ptr((part)->bd_stats, _cpu)->field; \
res;
})
1. Как обновляются счетчики в структуре disk_stats и как устроено чтение этих данных
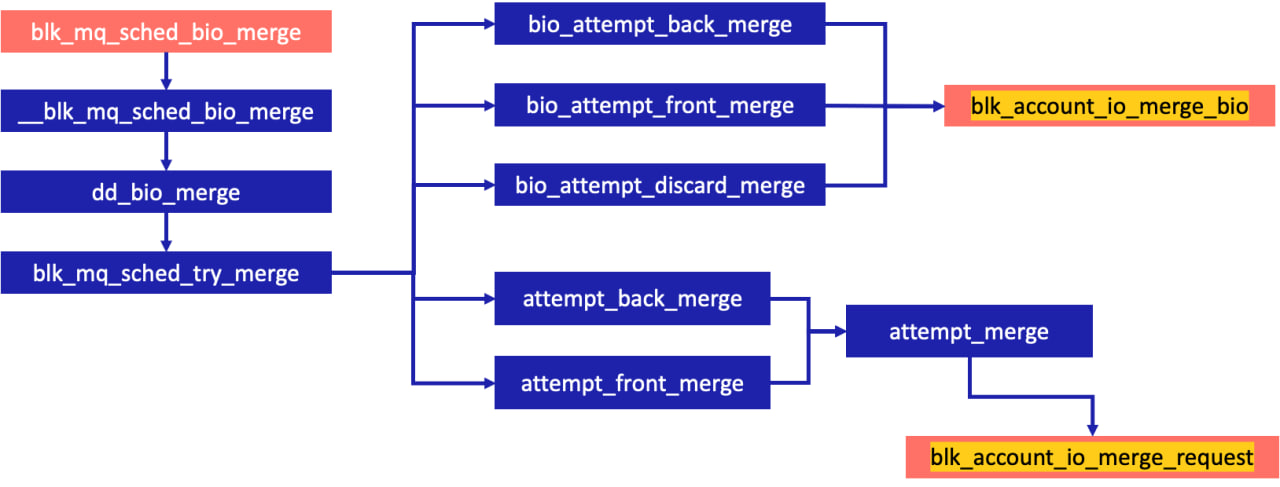
Подсчет количества слияний выполняется функциями blk_account_io_merge_bio и blk_account_io_merge_request:
static void blk_account_io_merge_bio(struct request *req)
{
if (!blk_do_io_stat(req))
return;
part_stat_lock();
part_stat_inc(req->part, merges[op_stat_group(req_op(req))]);
part_stat_unlock();
}
static void blk_account_io_merge_request(struct request *req)
{
if (blk_do_io_stat(req)) {
part_stat_lock();
part_stat_inc(req->part, merges[op_stat_group(req_op(req))]);
part_stat_unlock();
}
}Точки входа в функции оптимизации слиянием и подсчет слияния показаны ниже:

Так устроена последовательность вызова функций внутри blk_attempt_plug_merge:

Изменение счетчиков слияний на blk_mq_sched_bio_merge.
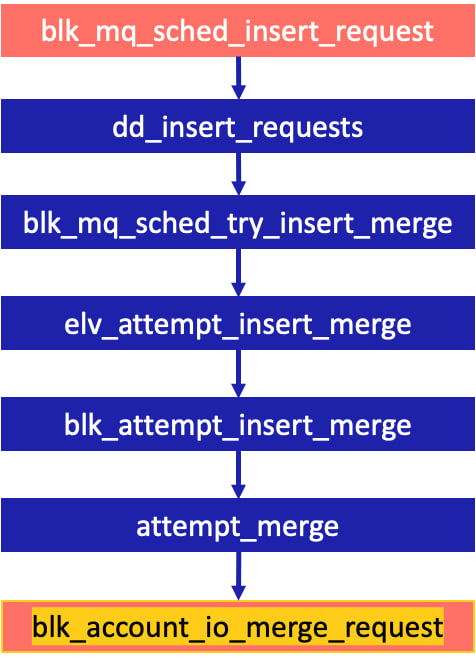
Изменение счетчиков слияний на blk_mq_sched_insert_request.
На этапе подготовки структуры для нового запроса производится сохранение текущего системного времени в функции blk_mq_rq_ctx_init, которое впоследствии будет использовано для вычисления времени выполнения операции:
static struct request *blk_mq_rq_ctx_init(struct blk_mq_alloc_data *data,
unsigned int tag, u64 alloc_time_ns)
{
...
if (blk_mq_need_time_stamp(rq))
rq->start_time_ns = ktime_get_ns();
else
rq->start_time_ns = 0;
...
}Точка входа в функцию подготовки структуры запроса приведена на схеме ниже. Последовательность вызовов внутри blk_mq_alloc_request имеет следующий вид: blk_mq_alloc_request à __blk_mq_alloc_request à blk_mq_rq_ctx_init.

Помимо сохранения времени начала обработки запроса в функции blk_mq_bio_to_request сохраняется значение системного таймера на момент готовности запроса. Технически оно сохраняется в поле bd_stamp структуры block_device. По завершению операции на блочном устройстве значение в этом поле будет использовано для вычисления дельты и инкрементации поля io_ticks уже в структуре disk_stats.
Код функции blk_account_io_start и update_io_ticks для обновления значения счетчика системного таймера:
void blk_account_io_start(struct request *rq)
{
if (!blk_do_io_stat(rq))
return;
/* passthrough requests can hold bios that do not have ->bi_bdev set */
if (rq->bio && rq->bio->bi_bdev)
rq->part = rq->bio->bi_bdev;
else
rq->part = rq->rq_disk->part0;
part_stat_lock();
(rq->part, jiffies, false);
part_stat_unlock();
}
static void update_io_ticks(struct block_device *part, unsigned long now,
bool end)
{
unsigned long stamp;
again:
stamp = READ_ONCE(part->bd_stamp);
if (unlikely(time_after(now, stamp))) {
if (likely(cmpxchg(&part->bd_stamp, stamp, now) == stamp))
__part_stat_add(part, io_ticks, end ? now - stamp : 1);
}
if (part->bd_partno) {
part = bdev_whole(part);
goto again;
}
}
Точка входа в функцию обновления счетчика системного таймера
Обновление большей части полей структуры disk_stats производится на этапе завершения запроса в функции void blk_account_io_done.

Счетчики, обновляемые функцией blk_account_io_done
blk_account_io_done увеличивает счетчик времени выполнения запросов, вычисляя разность между текущим значением системного времени и временем, сохраненным в структуре запроса в момент его подготовки. Она также увеличивает количество секторов, задействованных в операции ввода-вывода, инкрементирует счетчик операций ввода-вывода и обновляет значение системного таймера.
Функция обновления полей структуры disk_stats на этапе завершения запроса:
void blk_account_io_done(struct request *req, u64 now)
{
if (req->part && blk_do_io_stat(req) &&
!(req->rq_flags & RQF_FLUSH_SEQ)) {
const int sgrp = op_stat_group(req_op(req));
part_stat_lock();
update_io_ticks(req->, true);
part_stat_inc(req->part, ios[sgrp]);
part_stat_add(req->part, nsecs[sgrp], now – req->start_time_ns);
part_stat_unlock();
}На фоне всех прочих полей структуры disk_stats, которые обновляются на этапе отправки и завершения запроса, выделяется поле in_flight — массив на два элемента для подсчета операций чтения и записи, находящихся в процессе выполнения в нижележащих уровнях. Он обновляется динамически в процессе чтения статистики.
Когда нижележащий драйвер устройства приступает к выполнению запроса, он вызывает функцию blk_mq_start_request. Она должна уведомить блочный уровень, что запрос будет обработан и можно выполнить надлежащую инициализацию. Помимо этого, она устанавливает состояние запроса в MQ_RQ_IN_FLIGHT в процессе выполнения.
Когда пользователь через один из доступных интерфейсов попытается прочитать статистику, произойдёт итеративная проверка всех запросов в очередях на предмет состояния MQ_RQ_IN_FLIGHT и подсчет таковых. Схематично это процесс приведен на рисунке ниже.
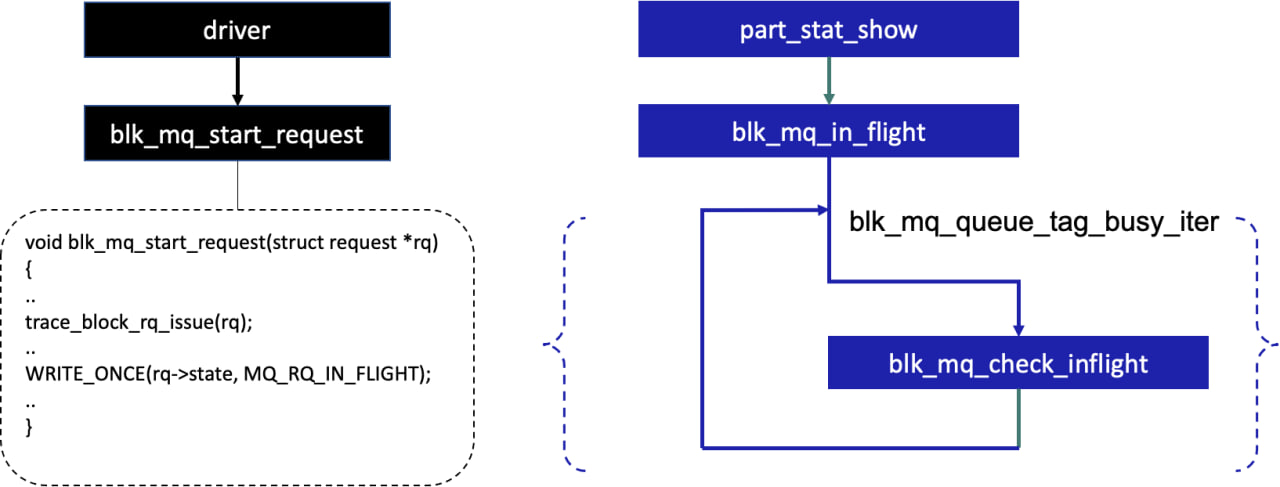
Установка состояния запроса и подсчет запросов в очереди
Код функции подсчета количества запросов в состоянии выполнения:
unsigned int blk_mq_in_flight(struct request_queue *q,
struct block_device *part)
{
struct mq_inflight mi = { .part = part };
blk_mq_queue_tag_busy_iter(q, blk_mq_check_inflight, &mi);
return mi.inflight[0] + mi.inflight[1];
}
static bool blk_mq_check_inflight(struct blk_mq_hw_ctx *hctx, struct request *rq, void *priv,
bool reserved)
{
struct mq_inflight *mi = priv;
if ((!mi->part->bd_partno || rq->part == mi->part) &&
blk_mq_rq_state(rq) == MQ_RQ_IN_FLIGHT)
mi->inflight[rq_data_dir(rq)]++;
return true;
}Помимо этого можно прочитать детализированную статистику по количеству операций в процессе выполнения в драйвере (in-flight) по пути /sys/class/block//inflight.
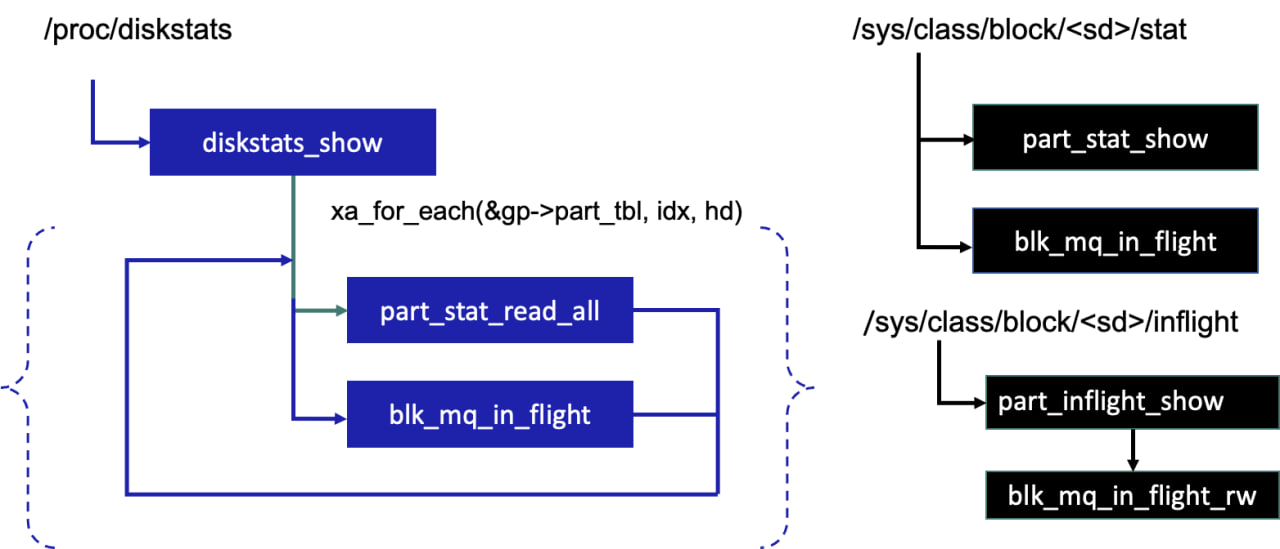
Последовательность вызова функций при чтении статистики
Код функции чтения статистики part_stat_read_all с рисунка выше:
static void part_stat_read_all(struct block_device *part,
struct disk_stats *stat)
{
int cpu;
memset(stat, 0, sizeof(struct disk_stats));
for_each_possible_cpu(cpu) {
struct disk_stats *ptr = per_cpu_ptr(part->bd_stats, cpu);
int group;
for (group = 0; group < NR_STAT_GROUPS; group++) {
stat->nsecs[group] += ptr->nsecs[group];
stat->sectors[group] += ptr->sectors[group];
stat->ios[group] += ptr->ios[group];
stat->merges[group] += ptr->merges[group];
}
stat->io_ticks += ptr->io_ticks;
}
}На экране вы увидите вот что:
8 1 sda1 245 203 11498 158 60 55 808 375 0 340 534 0 0 0 0 0 0Значение полей файла /proc/diskstats приведены в таблице ниже. В содержимом файла /sys/class/block//stat всё то же самое, но отсутствует информация о блочном устройстве, т.е. отсчет начинается с третьего поля.
Мажорный номер устройства | 8 |
Минорный номер устройства | 1 |
Имя устройства | sda1 |
Количество завершенных операций чтения | 245 |
Количество слияний в очереди на операциях чтения | 203 |
Количество прочитанных секторов | 11498 |
Общее время в ожидании завершения операций чтения (в миллисекундах) | 158 |
Количество завершенных операций записи | 60 |
Количество слияний в очереди на операциях записи | 55 |
Количество записанных секторов | 808 |
Общее время в ожидании завершения операций записи (в миллисекундах) | 375 |
Количество операций ввода-вывода в процессе выполнения | 0 |
Общее время, которое данное блочное устройство было активно (в миллисекундах) | 340 |
Суммарное время ожидания всех запросов | 534 |
Количество завершенных операций discard | 0 |
Количество слияний в очереди на операциях discard | 0 |
Количество отмененных (discard) секторов | 0 |
Общее время в ожидании завершения операций discard (в миллисекундах) | 0 |
Количество завершенных операций flush | 0 |
Общее время в ожидании завершения операций flush (в миллисекундах) | 0 |
2. Как работает iostat и что значат данные расширенной статистики
Источником данных для iostat служат те самые /proc/disk_stats и /sys/class/block//stat. Iostat заполняет два варианта структуры io_stats за промежуток времени, заданный в качестве параметра:
struct io_stats {
/* # of sectors read */
unsigned long rd_sectors __attribute__ ((aligned (8)));
/* # of sectors written */
unsigned long wr_sectors __attribute__ ((packed));
/* # of sectors discarded */
unsigned long dc_sectors __attribute__ ((packed));
/* # of read operations issued to the device */
unsigned long rd_ios __attribute__ ((packed));
/* # of read requests merged */
unsigned long rd_merges __attribute__ ((packed));
/* # of write operations issued to the device */
unsigned long wr_ios __attribute__ ((packed));
/* # of write requests merged */
unsigned long wr_merges __attribute__ ((packed));
/* # of discard operations issued to the device */
unsigned long dc_ios __attribute__ ((packed));
/* # of discard requests merged */
unsigned long dc_merges __attribute__ ((packed));
/* # of flush requests issued to the device */
unsigned long fl_ios __attribute__ ((packed));
/* Time of read requests in queue */
unsigned int rd_ticks __attribute__ ((packed));
/* Time of write requests in queue */
unsigned int wr_ticks __attribute__ ((packed));
/* Time of discard requests in queue */
unsigned int dc_ticks __attribute__ ((packed));
/* Time of flush requests in queue */
unsigned int fl_ticks __attribute__ ((packed));
/* # of I/Os in progress */
unsigned int ios_pgr __attribute__ ((packed));
/* # of ticks total (for this device) for I/O */
unsigned int tot_ticks __attribute__ ((packed));
/* # of ticks requests spent in queue */
unsigned int rq_ticks __attribute__ ((packed));
};А затем рассчитывает разность между полями структуры. Так происходит расчет расширенной статистики в iostat:
sdc.nr_ios = ioi->rd_ios + ioi->wr_ios + ioi->dc_ios; \\ sdc - current
sdp.nr_ios = ioj->rd_ios + ioj->wr_ios + ioj->dc_ios; \\ sdp - previos
void compute_ext_disk_stats(struct stats_disk *sdc, struct stats_disk *sdp,
unsigned long long itv, struct ext_disk_stats *xds)
{
xds->util = S_VALUE(sdp->tot_ticks, sdc->tot_ticks, itv);
xds->await = (sdc->nr_ios - sdp->nr_ios) ?
((sdc->rd_ticks - sdp->rd_ticks) + (sdc->wr_ticks - sdp->wr_ticks)
+ (sdc->dc_ticks - sdp->dc_ticks)) / ((double) (sdc->nr_ios - sdp->nr_ios)) : 0.0;
xds->arqsz = (sdc->nr_ios - sdp->nr_ios) ?
((sdc->rd_sect - sdp->rd_sect) + (sdc->wr_sect - sdp->wr_sect)
+ (sdc->dc_sect - sdp->dc_sect)) / ((double) (sdc->nr_ios - sdp->nr_ios)) : 0.0;
}Среднее время ожидания операции ввода-вывода с учетом нахождения в очередях (await) рассчитывается как разность суммарного времени ожидания за период времени, разделенного на количество операций ввода-вывода за тот же промежуток времени. Точка отсчета для вычисления времени выполнения запроса берется в момент подготовки структуры запроса, до передачи его в очередь.

Расчет среднего времени ожидания в очереди
Средний размер очереди (aqu−sz) рассчитывается как частное от разности суммарного значения времени ожидания за период измерения и периода измерения в миллисекундах. Значение aqu-sz весьма приблизительное, его точность зависит от степени однородности паттерна ввода-вывода и всегда отражает то количество операций, которые были завершены. Если есть необходимость в том чтобы получить точное количество операций в процессе выполнения в драйвере устройства, то более подходящими будут данные из файла /sys/class/block//inflight для конкретного устройства.
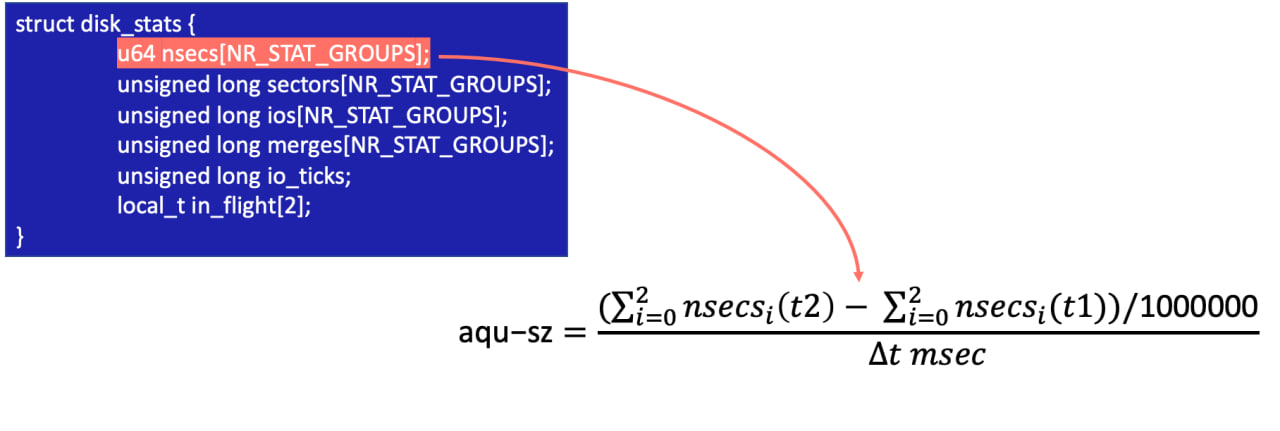
Расчет среднего значения размера очереди
Cредний размер блока ввода-вывода (arq-sz) рассчитывается как общая сумма секторов за период измерения, деленная на количество операций за тот же период. Размер блока учитывается после вероятного слияния, поскольку оба счетчика обновляются после завершения операции.
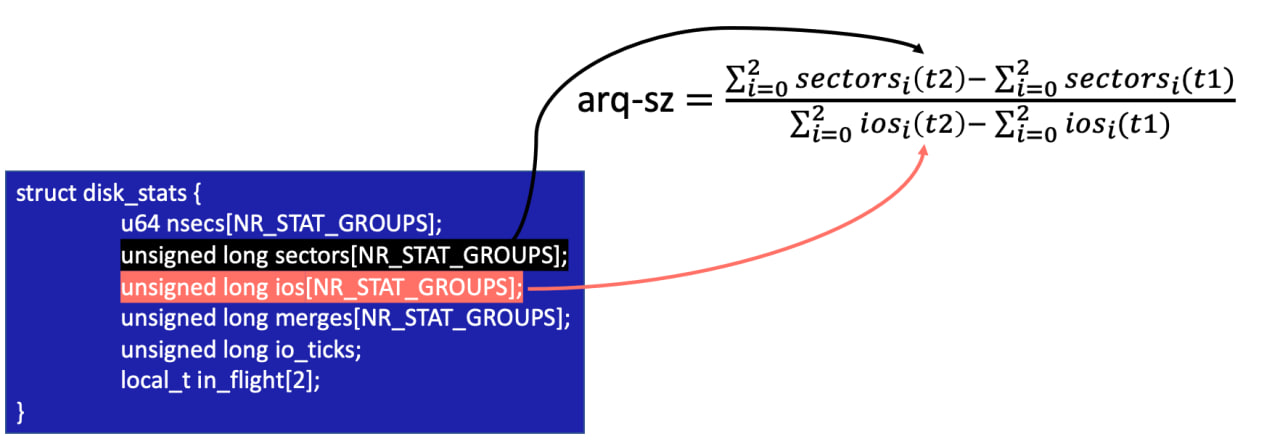
Расчет среднего значения размера блока ввода-вывода
Про расчет процент времени, в течение которого устройство выполняло операции ввода вывода (util%), хочется поговорить подробнее.
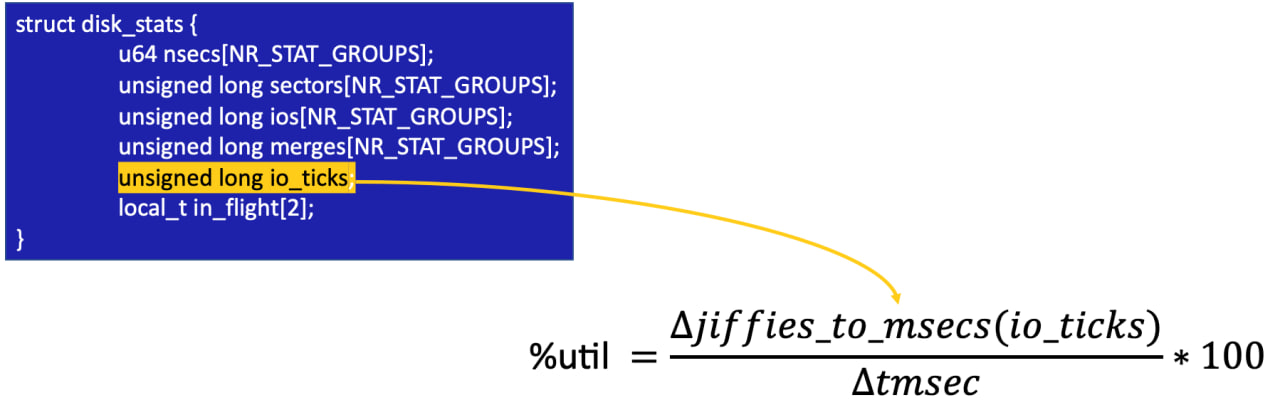
Расчет утилизации в iostat
Счетчик таймера обновляется в двух точках: на этапе подготовки запроса в функции blk_mq_bio_to_request и в обработке завершения запроса. В первом случае вызывается функция update_io_ticks с параметром false, что позволяет лишь обновить текущее значение в структуре block_device и инкрементировать io_ticks на единицу. Во втором случае функция вызывается с параметром true, вычисляется разность между сохраненным и текущем значением таймера, а результат прибавляется к значению io_ticks структуры disk_stats. Счет ведется для патриции, а не операции ввода-вывода так таковой.
Для примера возьмем два случая: синхронный и асинхронный последовательный ввод-вывод с глубиной равной трем операциям.
Так будет выглядеть подсчет количества изменений системного таймера для синхронного ввода-вывода:
jiffies = 150
io_ticks = 70 + 1 + 60 + 1 = 132, util ~88%
completed ios: 2
{------------------------ dT -----------------------}
0 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190
A | || || |
+--------------------++--------------------++-------------------+
stamp = 0 stamp=80 stamp=141
now = 10 now=81 now=142
io_ticks=+1 io_ticks=+1 io_ticks=+1
stamp=10 stamp=81 stamp=142
now=80 now=141 now=192
io_ticks=+70 io_ticks=+60 io_ticks=+50
А так — для асинхронного:
jiffies = 150
io_ticks = 1 + 50 + 1 + 9 + 1 + 9 + 1 + 39 + 1 + 9 + 1 + 9 +1 = 132, util ~88%
completed ios: 6
{------------------------ dT -----------------------}
0 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210
A | | | || || || || || || | | |
+--------------------++--||-||--------------++--||--||----------+ | |
B | | || || || || | |
+--------------------++-||------------------++--||---------------+ |
C | || || |
+--------------------++----------------------++-------------------+
A: stamp = 0
now = 10
io_ticks=+1
A: stamp = 30 A: stamp=80
now = 80 now = 81
io_ticks=+50 io_ticks=+1
A: stamp=101 A: stamp=140
now = 140 now = 141
io_ticks=+39 io_ticks=+1
A: stamp=161
now=190
io_ticks=+29
B: stamp = 10
now = 20
io_ticks=+1
B: stamp=81 B: stamp=90
now = 90 now=91
io_ticks=+9 io_ticks=+1
B: stamp=141 B: stamp=150
now=150 now=151
io_ticks=+9 io_ticks=+1
B: stamp=190
now=200
io_ticks=+10
C: stamp = 20
now = 30
io_ticks=+1
C: stamp=91 C: stamp=100
now = 100 now = 101
io_ticks=+9 io_ticks=+1
C: stamp=151 C: stamp=160
now=160 now=161
io_ticks=+9 io_ticks=+1
C: stamp=200
now=210
io_ticks=+10
На этих примерах видно, что для одинаковой утилизации в периоде dT в случае с асинхронном вводом-выводом количество операций в три раза больше по числу потоков. Конечно, в реальности всё будет зависеть от реализации драйвера и способности устройства хранения к параллельной обработке операций. В настоящее время практически все SSD/NVME, а так же большинство СХД являются многоканальными. Оценку насыщения подобных систем следует производить не на основе процента утилизации, а на основе роста очереди или времени ожидания от устройства.
Вторая часть проблемы заключается в малой дискретизации по времени, обусловленной частотой системного таймера 100Гц на большинстве платформ. Учет производится в миллисекундах. Это приводит к тому, что операции с временем обслуживания менее 1 мс округляются, либо остаются неучтенными. С обсуждением данной проблемы, а так же предложенного решения можно ознакомиться по ссылке.
И еще несколько полезных ссылок:
Habrahabr.ru прочитано 10099 раз
