
Не тимбилдингом единым: как наладили коммуникации в команде с помощью базы знаний

Объем задач растет, как снежный ком, а разработчики и аналитики переводят друг на друга стрелки, потому что никто не понимает, что от них хотят. Обстановка обостряется до предела и грозит превратиться в поле битвы. Такая ситуация произошла несколько лет назад, когда работать по старой схеме стало невозможно.
Всем привет! На связи мы, Мария и Яна из самой драйвовой IT-команды «БАРС Груп». В этой статье расскажем, как создавали инструмент эффективного взаимодействия в IT-команде — базу знаний постановок задач, которые реализует проектная команда. По порядку разберем, почему мы решили создать шаблон, как разрабатывали и как доводили до ума после внедрения и, конечно, о результатах.
Зачем нам это было надо?
Не секрет, что во многих командах есть проблема взаимодействия между аналитиками и разработчиками. От того, насколько хорошо налажены коммуникации, напрямую зависит качество конечного продукта и скорость его реализации.
Частые рабочие конфликты неизбежно ведут к ухудшению результатов работы. До 2017 года в нашей команде были серьезные разногласия и недопонимания между аналитиками и разработчиками, несмотря на то, что все тимбилдинги и внерабочие тусовки проходили на «ура». Основной причиной становилась двоякая трактовка описания задач на разработку и, как следствие, разногласия при их приемке. Мы задавались вопросами: «Почему реализовано не так, как описано?» и «Кто виноват?». Все это приводило к тому, что реализация требований заказчиков затягивалась.
Дорогу осилит идущий
Мы начали с производственного процесса — установили четкую последовательность переходов запросов в таск-трекере. Стало понятно, на каком этапе сейчас находится тот или иной запрос и что с ним будет происходить дальше. И явным образом высветилось «узкое место» — этап оценки времени разработки.
В то время мы активно использовали Planning Poker для получения объективного результата. Но это оказалось слишком дорого: аналитикам и разработчикам приходилось долго обсуждать постановку задачи всей командой, разбирая, что имел в виду ее автор. Мы описывали постановки задач только в таск-трекере. Чтобы понять, как именно реализовано сейчас, приходилось постоянно работать с несколькими задачами одновременно, иногда сразу с десятью.
Параллельно в других подразделениях происходил переезд со старого таск-трекера на новый, в котором мы работали с самого начала. При переезде часть запросов не перенеслась, что-то было утеряно. А наши системы росли, счет задач в таск-трекере уже шел на тысячи. Мы не могли себе позволить потерять ни одну задачу.
Работа с госзаказчиками, тем более в сфере финансов, вынуждает нас постоянно вносить изменения в реализованный функционал. Чтобы ничего не сломать, надо четко понимать, как работает система сейчас, какие именно изменения и куда нужно внести, где это еще используется и на что может повлиять.
Аналитики стали постоянно дергать разработчиков, чтобы вытащить из кода описание работы, наличие зависимостей и связей. Теперь время аналитиков и разработчиков стало уходить на выяснения «как работает сейчас». Появились конфликты, ведь разработчику надо реализовывать задачу, ему некогда, аналитик ждет его, а в это время на него давит РП и так по кругу.
Стало понятно: нужна полноценная база знаний. Мы перешли на новую схему постановки, которой пользуемся и по сей день:
в базе знаний мы описываем основные требования к реализации для разработчика;
в таск-трекере мы описываем адрес тестового стенда, тест-кейс по приемке задачи и делаем ссылку на базу знаний.
Квантовый скачок
Но как описывать постановки в базе знаний?
В первую очередь так, чтобы и разработчикам, и аналитикам было удобно с ними работать. А чего хочет от постановки разработчик? Чтобы в задаче было ПОНЯТНО описано, что надо сделать. И желательно — для чего делать и что нужно получить в результате. Аналитики же хотят всего и сразу. Во-первых, постановка должна быть понятной, причем не только в моменте, но и спустя некоторое время. Во-вторых, она должна быть доступна для понимания как автору постановки, так и любому другому аналитику, как опытному, так и новичку.
Сначала мы обратились к классикам. В книге Карла Вигерса и Джой Битти «Разработка требований к программному обеспечению» в приложении В (согласно актуальному 3-му изданию) есть «Спецификация требований к ПО». Мы взяли ее за основу и адаптировали под себя с учетом той последовательности действий разработчика, которые он совершает при реализации нового функционала. В результате мы получили структуру шаблона постановок задач в базе знаний для новых разработок.
Однако структура шаблона сама по себе не решала главной проблемы — наполнение постановок. Как описывать постановку, чтобы она была понятна всем? Какими словами, каким языком «разговаривать» аналитикам и разработчикам?
Мы придумали и реализовали артефакт, для каждого проекта он свой. В нем содержится описание всех сущностей системы:
наименование в коде на английском языке и наименование на русском языке для аналитиков;
наименование таблицы в БД;
полный перечень атрибутов сущности, также с наименованием в коде на английском и для аналитиков на русском языке.
Инструмент автоматически выгружается при обновлении тестовых стендов ветками задач в TeamCity в формате xml. Т.е. мы в любой момент можем получить его актуальную версию.

С таким «словарем» аналитики могут описывать в постановках наименования сущностей и атрибутов на русском языке и быть уверенными, что разработчики их поймут.
Как устроен шаблон
Шаблон состоит из 6 разделов. Для каждого из них есть правила заполнения, по которым проводится ревью постановки. Мы постарались учесть и требования заказчика к системе, и возможности, и ограничения системы, о которых важно не забыть при постановке.
Раздел «Общая информация» включает в себя:
наименование доработки, путь в системе и ссылку на задачу;
краткое описание задачи своими словами;
краткое описание бизнес-проблемы;
основание реализации (например, номер требования в бэклоге и т.д.);
при необходимости расшифровку сокращений и аббревиатур.
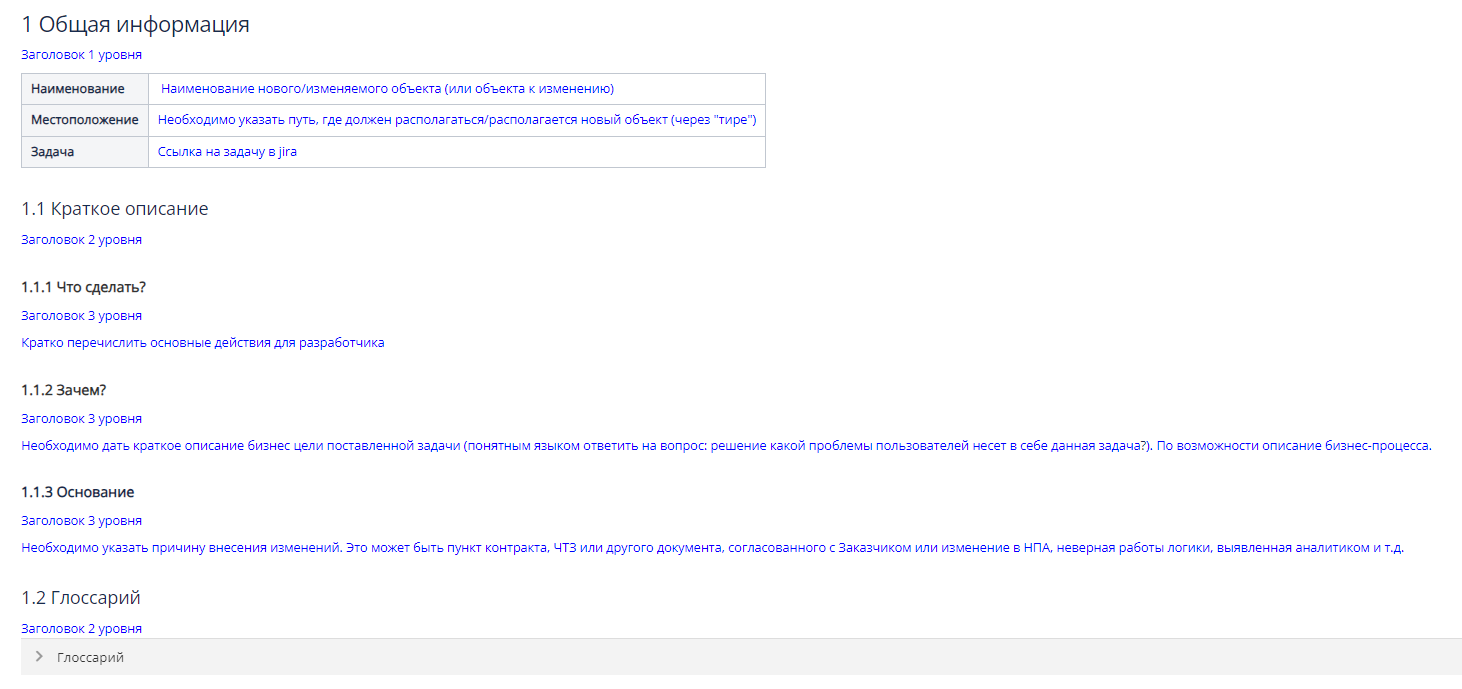
В разделе «Модель данных» описываем атрибуты сущности и их характеристики:
наименование — на русском языке;
тип данных;
обязательность атрибута;
значение по умолчанию.
При необходимости добавляем описание атрибута для удобства аналитиков. Если атрибут ссылочный, то в источнике указываем, на какую сущность ссылается.
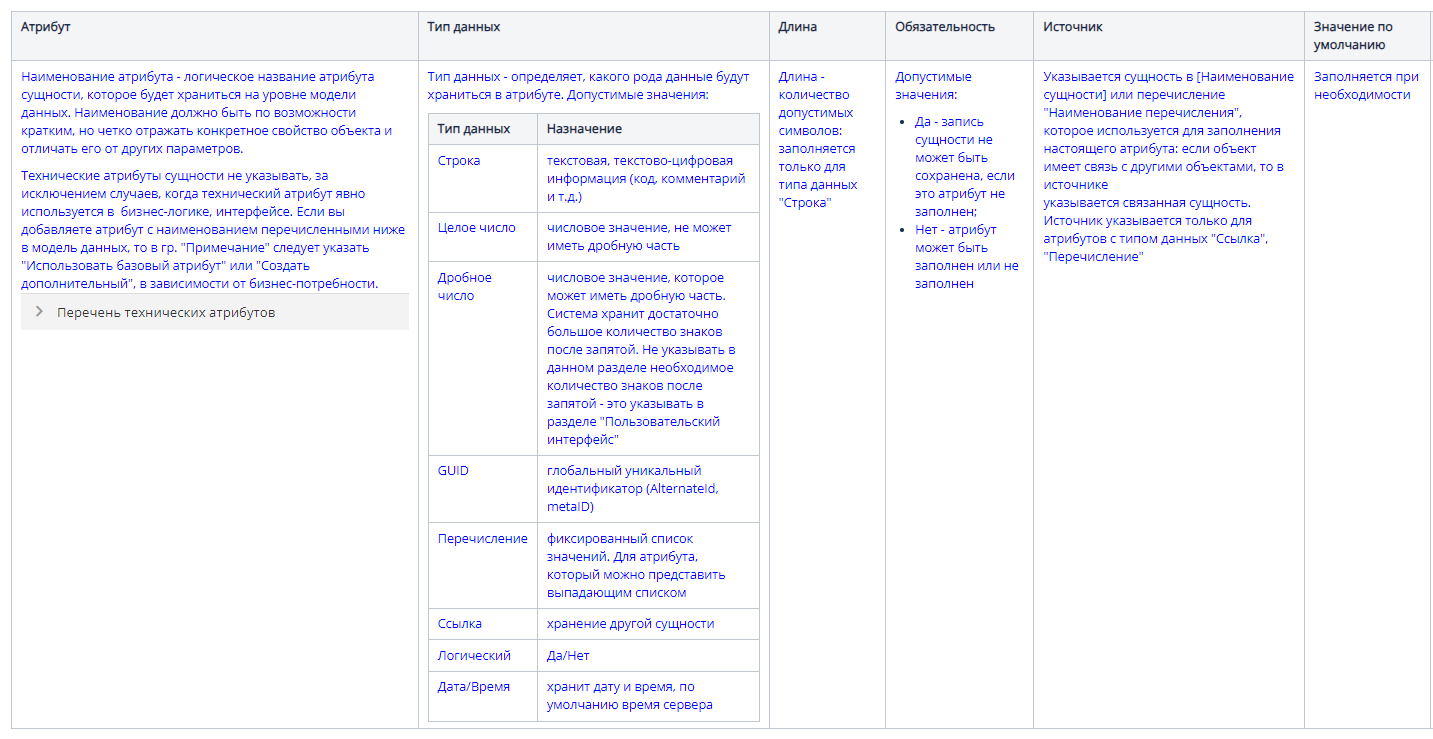
Также здесь описываем правила создания сущности:
является ли сущность обычной или имеет период действия;
является ли она линейной или иерархической;
правила создания и удаления сущности;
прочие значимые правила, например, что номер документа присваивается автоматически по определенным условиям.
Раздел «Валидация» — это проверка сущности в базе данных, выполняемая при сохранении или обновлении записи независимо от способа добавления данных (ручное добавление, импорт данных, автоматическое создание при добавлении другой записи и т.д.).
В этом разделе описываем наименование контроля (для аналитиков), объект проверки и условие срабатывания в формате «сущность-атрибут» на русском языке и текст сообщения, который должен выйти пользователю в случае, если контроль сработал.

Раздел «Права доступа». Для удобства администрирования системы все пермиссии (права доступа) сгруппированы по папкам, каталогам и т.д. В этом разделе постановки описываем, в какой папке прав доступа нужно создать новую папку или новые права. Только названия папок и прав — ничего больше. Описание работы прав доступа описывается в других разделах: Интерфейс и Функции.
Как должен выглядеть реестр или документ, описывается в разделе «Интерфейс». Он позволяет настолько подробно описать интерфейс, что не всегда требуется макет. Да, возможно, это особенности наших систем, что у нас интерфейс это «таблички с кнопочками» и «окошки-набивалки». Но и такие макеты требуют времени на отрисовку. А так мы описали, как видим интерфейс, по табличкам, и можем быть уверены, что разработчик реализует именно то, что мы описали.
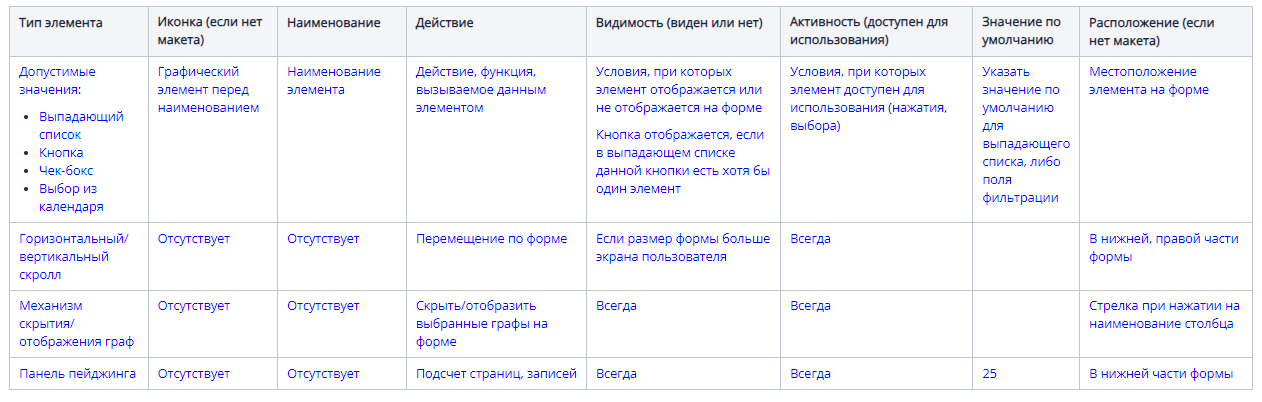
а. Первая таблица для описания панели инструментов. Для кнопок мы описываем действие, которое вызывает ее нажатие, видимость, активность и расположение.
b. Вторая таблица описывает форму просмотра для реестра или справочника. Мы указываем наименование столбца и источник, т.е. атрибут сущности, значение которого должно отражаться в реестре (или справочнике) — фильтрация, сортировка, видимость, выравнивание, ширина столбца, всплывающие подсказки. Отдельно описываем после таблицы важные моменты. Например, правила отображения данных, если они зависят от прав доступа, или правила работы дополнительных фильтров на панели инструментов.
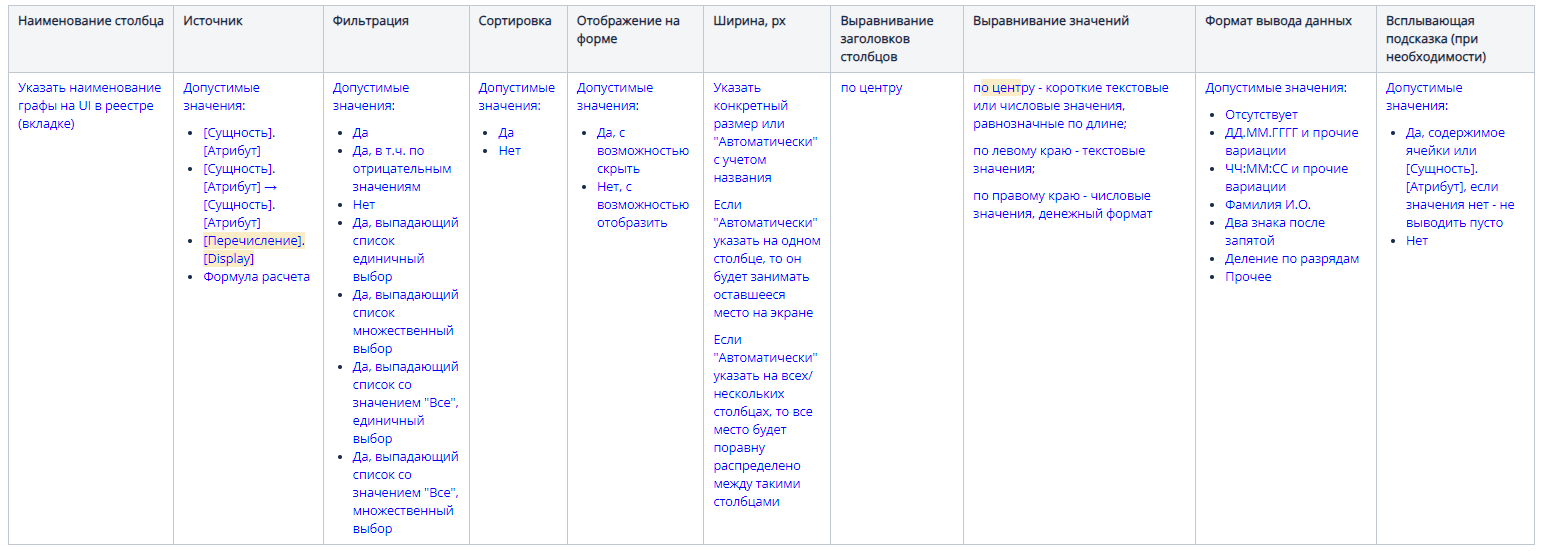
c. Третья таблица описывает окна редактирования или просмотра. Для них мы описываем наименования поля, элемент формы, источник, обязательность на интерфейсе, состояние, а также возможно ли редактирование поля или оно доступно только для чтения. Далее указываем значение по умолчанию, если оно необходимо. В примечании можно указать правила отбора записей других сущностей, правила пересчета, необходимость затемнять поле, если оно недоступно для редактирования.
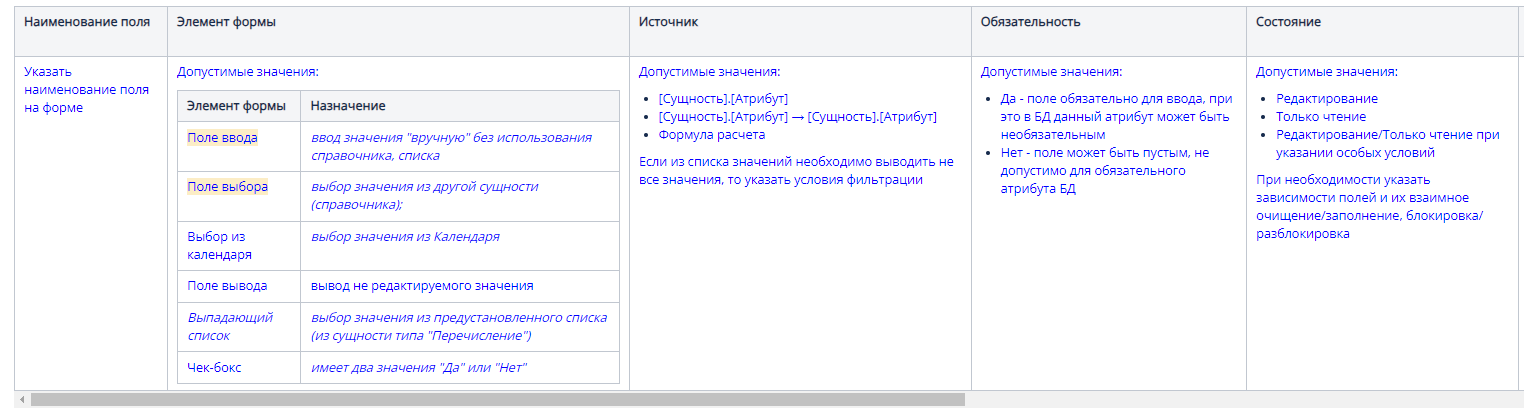
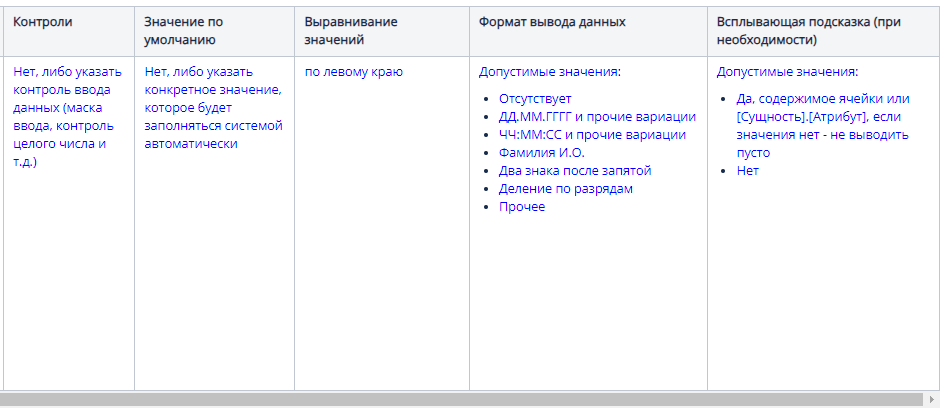
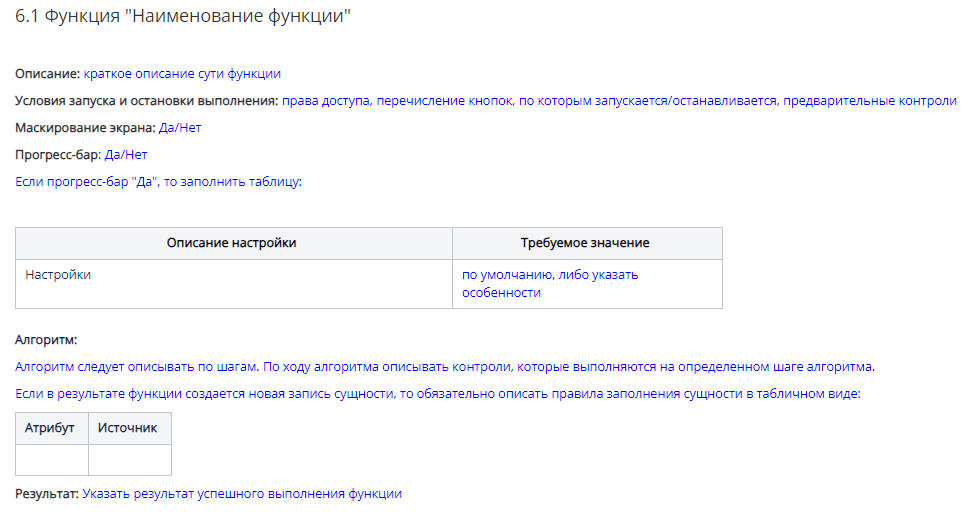
6. Раздел «Функции»: указываем условия запуска функции и алгоритм. Здесь могут быть стилистические различия в описании: все-таки разные люди по-разному строят фразы. Соблюдаем главное правило — описывать в формате «сущность-атрибут», т.е., какую сущность по каким признакам ищем, что с этим потом делаем, если не нашли / если нашли / если нашли несколько и т.д.
Планомерное движение вперед
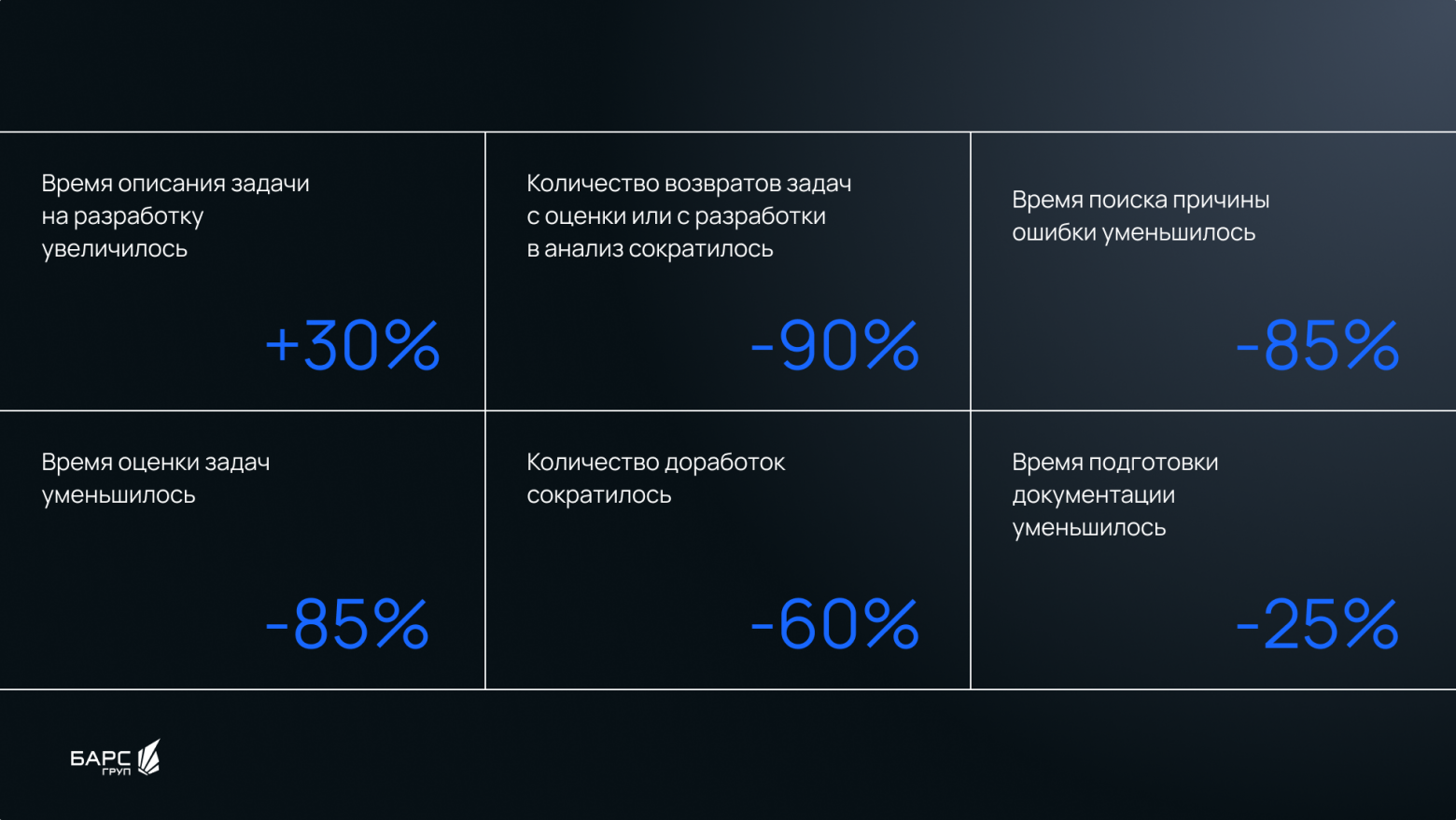
Итак, шаблон мы разработали, рассказали всем, как его применять. Но для окончательного перехода на постановки по нему потребовалось несколько месяцев. Не все аналитики были согласны с этим решением, им комфортнее было работать по-старому. Какое-то время и разработка принимала в работу задачи, описанные не по шаблону. Понимание полезности шаблона приходило постепенно. У тех аналитиков, кто ставил по шаблону, все меньше задач возвращалось с оценки и отправлялось в доработку после приемки. А у тех, кто не использовал шаблон, наоборот, росло количество комментариев к постановкам и им приходилось обосновывать возврат задач на доработку.
Со временем мы поняли, что шаблон удобен не только для новых постановок: он также прекрасно подходит для любых доработок, изменений, для итерационной разработки. В постановке можно описать только те разделы, которые затрагиваются в задаче. Например, описать одну кнопку и функцию, которую она запускает, или добавить новый атрибут и новую графу в реестр.
При необходимости реализации нового большого функционала, с множеством документов и сложных функций, постановка декомпозируется до небольших задач, устанавливаются блокирующие связи в задачах в таск-трекере, и реализация может ускориться. В одной задаче будет модель данных и валидация, в другой — права доступа и простейший вид реестра. В следующих задачах будут параллельно дорабатываться интерфейс и реализовываться функции. Это может существенно сэкономить время на реализацию и более качественно управлять ресурсами, потому что такие небольшие задачи могут брать в работу начинающие аналитики и разработчики.
Декомпозиция задач по новой схеме оказалась настолько удобной, что в какой-то момент мы только так и работали: разбивали новую реализацию на несколько маленьких задач до самого минимального уровня.
Сначала мы вели такие задачи, относящиеся к доработкам одной функциональности, в одной статье. Каждая постановка была свернута в экспанд, у которого в названии было краткое описание: что в этой задаче правили и номер задачи в трекере. В целом, такая организация статей работала, пока количество экспандов в каждой статье не стало превышать 5–7. Потом начинались проблемы.
Во-первых, стало неудобно ставить новые задачи. Статья получалась очень длинная, навигации в режиме редактирования нет, а свернуть экспанды нельзя. Повезло, если твой экспанд последний в этой статье. А если одновременно доработки ставят несколько аналитиков?

Во-вторых, осталась проблема работы с изменениями. С каждой декомпозицией задач мы получили огромное количество разрозненных постановок. Чтобы получить информацию, как работает система сейчас, требовалось прочитать последовательно все экспанды. Да, мы не отвлекали разработчиков, но это занимало время аналитика.
Встал острый вопрос: «Как получить большую хорошую постановку, которая подробно описывает всю функциональность?».
Мы в кругу аналитиков решили хранить описание текущей реализации в базе знаний и оформлять ее по тому же шаблону. А все декомпозированные задачи, новые доработки вести в зависимых статьях.
Будем честны: полностью следовать этой схеме мы смогли только на новом проекте. На старых описание функционала заняло очень много времени — мы собирали все постановки задач, как кусочки пазлов. Но применение шаблона в этих задачах все же облегчило работу. Оформление «основных статей» в текущем проекте окупилось в процессе работы.
Детальное описание функциональности системы позволяет нам быстро определить участок, где нужно внести изменения, а также быстро находить проблемные места. Более того, это также экономит время при описании доработок: достаточно скопировать нужный кусок из основной статьи и дописать то, что нужно. Изменения в основную статью вносятся после закрытия задачи.
К чему мы пришли?
Перечисленные выше мероприятия привели к повышению эффективности взаимодействия команды на проектах:
Разработчики и аналитики получают то, что они хотят.
Мы легко переключаем аналитиков и разработчиков между проектами при необходимости.
Шаблон с подробным описанием и инструкции, как его наполнять, существенно облегчают и ускоряют адаптацию новичков.
На ревью постановки, от того, насколько глубоко она проработана, сразу видно уровень компетенции аналитика.
Несмотря на то, что увеличилось время описания задач, сокращается время на поиск информации как аналитиками, так и специалистами техподдержки в ситуациях, когда нужно определить понимание уровня ошибки. Т.е. можно ли решить вопрос настройкой, обратиться к аналитику или нужно ставить ошибку на разработку. Шаблон ускоряет процесс подготовки документации, в том числе РП, РА и т.д.
Результаты внедрения шаблона постановки задач:
Переход на такую схему постановки задач и взаимодействия в команде дали положительный эффект внутри Бизнес-центра. У нас один из самых низких показателей текучести кадров. Средняя продолжительность работы в нашем БЦ — 3 года, 25% сотрудников на сегодняшний день работают с момента основания БЦ или более 5 лет. По данным разных исследований последних лет, сотрудники в IT чаще меняют место работы. Разработчики чаще других специалистов советуют переходить на новое место каждые три года (24%) — результаты опроса сервиса по поиску работы SuperJob.
Наш бизнес-центр часто называют «ламповым»; как бы банально это не звучало, но мы — команда! Нас давно уже объединяет не только производственный процесс, но и совместное времяпрепровождение за пределами офиса. Все это — плод ежедневных усилий всей команды на протяжении нескольких лет.
Надеемся, что наш опыт окажется полезным и вам. Поделитесь, а что вы используете? Как вы решали подобные задачи?
Habrahabr.ru прочитано 7704 раза
