
Как найти баланс между интересами покупателей и продавцов: опыт разработчиков Яндекс Маркета

Привет, Хабр! Меня зовут Илья Ненахов, я руковожу разработкой платформы для продвижения товаров на Яндекс Маркете. Про сам сервис, думаю, многие знают, поэтому не буду подробно о нём рассказывать. Предлагаю взглянуть на площадку немного с другой стороны, а именно — как на механизм, который пытается найти оптимальную точку в пространстве с тремя измерениями: интересы пользователя, интересы магазинов и интересы самого сервиса.
Интересы покупателей часто не совпадают с интересами продавцов. Магазины хотят получать больше прибыли: им выгодно, чтобы пользователи покупали по высоким ценам. При этом пользователи хотят, чтобы цены были самыми низкими на рынке, а срок доставки — как можно меньше. Принимая продуктовые решения, нужно всегда оценивать, как мы влияем на этот баланс. Неверное решение легко может всё сломать: например, если мы начнём требовать от магазинов доставлять товары на следующий день, мы, конечно, порадуем пользователей пару дней, но уже вскоре останемся без магазинов.
В этой статье я расскажу о том, как мы поддерживаем этот баланс с помощью технологий Яндекса, на примере платформы для продвижения товаров в поиске Маркета. Поговорим про метрики, ранжирование и устройство рантайма. Наш опыт может быть полезен тем разработчикам, которые работают над похожими задачами в других компаниях.
Какую задачу решает платформа для продвижения
Задачу платформы на Яндекс Маркете можно сформулировать просто: дать магазинам инструмент для роста заказов, но при этом не уронить качество сервиса, чтобы не расстроить пользователей.Звучит вроде бы понятно, но, как я говорил выше, баланс в этом механизме очень просто сломать.
Чтобы этого не допустить и успешно справиться с задачей, нужно всё оцифровать. Тогда можно пользоваться уже типичными для Яндекса инструментами: математической оптимизацией, машинным обучением, а также строить метрики и системы мониторинга. Понятно, что оцифровать рост продаж легко, а вот что делать с качеством сервиса? И что вообще такое качество в нашем понимании?
Под метрикой качества сервиса часто понимают GMV — это сумма цен проданных товаров. Все маркетплейсы измеряют свою долю на рынке, пользуясь этой метрикой. Но можно ли сказать, что GMV отражает счастье пользователя? В какой‑то степени да: если пользователям не нравится сервис, вряд ли они будут на нём что‑нибудь покупать. С другой стороны, можно чуть увеличить цены, и, скорее всего, мы увидим краткосрочный рост GMV на сервисе, но сделаем ли мы пользователям хорошо в этом случае? Нет.
Одна из метрик, по которой можно судить о счастье пользователей — это количество заказов. Ведь у каждого из них есть выбор: заказать у нас или в другом месте. И если пользователю что‑то не нравится в нашем сервисе, то, скорее всего, он уйдёт.
Итак, получается, считать заказы мы умеем, счастье пользователей — тоже. Осталось разобраться с инструментами продвижения для продавцов. У нас их много, но в этой статье я расскажу только про премиальную врезку на поиске.
Важно отметить, что все наши инструменты схожи со стороны B2B‑части. Магазин говорит, какой процент от цены продажи он готов потратить на продвижение (ставка), а мы обещаем ему привлечение дополнительных заказов. В терминах рекламных технологий это CPA‑инструмент: магазин платит за факт совершённого заказа, и тут уже наша задача — сделать так, чтобы этот заказ произошёл. Понятно, что эта задача для площадки несёт гораздо больше рисков, чем для магазина: мы не получим ни копейки, пока не принесём дополнительный заказ, в отличие, например, от CPM‑рекламы, где оплата производится просто за факт показа. Но, как показывает практика, CPA‑инструменты гораздо эффективнее для продавцов.
Ранжирование в премиальной врезке
Премиальная врезка — это горизонтальный блок на поисковой выдаче, в который попадают релевантные запросу товары со ставкой. Вот так этот блок выглядит на поиске:
Позиция блока может изменяться исходя из параметров запроса. На каких‑то запросах блок может отсутствовать или показываться ниже.
А это — упрощённая схема того, что происходит под капотом.

Под блоком Clients подразумеваются все возможные типы клиентских приложений: Android, iOS, веб. На каких‑то платформах запросы шлёт не сам клиент, а промежуточный BFF, но для этой статьи это не так принципиально.
Начиная с кубика Meta search, мы уже попадаем в главный бэкенд нашей платформы. В схеме он разбит на две части — мета и базовая. Мета на каждый входящий запрос опрашивает все базовые ноды, а каждый базовый нод при этом ищет по своему куску (шарду) индекса. Мотивация такого разбиения простая: на Маркете очень много данных, мы уже давно не можем держать весь поисковый индекс в памяти одной машины, поэтому вынуждены его дробить. На мете есть ещё пласт важной логики — расчёт запросных факторов для ранжирующих моделей машинного обучения. Часть таких факторов достаточно тяжёлые в плане производительности и в придачу рассчитываются на GPU, поэтому живут в отдельных микросервисах.
Давайте поговорим про факторы поподробнее. В задачах ранжирования поисковой выдачи нейросети появились и полюбились очень давно (статья о применении подхода DSSM в поиске Яндекса вышла на Хабре ещё в 2016 году). Я думаю, основная причина того, почему нейросети и поиск так давно вместе, — это возможность независимо получать векторные представления документа и запроса. Это очень важно для поиска, потому что построение поискового индекса — это по большей части офлайн‑процесс. Если мы можем рассчитать вектор документа в офлайне, а в рантайме оставить только вычисление скалярного произведения с запросной частью, то сильно ускорим всю систему. Это особенно актуально для современных архитектур на трансформерах: если DSSM‑модели мы могли считать на CPU, то BERT‑like‑модели уже требуют GPU в рантайме.
Если подытожить, то на этом этапе логики мы применяем множество нейросетевых DSSM‑ и sentence‑bert‑моделей, обученных на разные таргеты — как релевантностные, так и бизнесовые.
Теперь перейдём к базовому поиску. Всё происходящее на этой стадии поиска можно тоже разделить на несколько этапов: отбор кандидатов, фильтрация по релевантности, ранжирование с учётом ставки.
Отбор кандидатов
В отборе кандидатов мы используем инвертированный индекс. Подобную структуру данных можно встретить в любом открытом поисковом движке. Она позволяет достаточно быстро находить документы, в которых встречаются слова (term) из запроса, и заодно отбирать топ документов по какой‑нибудь простой функции релевантности, например TF‑IDF или BM25.
Выше я писал про векторные представления и про то, почему их здорово использовать в поиске. Но ещё лучше использовать их на этапе отбора кандидатов, чтобы сразу получать лучших. Вообще, развитие технологий по решению задачи поиска ближайших соседей заслуживает отдельной статьи. Сейчас появляется очень много специализированных баз данных для этой задачи, да и популярные базы данных обрастают подобной функциональностью. Пример — pgvector для PostgreSQL.
У себя мы используем кастомные kNN‑индексы, которые возвращают нам топ документов, близких к запросу. Отбор кандидатов заканчивается получением топа документов инвертированного индекса и kNN‑индекса.
Фильтрация по релевантности
Предложения товаров должны быть релевантными. Во‑первых, чтобы не раздражать пользователей, а во‑вторых, нерелевантные показы приносят мало пользы продавцам. Более того, премиальная врезка занимает место над поиском, на которое претендуют как другие врезки, так и сама поисковая выдача. Ошибочно показывая нерелевантную премиальную врезку, мы будем негативно влиять и на другие продуктовые метрики.
Хорошо, премиальная врезка должна быть релевантной запросу, но что это значит? Как это измерить? Тут на помощь приходит большой опыт Яндекса в построении поисковых систем. Упрощённо то, что у нас происходит, представлено на рисунке ниже.
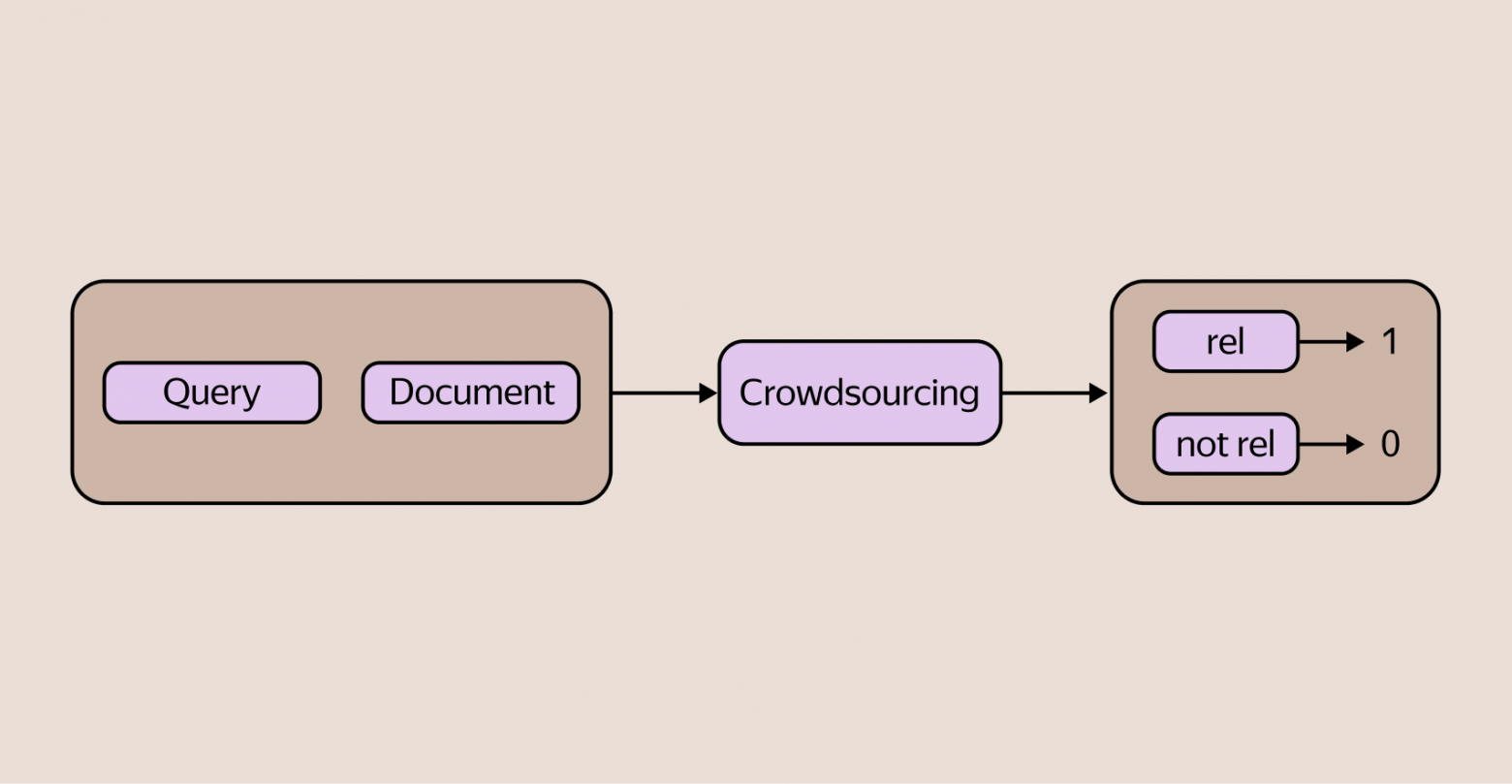
У нас есть регулярный процесс разметки с помощью краудсорсинга, в котором люди определяют, релевантен документ запросу или нет. Мы используем эти оценки, чтобы определить релевантность всей врезки.
Но здесь всё не так просто: на восприятие релевантности врезки влияют не только документы внутри врезки, но и сама поисковая выдача. Если пользователь ищет что‑то конкретное, то нам не хочется показывать аналоги выше правильного товара в выдаче. Учитывая все эти факторы, мы обучили классификатор, который определяет, стоит ли дальше пропускать документ или нет.
Ранжирование с учётом ставки
На этом этапе мы включаем учёт ставки по полной. Формула ранжирования подобрана таким образом, чтобы документы, у которых ставка больше, поднимались выше.
Тут напрашивается вопрос:, а почему бы здесь не проранжировать просто по ставке? Если бы у нас была CPM‑реклама (напомню, в CPM‑рекламе рекламодатель платит за показы), то ранжирование по ставке было бы лучшим решением. Но в нашем случае CPA‑рекламы нужно, чтобы с врезки было больше заказов. Ранжирование по ставке — не самое оптимальное с точки зрения заказов.
Чтобы учесть заказы в ранжировании, нам нужно предсказать вероятность заказа для каждого документа.

Функцию f мы можем найти при помощи ML. CatBoost хорошо справляется с этой задачей. Под factors подразумевается набор факторов, в который, в том числе, входят нейросетевые модели, которые я описывал выше. Знание p_purchase позволяет нам использовать математические ожидания GMV и рекламной выручки в итоговом скоре ранжирования.


Price — цена предложения от магазина.
Fee — ставка, которую выставил магазин.
В AdTech происходит много всего интересного, особенно в еком‑сегменте. Надеюсь, мне удалось немного приоткрыть завесу тайны над тем, как работают подобные системы, и это будет полезно для комьюнити.
Habrahabr.ru прочитано 6751 раз
