
Как мы прогнозируем объемы грузоперевозок на основе машинного обучения, используя MLflow
Привет, коллеги! Меня зовут Александр Кузьмичев, и я ведущий специалист по анализу данных в Первой грузовой компании. Мы с коллегами разработали «Прогнозатор» — инструмент для оценки объемов грузоперевозок между ж/д станциями. В основе лежит открытая платформа MLflow, и сегодня я расскажу, чем она нам помогает.

Фотография Ainur Khakimov / Unsplash
Зачем понадобился MLOps
Прежде чем перейти к разговору о машинном обучении и пайплайнах, скажу пару слов о самом «Прогнозаторе». Инструмент предсказывает объёмы грузоперевозок между ж/д станциями. Этот прогноз в ПГК используется для последующего планирования продаж.
Нам необходимо вести учет переменных, сравнивать точность прогнозов и анализировать результаты экспериментов. Для этих задач нам потребовался специальный инструмент. Изначально мы рассматривали neptune.ai, Kubeflow и Aim, но по разным причинам они нам не подошли. Например, нас смутили платные тарифы и относительно небольшие размеры сообществ. В перспективе эти факторы могли отразиться на стоимости поддержки и скорости решения потенциальных проблем.
В итоге мы остановили выбор на платформе MLflow. Она открытая, и её можно интегрировать с любой библиотекой машинного обучения. Плюс — она позволяет не только отслеживать и визуализировать метаданные о ML-моделях, но и упрощает их развертывание. В то же время инструмент помогает работать с генеративными системами ИИ — проводить кастомизацию, дообучение, внедрять их в собственные приложения. Эта функциональность может оказаться полезной в перспективе.
Как мы используем MLflow
В первую очередь MLflow позволяет нам хранить артефакты и метрики экспериментов в одном месте. Так, на скриншоте ниже показана вкладка, где видно информацию обо всех запусках модели и используемых метриках.

Мы можем сравнить модели по любому параметру, который внесли в MLflow. В частности, мы ведем учет таких метрик, как MAPE/MAE/ABE/KPI (TRAIN/TEST/OOT), параметры запуска, графики. В целом, легко добавить любые другие файлы и логи, которые необходимо отслеживать.
Мы также видим все параметры, которые передаются в модель — какая ветка Git была запущена и где. Это может быть запуск пайплайна на условном ноутбуке с целью отработать теорию и протестировать изменения на небольшом срезе данных. Второй вариант — запуск на продуктовых серверах с десятками CPU для полного расчета изменений пайплайна.
Если нужно дообучить или обновить модель, можно модифицировать веса ранее отобранных переменных. Именно в этом формате работает «Прогнозатор». Получается, что мы пропускаем этап выбора переменных при обучении модели и строим её на уже имеющихся. Тем самым мы экономим время и ресурсы.

В MLflow мы отслеживаем вносимые в модель изменения и пишем логи. Они помогают понять, что влияет на качество прогнозов (становится лучше или, наоборот, хуже). Логировать можно файлы, модели, графики, теги, метрики, системные запуски, собственные обёртки моделей, параметры библиотек, json, html, df, csv, txt и многое другое.
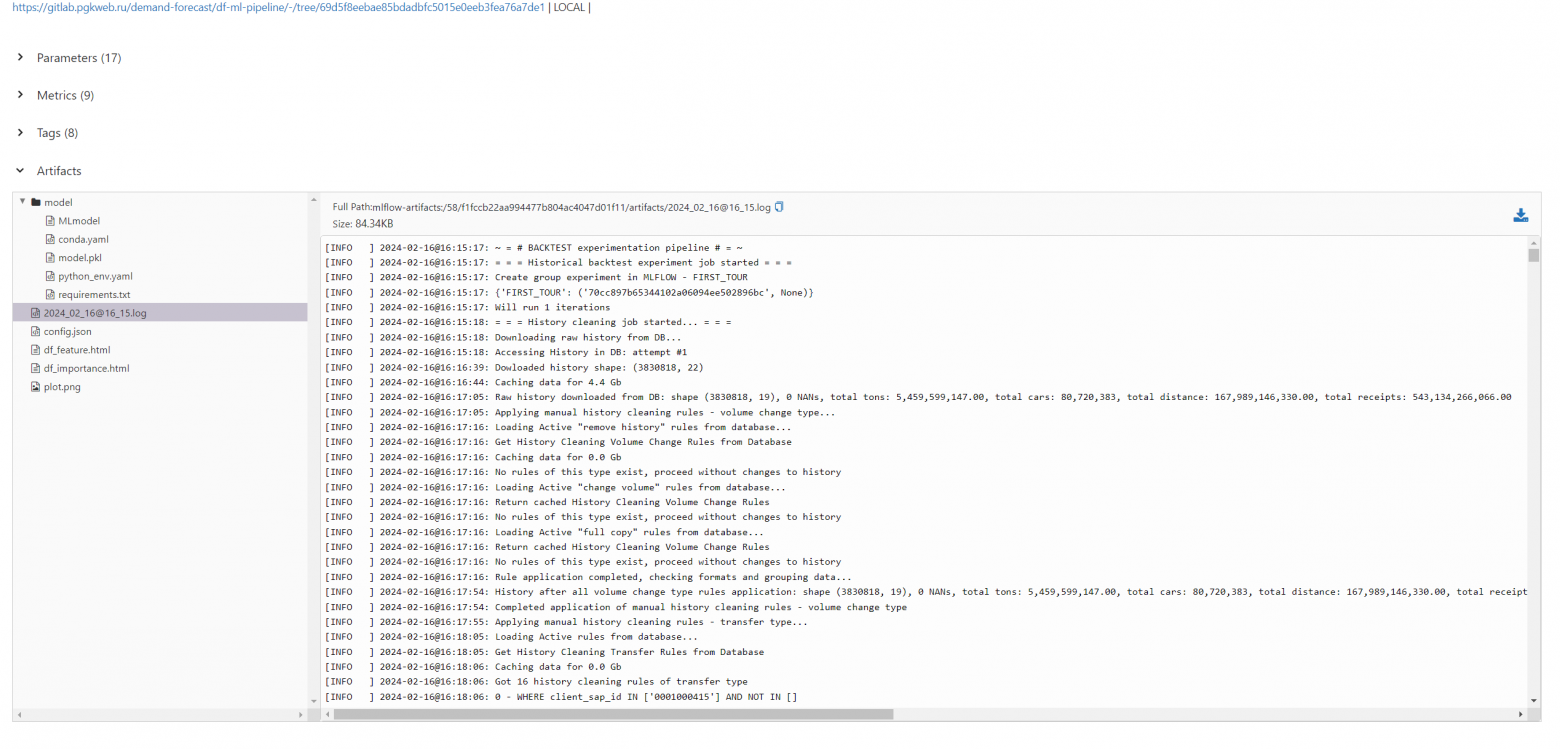
Отслеживать качество прогнозов также помогают специальные теги. Они отражают, какая модель была использована, какая сборка запущена, в какой гранулярности проводились расчёты.
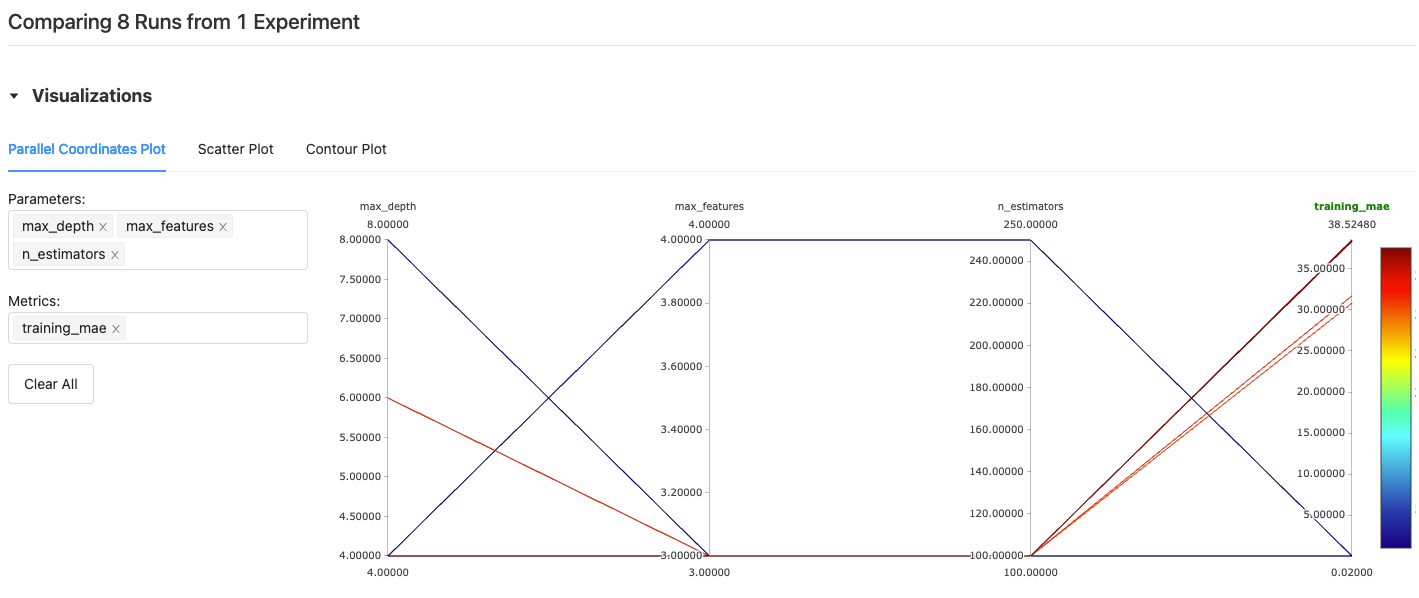
В то же время инструментарий для визуализации помогает строить графики качества прогнозов.
Планы
Переход на MLflow позволил нам организовать хранение артефактов и метрик, а также упростил верхнеуровневый анализ результатов тестирования. Обновление весов стало тривиальной проблемой, и мы получили возможность уделять больше времени разработке.
Для проекта «Прогнозатор» в рамках использования MLflow мы планируем прописать метрики для ансамблей моделей и развивать MLflow в ПГК; возможно, добавить плагины. Также к нам часто приходят с запросами на построение моделей из других отделов Первой грузовой компании. Поэтому мы планируем добавить в MLflow решения, способные не только предсказывать объёмы грузоперевозок, но и строить другие прогнозы. Одной из будущих задач может стать прогноз скорости оборачиваемости вагонопарка.
В отдаленной перспективе мы также планируем проработать функциональность, которая позволит оперативно выводить обновленные модели в продакшн. Например, после заведения модели в MLflow её можно будет опубликовать через MLflow Production, и она станет доступна через API.
# Пример запроса предсказания
import requests
data = {"inputs": [0.045341, 0.050680, 0.060618, 0.031065, 0.028702, 0.045341]}
requests.post("https://ml-platform/deploy/a55988a1-5299-4109-a6a6/test_deploy_auth/invocations",
json=data,
auth=("user", "Password"),
)
Таким образом, коллеги всегда будут использовать обновленный алгоритм. Допустим, у нас был эксперимент — получилась модель с точностью 0,5. Далее, в неё внесли изменения, и качество выросло до 0,92. Мы сможем в один клик переключиться на новый вариант — и дополнительной работы по распространению решения не потребуется.
Habrahabr.ru прочитано 7865 раз
