
Как ELK довел нас… до Vector.dev и Clickhouse

Меня зовут Дима Синявский, я SRE-инженер в Vi.Tech — это IT-дочка ВсеИнструменты.ру. В этой статье расскажу я вам о том как мы развивались и с нами развивалась наша система логирования. Почему вам нужен Vector.dev + Clickhouse для хранения и когда это выгодно.
Когда компания была маленькой нам хватало и блокнота, чего сейчас уже не скажешь.
У нас 931 000 пайплайнов в месяц, 4 кластера Kubernetes: от 170 до 190 нод в каждом, и 200 ГБ логов ежедневно.
Начало пути
Когда вы маленькая компания — у вас может быть один-три сервера, которые стоят прямо у вас в офисе. Вашим инженерам и разработчикам достаточно просматривать логи прямо на них. Для этого как никогда лучше подходит он:

cat
Конечно, вы не стоите на месте и вскоре логи начинают расти, расти, расти… и на помощь приходит он:

grep
Рост продолжался. И вот у нас уже поднимаются кластера Kubernetes, приложения расползаются каждый в свой pod — логов становится еще больше! Больше логов богу логов! Конечно, с grep тут уже по консолям не напрыгаешься.
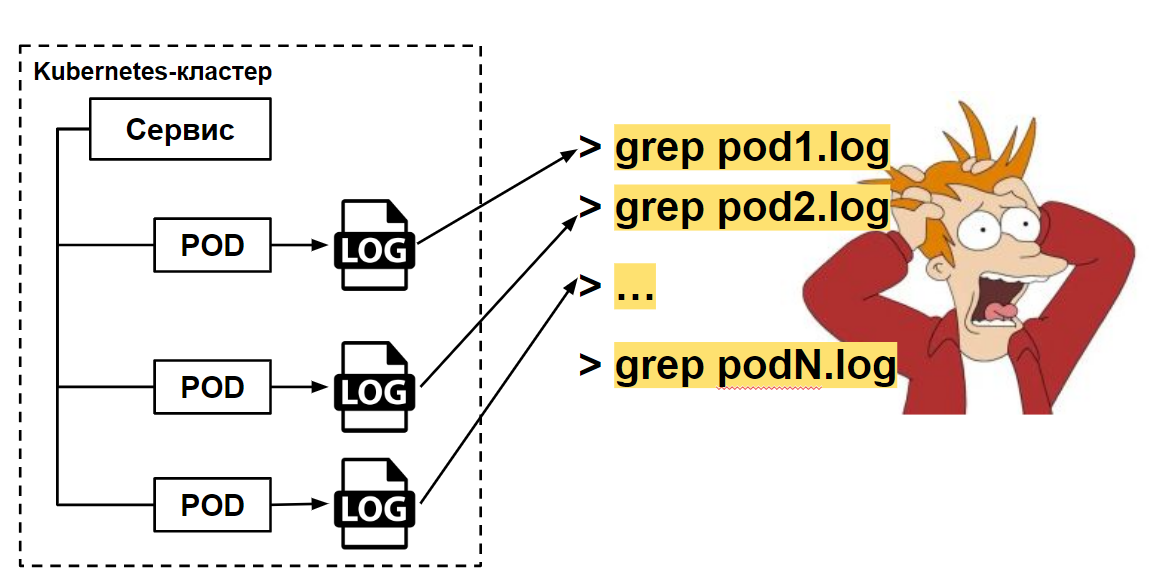
grep-ать по логам pod-ов
Как?! У нас уже кластер, а логи все еще неудобно искать?
Что первое что мы находим, когда ищем «Что взять для сбора логов в кластере Kubernetes?»
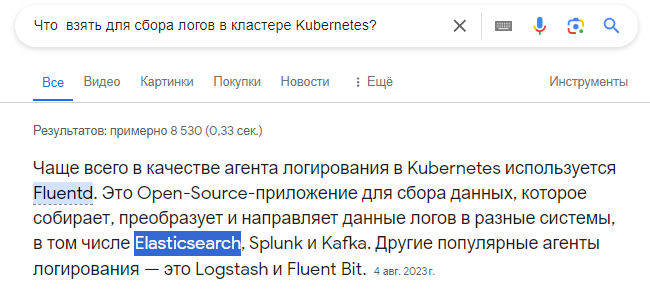
Типичный запрос ищущего, чем бы собрать логи
Мы также поискали и нашли популярное решение на базе Elastic, FluentD, Kibana (EFK). Это было бесплатно и хорошо описано, как поставить и настроить. Так мы и познакомились с стеком Elastic в 2018 году. И достаточно хорошо жили с ним. FluentD собирал нам логи, разработчики радостно искали их через Kibana, а DevOps обслуживали всё это, и все были довольны.

Наше знакомство в Elastic стеком для логов
В это время у нас уже почти все приложения переехали в Kubernetes и все это работало на двух физических дата-центах (ЦОД).
3 года с Elastic — полет нормальный! Или нет?
Наша компания росла и росла, а мир вокруг менялся и создавал все новые сложности.
В 2021 году EFK стал для нас тяжелым и дорогим, а FluentD преподносил сюрпризы
Elastic вырос с 4 до 18 нод
Затраты увеличились почти в 5 раз: с 45 тыс. руб. за 2 ноды в 2 ЦОДах (180 тыс. руб.) до 45 тыс. руб. за 6 нод в 3 ЦОДах (810 тыс. руб.).
Мы храним логи только за последние 5 часов. К тому же, FluentD теряет логи при отправке.
Поиск возможных решений. Почему Vector и ClickHouse
На момент выбора решения нас ограничивали внешние факторы, в том числе лимит на расширение ресурсов, из-за которого приходилось долго ждать подвоза «железа».
Что было важно:
Перестать терять логи.
Уложиться в лимит.
Хранить логи минимум за последние 4 дня.
У нас было два возможных пути:
Продолжать «есть кактус» и пытаться как-то потюнить и переделать EFK под себя, но при этом ограничиваться записью логов только за последние 5 часов.
Перейти на новое решение — ClickHouse, Vector.dev и Redash.
Сравнение хранилищ и сборщиков логов
Мы провели сравнение хранилищ и сборщиков логов, осознавая, что придется идти на некоторые компромиссы.
Сравнили ClickHouse и Elastic ⭢ победил Clickhouse
ClickHouse использовал 9 нод вместо 18 на трех ЦОД → экономия в два раза.
В 8 раз уменьшилось потребление ресурсов при вставке логов (по CPU/Mem).
Занимаемое место под строку лога сократилось в 10 раз (с 600 байт у Elastic до 60 байт у ClickHouse).
Сравнили Vector.dev и FluentD ⭢ победил Vector
Vector агент требует в 10 раз меньше ресурсов памяти
При одинаковом росте загрузки с 0 до рабочей значительно меньше потребляет память
При большой нагрузке Vector успевает собрать почти в 3 раза больше логов
У Vector есть unit-тесты для обработчиков логов! Можно проверять правила обработки логов локально, не поднимая всех зависимостей (см. руководство «Unit testing Vector configurations»)
Vector не теряет логи — доставляет 99.98–100% (см. исследование «Switching From FluentD to Vector Log Aggregation Tool»)
Риски перехода на новое решение
Vector.dev не имеет «стабильной» версии 1.0, прихоидиться мигрировать с учётом потенциально обратно несовместимых изменений.
Разработчики вынуждены отказаться от Kibana. Альтернативные решения на основе для ClickHouse либо не были доступны, либо уже находились в заброшенном состоянии.
При выборке логов необходимо изменить язык запросов с KQL на SQL.
Требуется перевод наших приложений на новую систему хранения логов.
Мы приняли эти риски, так как у нас были специалисты с опытом работы с ClickHouse, и нас устроила экономия ресурсов, которую предоставляет это решение по сравнению с предыдущими затратами.
Технические аспекты перехода и развертывание новой системы
Переход к новой системе управления логами с использованием Vector и ClickHouse был волнующим и вызывающим проектом, который потребовал от нас глубокого погружения в технические детали и тщательного планирования.
Подготовка к переходу на Vector + ClickHouse
Первым шагом был анализ текущей архитектуры и определение ключевых требований к новой системе. Нам нужно было убедиться, что переход не повлияет на стабильность работы наших сервисов и будет максимально плавным. Мы разработали детальный план миграции, включая параллельную работу систем в тестовом режиме для минимизации рисков. Важными моментами были:
Сбор логов с двух монолитов (критически важных);
Не влиять на производительность приложений при сборе логов;
Не терять логи и хранить их за 4 дня, вместо текущих 8 часов;
Обеспечить высокую доступность данных логов.
Развертывание
Мы рассмотрели несколько схем развертывания и выбрали одну, которая соответствовала нашим требованиям. Процесс начался с рассмотрения возможных конфигураций развертывания Vector — топологий.
Топология »Vector as Distributed Agent» — не подошла
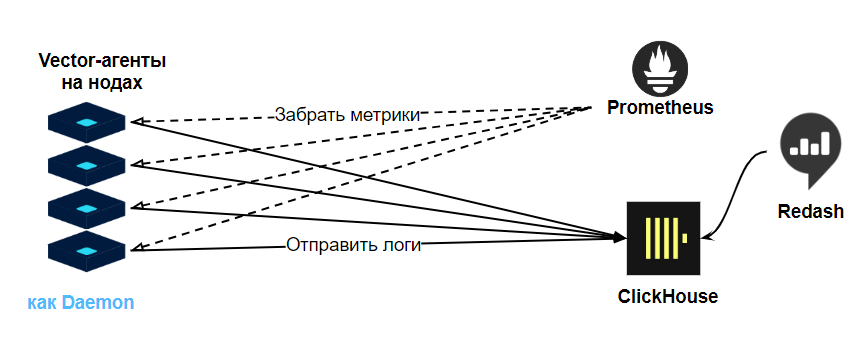
Топология Vector as Distributed Agent
Не подошла по следующим причинам:
Возможны потери логов при перезагрузке агентов или потери связи с хранилищем.
Агенты могут перегрузить хранилище ClickHouse.
Невозможно агрегировать данные с нескольких источников до их отправки в хранилище.
Вычислительная нагрузка агента может забирать много ресурсов и негативно влиять на работу приложений.
Можно перегрузить метриками Prometheus одним агентом с некорректными правилами.
Топология «Vector Centralized» — не подошла
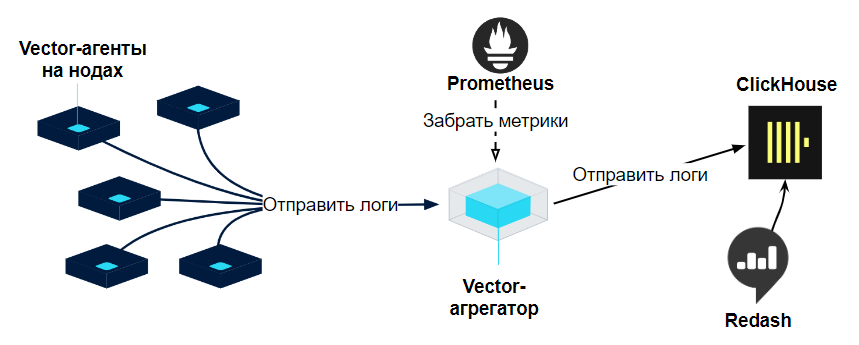
Топология Vector Centralized
Эта топология оказалась лучше предыдущей, поскольку вычислительную нагрузку перенесли с агентов на агрегаторы, и можно контролировать поток событий в хранилище (пропускание и rate-limit). Однако она не подошла нам по следующим причинам:
Возможна потеря логов при переполнении буферов агентов.
Риск потерь данных также возникает при рестарте агрегатора.
Топология «Vector Stream based» — подошла
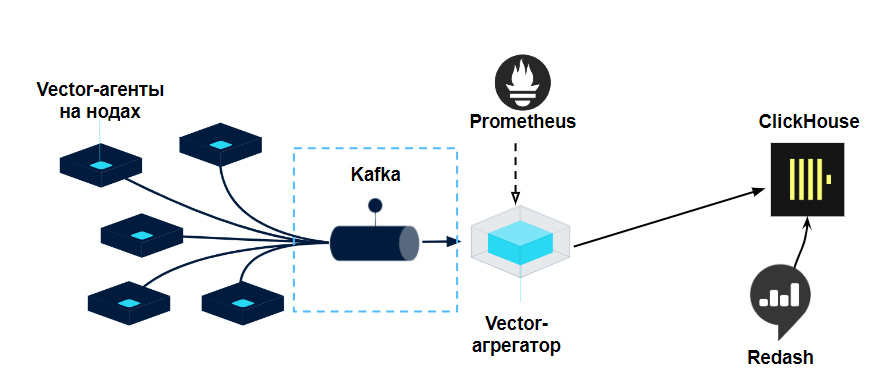
Топология Vector Stream based
Эта топология позволила удовлетворить все наши требования. Kafka, которую мы используем в компании и умеем поддерживать, — стала надежным буфером в моменты перезагрузки. Мы выдерживали простой агрегатора vector до 30 минут, с накоплением более 50 млн сообщений в Kafka.
Надежная конфигурация Vector + ClickHouse для трех ЦОД
Поскольку наша компания обеспечивает надежность работы приложений при помощи трех ЦОД, система обработки и хранения логов была развернута в такой же конфигурации.
В каждом ЦОД была развернута топология Vector Stream Based. Агенты Vector собирают логи и отправляют их сразу в Kafka. Агрегатор Vector проводит обработку логов, включая обогащение и подсчет метрик, после чего отправляет логи в хранилище ClickHouse. За метриками в агрегатор приходит наша Victoria Metrics.

Схема развертывания системы сбора и обработки логов и метрик в одном ЦОД
Далее все ЦОД связаны между собой избыточными связями, что позволяет перераспределить нагрузку при выходе из строя одного из элементов схемы.
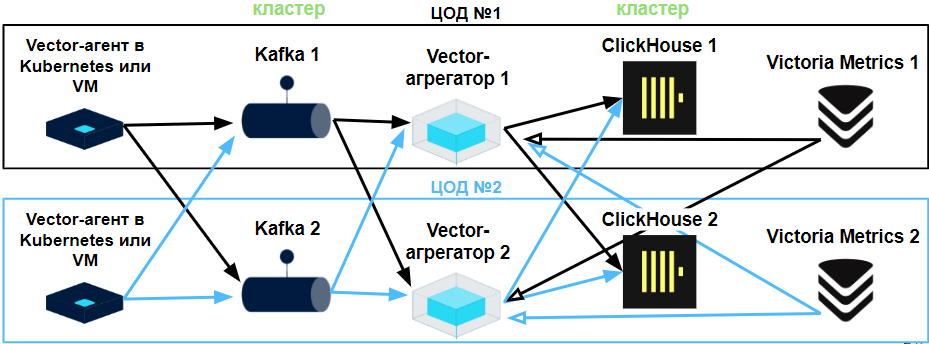
Схема развертывания системы сбора и обработки логов и метрик в двух ЦОД
а схеме выше вы видите взаимные связи элементов топологии для двух ЦОД. У нас три ЦОД, поэтому каждый элемент имеет по три связи. Мы не отображаем это на схеме, чтобы избежать перегрузки информацией. Kafka работает в кластере, так же как и ClickHouse. Victoria Metrics настроена в отказоустойчивой конфигурации.
Как мы храним логи в ClickHouse
Так как у нас не было опыта работы с логами в ClickHouse, мы выбрали прямолинейную схему размещения данных, где для каждого приложения завели отдельную таблицу, а каждому полю лога соответствует столбец в таблице. Дополнительные данные, которые Vector предоставляет о среде создания лога (например, данные о kubernetes), мы разместили в виде двух вложенных столбцов типа массив в поле other {other.key, other.value}.
У каждой таблицы указан TTL, чтобы ClickHouse автоматически очищал устаревшие логи. Мы разработали ansible плейбуки для автоматизации создания нужных таблиц, избегая необходимости каждый раз привлекать администраторов баз данных при добавлении логов нового приложения.
Обработка логов vector-агрегатором
Наши приложения отправляют структурированные JSON-логи, которые достаточно просто обрабатывать на агрегаторе и обогащать при необходимости. Vector может обрабатывать различные виды логов, включая логи сторонних приложений, которые не используют JSON, приводя их к нужному формату.
Работа с логами, поиск и выборка логов
Для работы с логами мы предлагаем прямое подключение к базе через различные клиенты, а также через ReDash — графическую веб-консоль для выполнения запросов в ClickHouse. Хотя это не предоставляет такого удобства, как Kibana, для нас это осознанный компромисс. Преимуществом является то, что разработчикам не требовалось изучать с нуля новый язык запросов, так как SQL известен почти всем.
Переход занял 1 год. Что мы получили?
Все прод-сервисы переведены на сбор логов через vector.dev.
Экономия ресурсов: количество нод уменьшилось в 8–10 раз, место для логов — в 10 раз.
Логи продовых систем теперь хранятся 4 дня вместо 5 часов.
Не теряем логи — доставляется 99.98–100%.
DevOps и CTO довольны.
Разработчики привыкли к надёжности системы: логи не теряются.
Достижения, которые мы смогли реализовать благодаря переходу на Vector и ClickHouse, наглядно демонстрируют важность выбора правильных инструментов для управления логами. Мы успешно сократили потребление ресурсов на обработку и хранение логов в рамках установленных ограничений, обеспечив запас ресурсов для роста компании.
Как это может пригодиться вам
После успешного перехода на новую систему управления логами, основанную на Vector и ClickHouse, мы оглядываемся назад с ощущением глубокого удовлетворения от проделанной работы. Однако впереди нас ждут новые вызовы и возможности. В заключительной части этой статьи я хотел бы дать несколько советов тем, кто рассматривает возможность аналогичных изменений в своей системе.
Когда вам НЕ нужен переход на Vector + ClickHouse
Вы небольшая компания с несколькими серверами и у вас нет множества приложений.
У вас достаточно ресурсов для тюнинга и адаптации решений из Elastic стека под свои нужды.
У вас достаточно ресурсов для расширения мощностей под Elastic, чтобы решить проблему «железом».
Когда вам это нужно
Ваша компания растет, но не хватает ресурсов на расширение мощностей для Elastic.
Вы используете сборщик логов FluentD, и при вашей нагрузке он теряет логи.
Заключение
Переход на новую систему управления логами был для нас важным шагом, который не только решил множество существующих проблем, но и открыл перед нами новые возможности для развития и совершенствования наших сервисов. Мы надеемся, что наш опыт окажется полезным для всех, кто стоит на пороге подобных изменений, и поможет вам сделать вашу систему логирования более эффективной и надежной.
Habrahabr.ru прочитано 7607 раз
