
ChatGPT и отзывы на приложение: Анализ тональности для улучшения пользовательского опыта

Автор статьи: Николай Задубровский, выпускник OTUS.
Исследование выполнено под руководством @mashkka_t (автор канала Mashka про Data Science) в рамках выпускного проекта на курсе Machine Learning в OTUS.
Привет, дорогие читатели Хабра!
Сегодня я хочу поделиться с вами своими знаниями и опытом в области анализа данных и машинного обучения, освещая увлекательную и актуальную тему — анализ отзывов на приложения с использованием модели ChatGPT. Этот подход открывает новые горизонты для понимания тональности отзывов, что является ключевым аспектом в изучении общественного мнения.
В этой статье я расскажу о том, как можно использовать возможности Natural Language Processing (NLP) для анализа отзывов, собранных из приложения AppStore. Я исследую, как каждый отзыв, содержащий дату, заголовок, текст и оценку пользователя, может быть преобразован в ценные данные для обучения модели анализа тональности. Эта модель будет способна классифицировать отзывы как положительные, негативные или нейтральные, предоставляя нам глубокое понимание эмоциональной окраски пользовательских мнений.
Понимание тональности отзывов имеет огромное значение для бизнеса, маркетинга и стратегического планирования, так как позволяет компаниям лучше реагировать на потребности и ожидания клиентов. Присоединяйтесь ко мне в этом путешествии по миру NLP, где я раскрою потенциал машинного обучения для улучшения взаимодействия с клиентами и оптимизации бизнес-процессов.

Давайте вместе разберёмся в деталях шаг за шагом, как можно использовать различные модели для глубокого анализа отзывов на приложение ChatGPT в AppStore и точного определения их тональности.
В рамках исследования я применил ряд передовых библиотек машинного обучения и обработки естественного языка, включая: Naive Bayes, Linear Regression, Logistic Regression, SVM (Support Vector Machine), Decision Tree, XGBoost и CatBoost.
В дополнение к традиционным методам моя работа включала использование нейронных сетей и трансформеров, которые являются фундаментальными инструментами для широкого спектра задач машинного обучения. Эти модели, особенно трансформеры, такие как BERT и RoBERTa, проявили себя как чрезвычайно мощные в задачах NLP благодаря их уникальной архитектуре, способной эффективно обрабатывать большие объёмы данных. Обработка информации осуществлялась с использованием высокопроизводительных GPU и CPU, что значительно ускорило вычисления и повысило эффективность обучения моделей.
Для анализа и визуализации данных я использовал Jupyter Notebook– удобную среду, которая позволяет выполнять код, визуализировать результаты и делиться выводами в интерактивном формате.
В этой части я хочу рассказать, как я подготовил данные к машинному обучению.
Загрузка набора данных
Посмотрим на данные:

Наш анализ будет основан на таблице отзывов, структурированной в четыре ключевых столбца: дата публикации, заголовок отзыва, содержание отзыва и рейтинг пользователя. Эти данные предоставляют нам богатый источник информации для глубокого анализа тональности, позволяя классифицировать отзывы на положительные, отрицательные и нейтральные, что даёт ценное понимание общественного восприятия и пользовательского опыта.
Просмотрим рейтинг:

Анализ данных показывает, что рейтинги отзывов охватывают широкий диапазон от 6.06 до 49.48, что отражает широкий спектр пользовательских впечатлений и оценок нашего продукта.
Посмотрим на классы:

Также видим, что у нас пять классов отзывов.
Проведём кодировку:
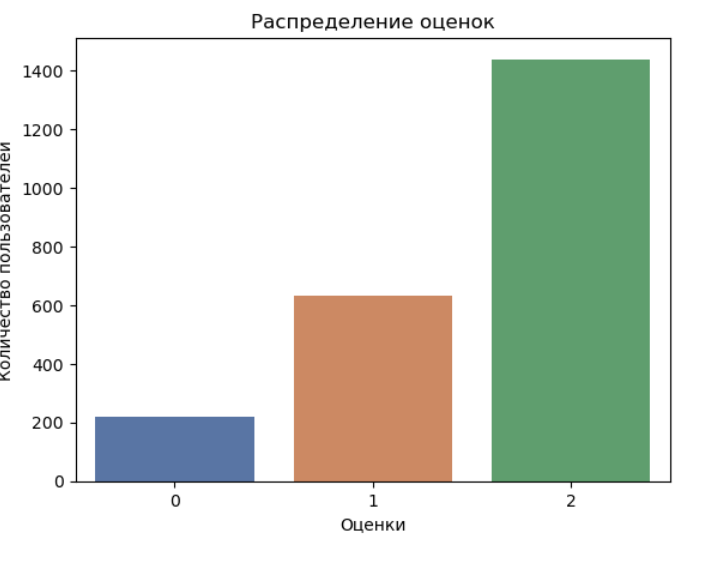
Проводим кодировку классов на положительные, отрицательные и нейтральные. Примечание: видим, что классы не сбалансированы.
Посмотрим, что у нас получилось — выберем классы:

Выберем все примеры с положительным классом.

Выберем все примеры с отрицательным классом.
Прежде, чем перейти к ML, текст необходимо предобработать.
Токенизация
Создадим и применим токенизатор к каждому обзору в датасете:

Посмотрим, как работает токенизатор и как он разделяет текст на составные части.
Теоретическая справка. Токенизатор нужен для разбиения текста на отдельные слова и знаки препинания. Он использует регулярное выражение для поиска границ между словами и символами.
Найдём и расширим список стоп — словами:
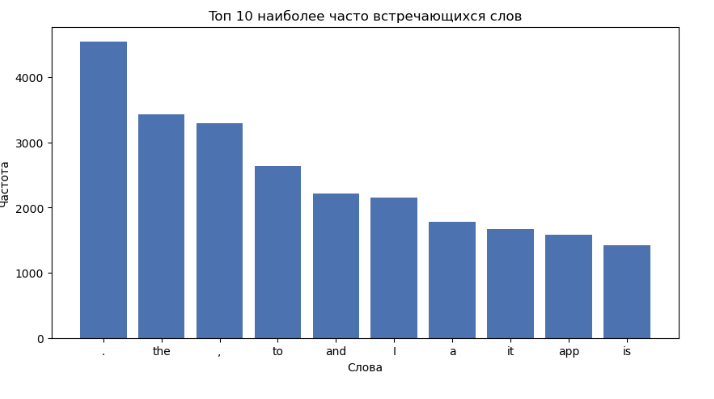
Посмотрим на топ 10 наиболее часто встречающихся слов.
Теоретическая справка: Стоп-слова (stop words) — это слова, которые часто встречаются в тексте и не несут значимой информации.
Вывод. Цель этих действий — подготовить тексты для дальнейшего анализа.
Проведём нормализацию слов стеммером для английского языка.

Теоретическая справка: нормализация слов — это процесс приведения слов к их базовой форме. Это важный шаг в предварительной обработке текстовых данных, особенно при работе с естественным языком.

Разобьём собранные данные на train/test, отложив 20% наблюдений для тестирования.

Это позволит оценить, насколько хорошо наша модель будет работать на новых данных, которые она ранее не видела.
Применим tf-idf преобразование для текстового описания.

Посмотрим на первые 10 строк.
Видим, что текстовые данные преобразованы в числовые значения.
Теоретическая справка: TF-IDF это статистическая мера, которая используется для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. TF-IDF высокий, если слово часто встречается в документе, но редко в других документах, что означает, что оно характеризует документ. TF-IDF низкий, если слово часто встречается во многих документах, что означает, что оно не специфично для документа.
Оцениваем линейные модели
1. Оценка точности классификатора логистической регрессии
2. Оценка точности линейной регрессии с использованием метрики RMSE
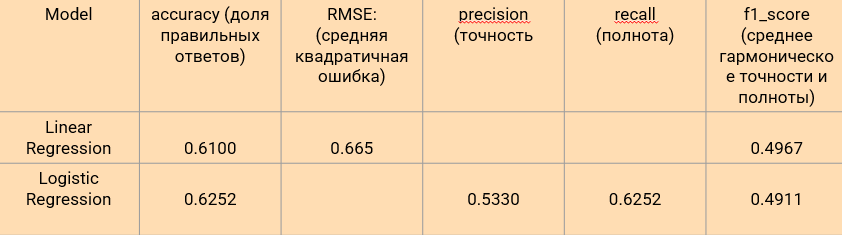
1. Значения: Точность (Precision), Полнота (Recall), F1-мера, указывают на умеренную точность модели логистической регрессии.
2. RMSE (Root Mean Squared Error) «среднеквадратическая ошибка» линейной регрессии, — показывает, насколько хорошо модель предсказывает целевую переменную по сравнению с фактическими значениями. Значение RMSE 0.6657626243604827 указывает на среднюю ошибку предсказания в рамках данного масштаба.
Оцениваем различные модели
Сравниваем и оцениваем качество шести моделей: Naive Bayes, Logistic Regression
SVM (Support Vector Machines), Decision Tree, XGBoost, CatBoost.
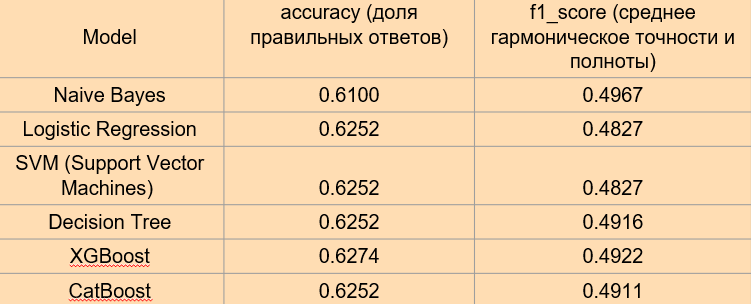
Выводы:
Наивный Байес (Naive Bayes): с наименьшей точностью в 0.6100 и F1-баллом 0.4967, Наивный Байес показывает ограниченную эффективность в сравнении с другими рассмотренными моделями.
Линейная Регрессия (Linear Regression): с RMSE в 0.6658, эта модель применима в контексте регрессии, но её показатели несопоставимы с классификационными метриками, такими как точность и F1-балл.
Логистическая Регрессия (Logistic Regression), Метод Опорных Векторов (SVM) и Дерево Решений (Decision Tree): все три модели демонстрируют схожую точность в 0.6253, однако отличаются по F1-баллу, где Дерево Решений выделяется с более высоким показателем.
XGBoost: превосходит другие модели с точностью 0.6275 и F1-баллом 0.4922, указывая на свою эффективность в классификации.
CatBoost: показывает результаты, сопоставимые с Логистической Регрессией, SVM и Деревом Решений, как по точности, так и по F1-баллу.
Общий вывод:
Из анализа следует, что XGBoostвыделяется как наиболее предпочтительная модель с точки зрения точности и F1-балла. Тем не менее, учитывая небольшую разницу в показателях между моделями, выбор может зависеть от специфики задачи и значимости определённых метрик. В сценариях, где критично минимизировать ложноположительные и ложноотрицательные результаты, следует уделить особое внимание F1-баллу, где XGBoost также показывает сильные результаты. Это подчёркивает важность комплексного подхода к выбору модели, основанного на целях и требованиях конкретного исследования или приложения.
В рамках нашего исследования я использую современные модели для анализа тональности
BERT (Bidirectional Encoder Representations from Transformers): модель, использующая механизмы трансформеров для анализа контекста слов в тексте отзывов. Она учитывает двунаправленный контекст, что позволяет глубже понять значение и эмоциональную окраску каждого слова в предложении.

RoBERTa: это улучшенная версия BERT, оптимизированная для более точного понимания контекста и классификации текста.
Рассмотрим BERT (Bidirectional Encoder Representations from Transformers):
Токенизация & Форматирование

В данной секции преобразуем данные к формату, с которым работает BERT.
Обучение модели
Я использую класс `BertForSequenceClassification`, который представляет собой предобученную модель BERT с добавленным классификационным слоем. Этот слой позволяет модели классифицировать отзывы на положительные, негативные и нейтральные.
Посмотрим на метрики обучения и производительности для оценки эффективности модели.
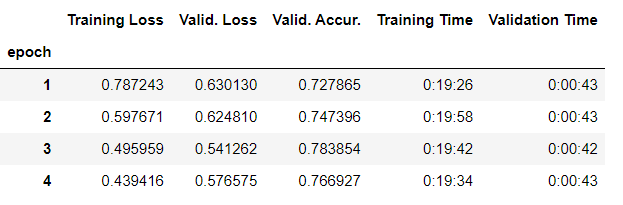
Выводы:
Точность (Accuracy) измеряет долю правильно классифицированных примеров от общего числа примеров. Это метрика, которая позволяет оценить, насколько хорошо модель способна правильно предсказывать классы данных.
Снижение точности на валидационных данных (Valid. Accur.) с каждой эпохой указывает на переобучение модели (overfitting).
Переобучение происходит, когда модель становится слишком специализированной на обучающих данных и начинает «запоминать» их, что приводит к ухудшению её способности обобщать информацию на новых, неизвестных данных. Это может привести к тому, что точность на валидационных данных начнёт падать или даже остановится на определённом уровне, что является признаком переобучения.
Наименьшее значение потерь на валидационных данных (Valid. Loss) на третьей эпохе, равное 0.54, указывает на то, что модель достигла наилучшего баланса между обучением и валидацией на этом этапе. Это означает, что модель начинает обобщать информацию хорошо на новых данных, которые не были использованы в процессе обучения, что является ключевым показателем хорошей производительности модели.
Посмотрим на график «Ошибка обучения» и «Ошибка валидации».
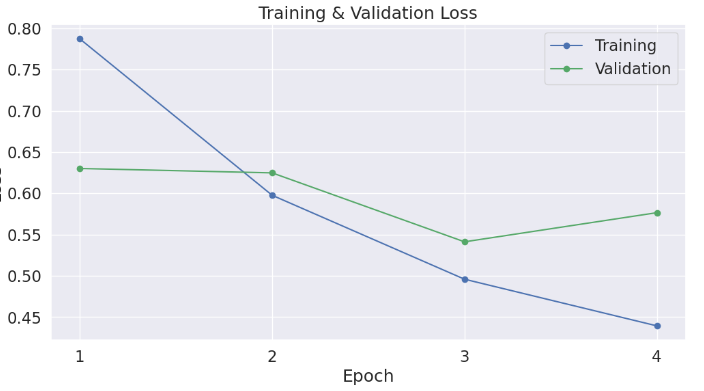
Исходя из графика видно, что третья эпоха является наиболее оптимальной для модели, так как в ней наблюдается самая низкая валидационная потеря (0.541262) и самая высокая точность на валидационном наборе данных (0.783854). Это указывает на то, что модель хорошо обобщает и не переобучается — в отличие от четвертой эпохи, где, несмотря на уменьшение потерь на обучающем наборе, валидационная потеря увеличивается, что может быть признаком начала переобучения.
Вывод:
Анализируя результаты обучения модели по эпохам, мы можем сделать вывод, что модель достигла наилучшего баланса между способностью к обучению и обобщению в третьей эпохе.
Оценим метрику MCC
В качестве метрики возьмём Коэффициент корреляции Matthews correlation coefficient, сокращённо MCC.

Вывод:
После тщательной подготовки тестовых данных мы применили дообученную модель для генерации предсказаний. Для оценки качества модели был выбран Коэффициент корреляции Мэтьюса (MCC), который является надёжной метрикой в условиях несбалансированных классов. Полученное значение MCC равное 0.721 свидетельствует о высоком качестве предсказаний модели. Это значение указывает на сильную корреляцию между предсказанными и фактическими классами, что подтверждает эффективность модели и её потенциал в решении поставленной задачи классификации. Таким образом, дообученная модель демонстрирует отличные результаты и может быть использована для дальнейшего анализа данных или в реальных приложениях.
Модель RoBERTa (Robustly Optimized BERT Pretraining Approach) является модификацией модели BERT, разработанной Facebook AI:
Токенизация & Форматирование

Чтобы подать на вход текст в Roberta, его необходимо разбить на токены, а затем закодировать токены их порядковыми индексами в словаре.
Обучение модели
После того как данные были успешно отформатированы для соответствия требованиям входных данных модели, я перешёл к этапу обучения. Для этой цели была выбрана модель RoBERTaForSequenceClassification, которая представляет собой архитектуру RoBERTa, дополненную линейным классификационным слоем. Этот слой расширяет базовую модель, позволяя ей выполнять задачи классификации последовательностей, такие как определение тональности текста.
Посмотрим на метрики обучения и производительности для оценки эффективности модели.
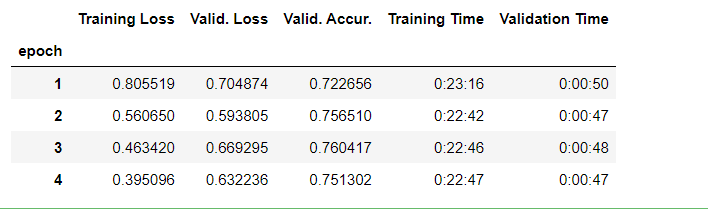
Выводы:
Потеря на тренировочных данных (Training Loss): постепенно уменьшается с каждой эпохой, что является хорошим знаком. Это означает, что модель продолжает обучаться и улучшать свои параметры, чтобы лучше предсказывать классы на тренировочных данных.
Потеря на валидационных данных (Valid. Loss): сначала уменьшается, но затем начинает увеличиваться, что может указывать на начало переобучения модели. Это происходит, когда модель начинает «запоминать» тренировочные данные, что приводит к ухудшению её способности к обобщению на новые, ранее невидимые данные.
Точность на валидационных данных (Valid. Accur.): увеличивается с каждой эпохой, что является хорошим знаком. Это означает, что модель продолжает улучшать свою способность к предсказанию классов на валидационных данных.
Исходя из этих данных, можно предположить, что модель достигла оптимального состояния обучения примерно на второй эпохе, когда потеря на валидационных данных начала увеличиваться, в то время как точность на валидационных данных продолжала улучшаться. Это указывает на то, что модель может начать переобучаться
Посмотрим на график «Ошибка обучения» и «Ошибка валидации».
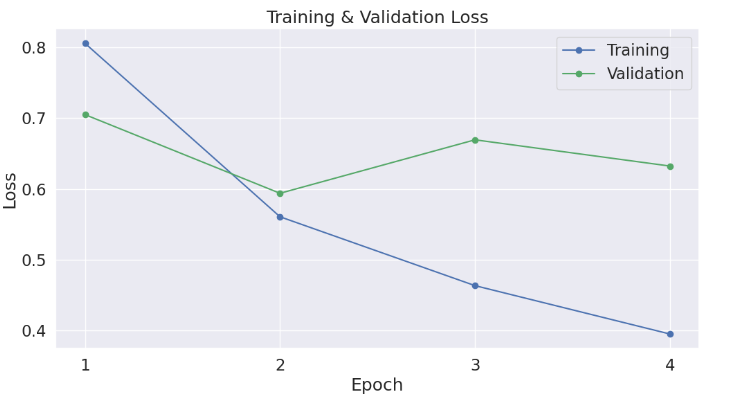
Анализируя метрики по эпохам, мы видим, что вторая эпоха показывает наилучшие результаты с точки зрения баланса между потерями на обучающем и валидационном наборах данных и точностью валидации. Несмотря на то, что третья эпоха демонстрирует самую высокую точность валидации (0.760417), увеличение валидационных потерь по сравнению со второй эпохой может указывать на начало переобучения. В то же время четвертая эпоха, несмотря на самые низкие потери на обучении, показывает увеличение валидационных потерь и снижение точности валидации по сравнению с третьей эпохой, что также может быть признаком переобучения.
Следовательно, вторая эпоха является оптимальной точкой остановки обучения, так как она обеспечивает наилучшее соотношение между обучением и валидацией, минимизируя риск переобучения и максимизируя обобщающую способность модели.
Оценим метрику MCC
В качестве метрики возьмём Коэффициент корреляции Matthews correlation coefficient, сокращённо MCC.
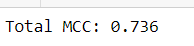
Вывод:
После того как тестовые данные были тщательно подготовлены, мы использовали дообученную модель RoBERTa для генерации предсказаний. В качестве ключевой метрики оценки качества модели был выбран Коэффициент корреляции Мэтьюса (MCC), который является особенно подходящим для сценариев с несбалансированными классами. Значение MCC, равное 0.736, указывает на высокую степень корреляции между предсказанными и фактическими значениями, что свидетельствует о значительной точности и надёжности модели в задачах классификации. Этот результат подчёркивает эффективность дообучения модели RoBERTa и её применимость для анализа данных в условиях, когда баланс классов является критическим фактором.
Выводы по исследованию:
Уважаемые читатели, наша исследовательская работа представила углублённый сравнительный анализ между классическими методами машинного обучения и новаторскими языковыми моделями. Традиционные подходы, такие как логистическая регрессия и деревья решений, продолжают показывать себя как надёжные и доступные инструменты. Однако, они зачастую не могут соперничать с более современными методами в плане точности и сложности обработки данных.
С другой стороны, передовые языковые модели, основанные на архитектуре трансформеров, в частности RoBERTa, продемонстрировали значительные успехи в решении задач обработки естественного языка. Благодаря способности эффективно обрабатывать обширные наборы данных и глубоко понимать языковой контекст, эти модели не только повышают точность классификации текстов, но и открывают новые горизонты для анализа и создания естественного языка.
Результаты нашего исследования однозначно подтверждают, что современные языковые модели являются мощным инструментом для анализа данных, и они обладают потенциалом стать фундаментом для будущих инноваций в сфере машинного обучения и искусственного интеллекта.
Благодарим вас за внимание и интерес к моей работе!
Habrahabr.ru прочитано 11474 раза
