
[Из песочницы] Как создать модель точнее transfermarkt и не предсказывать или что больше всего влияет на стоимость трансферов
Я постараюсь рассказать вам насколько легко получить интересные результаты, просто применив совершенно стандартный подход из тьюториала курса по машинному обучению к не самым используемым в Deep Learning данным. Суть моего поста в том, это может каждый из нас, надо просто посмотреть на тот массив информации, который вы хорошо знаете. Для этого, фактически, гораздо важнее просто хорошо понимать свои данные, чем быть экспертом в новейших структурах нейросетей. То есть, на мой взгляд, мы находимся в той золотой точке развития DL, когда с одной стороны это уже инструмент, которым можно пользоваться без необходимости быть PhD, а с другой — еще полно областей, где его просто особо никто не применял, если посмотреть чуть дальше традиционных тем.

Читая статьи и мимоходом смотря как развивается машинное обучение, у нас с вами легко может создаться ощущение, что этот поезд проносится мимо. Действительно, если взять самые известные курсы (например Andrew Ng) или большинство статей на Хабре от того же отличного сообщества Open Data Science очень быстро понимаешь, что без выковыривания из глубин памяти институтских знаний по высшей математике тут делать нечего, что ну хоть каких-то вменяемых результатов (даже в 'игрушечных' примерах) можно достичь только после нескольких недель изучения махровой теории и разных способов ее имплементации. Но часто хочется другого, хочется иметь инструмент, который выполняет свою функцию, который решает определенный класс задач, чтобы, применив его в своей сфере, получить результат. Ведь в других областях все именно так, если вы, например, пишите игру и у вас задача — обеспечить передачу информации от игрока к серверу, то вы не изучаете теорию графов, не выясняете как оптимизировать связанность, чтобы ваши пакетики быстрее доходили — вы берете инструмент (библиотеку, фреймворк), который делает это за вас и сосредотачиваетесь на том, что уникально для конкретной задачи (например, какую именно информацию надо туда и обратно передавать). Почему же для deep learning это не так?
На самом деле, сейчас мы стоим на пороге того времени, когда становится уже почти так. И для себя я почти такой инструмент нашел — fast.ai. Отличная библиотека и еще более крутой курс весь принцип которого как раз построен «сверху-вниз»: сначала решение реальных задач, зачастую на уровне точности предсказания State Of The Art-моделей, вниз — к внутреннему устройству библиотеки и теории, за ней стоящей.
Предвидя обвинения в непрофессионализме и поверхностности моих знаний (что, конечно, больше правда, чем нет), хочу сразу оговориться. Надо ли изучать теорию, смотреть те самые основополагающие лекции, вспоминать матричное исчисление и т.д.? Конечно, надо. И чем дальше вы будете погружаться в тему, тем больше вам это понадобится и придется прильнуть к первоисточникам. Но и тем осознаннее будет погружение, тем проще будет понять как именно эти самые основы влияют на получаемый результат. Весь смысл принципа «сверху-вниз» как раз и состоит в том, что надо это делать после. После того как вы уже написали что-то осязаемое, что можно показать знакомым. После того как вы уже достаточно погрузились в тему и она вас увлекла. И теория в курсе вас настигнет, просто она подается именно в тот момент, когда вам будет легче соотнести ее с тем, что вы уже сделали. В качестве объяснения того почему и как это на самом деле работает.
Я более чем уверен, что кому-то комфортнее традиционный подход «снизу-вверх». И это хорошо, что есть оба пути, главное, чтобы мы встретились посредине
Вот примерно с такими набором знаний я решил применить DL к теме, которая мне самому давно интересна и посмотреть к чему это может привести. И, конечно, первое, что мне пришло на ум — футбол. А когда я нашел на kaggle эту замечательную статистику по трансферам, то выбор стал тем более очевиден.
Немного про эти данные. Они содержат информацию о том кто и куда переходил в европейском футболе за последние 10 лет. Здесь есть информация о клубах, статистика игроков, лигах, в которых они участвуют, тренерах и агентах и многое другое (всего больше ста разных полей). Данные очень интересные, но можно ли по ним определить сколько игрок должен стоить?
Если задуматься, то цена игрока зависит от огромного количества факторов. При этом большая (если не большая) их часть просто неформлизуема. Как понять, что клуб только что задорого продал игрока, нуждается в нападающем и вполне готов за это переплатить; как понять, что пришел новый тренер и требует обновить состав; как понять, что главного защитника клуба приметил гранд и он начал играть вполсилы, требуя трансфер? Все это кардинальным образом влияет на сумму той или иной сделки, но не представлено в данных. От того изначальные ожидания о точности такого прогноза были у меня невелики.
На этом месте пора вставить стандартный disclaimer про то, что #яНенастоящийПрограммист, денег этим не зарабатываю, поэтому мой код ужасен, и, вероятнее всего, его можно (и нужно?) переписать намного лучше, но так как задача стояла исследовать идею и (не?)подтвердить теорию, то и код таков какой есть :)
Модель
Начал я с того, что исключил трансферы дешевле $1 млн, как уж слишком хаотичные. Затем все данные свел в одну большую таблицу с полутора сотней полей, в которой для каждого трансфера была вся доступная о нем информация (как о самом трансфере, игроке и его статистике, так и о клубах в нем принимавших участие, лигах и т.д.).
Рассмотрим по шагам как я создавал модель:
После того как мы выполнили все питоновские импорты и загрузили денормализованную таблицу по трансферам, первое что нам надо определить — какие из полей мы будем считать числовыми, а какие категориальными (categorical). Это сама по себе очень интересная тема, можно пообщаться про нее в комментариях, но для экономии времени я просто опишу правило которым я пользуюсь: я, по-умолчанию, считаю все поля категориальными, кроме тех, которые представлены в виде чисел с плавающей точкой или тех, где число разных значений достаточно велико.
В таком разрезе, например, 'год трансфера' я считаю категориальным, хотя это изначально число, потому что количество разных значений тут невелико (10 — от 2008 до 2018). А вот, например, результативность игрока в прошлом сезоне (которая у меня представлена средним количеством его голов за матч) является float-ом и может принимать почти любое значение, поэтому я его считаю числовым.
cat_vars_tpl = ('season','trs_year','trs_month','trs_day','trs_till_deadline',
'contract_left_months', 'contract_left_years','age', 'is_midseason','is_loan','is_end_of_loan',
'nat_national_name','plr_position_main',
'plr_other_positions','plr_nationality_name',
'plr_other_nationality_name','plr_place_of_birth_country_name',
'plr_foot','plr_height','plr_player_agent','from_club_name','from_club_is_first_team',
'from_clb_place','from_clb_qualified_to','from_clb_is_champion','from_clb_is_cup_winner',
'from_clb_is_promoted','from_clb_lg_name','from_clb_lg_country','from_clb_lg_group',
'from_coach_name', 'from_sport_dir_name',
'to_club_name','to_club_is_first_team','to_clb_place',
'to_clb_qualified_to', 'to_clb_is_champion','to_clb_is_cup_winner','to_clb_is_promoted',
'to_clb_lg_name','to_clb_lg_country',
'to_clb_lg_group','to_coach_name', 'to_sport_dir_name',
'plr_position_0','plr_position_1','plr_position_2', 'stats_leag_name_0', 'stats_leag_grp_0', 'stats_leag_name_1', 'stats_leag_grp_1', 'stats_leag_name_2', 'stats_leag_grp_2')
cont_vars_tpl = ('nat_months_from_debut','nat_matches_played','nat_goals_scored','from_clb_pts_avg',
'from_clb_goals_diff_avg','to_clb_pts_avg','to_clb_goals_diff_avg','plr_apps_0',
'plr_apps_1','plr_apps_2','stats_made_goals_0','stats_conc_gols_0','stats_cards_0',
'stats_minutes_0','stats_team_points_0','stats_made_goals_1','stats_conc_gols_1',
'stats_cards_1','stats_minutes_1','stats_team_points_1','stats_made_goals_2',
'stats_conc_gols_2','stats_cards_2','stats_minutes_2','stats_team_points_2', 'pop_log1p')Затем, после явного указания что же мы будем предсказывать — сумму трансфера (fee), мы случайно разделяем наши данные на 2 части по 80% и 20%. На первой из них мы будем учить нашу нейросеть, по другой — проверять точность предсказания.
ln = len(df)
valid_idx = np.random.choice(ln, int(ln*0.2), replace=False)На последнем подготовительном этапе нам надо сделать выбор как же мы будем измерять правдоподобность наших предсказаний. Тут я выбрал далеко не самую стандартную в местной части вселенной метрику — Медиану процента ошибки (MdAPE). Или, говоря проще, то на сколько процентов (абсолютная цена трансфера же может отличаться на порядки) скорее всего мы ошибемся в цене случайно взятого трансфера. Она мне показалась наиболее близкой к тому, что именно для меня значит фраза 'точность системы предсказания трансферов'.
Теперь настало время, собственно, начать обучение сети.
data = (TabularList.from_df(df, path=path, cat_names=cat_vars, cont_names=cont_vars, procs=procs)
.split_by_idx(valid_idx)
.label_from_df(cols=dep_var, label_cls=FloatList, log=True)
.databunch(bs=BS))
learn = tabular_learner(data,
layers=layers,
ps=layers_drop,
emb_drop=emb_drop,
y_range=y_range,
metrics=exp_mmape,
loss_func=MAELossFlat(),
callback_fns=[CSVLogger])
learn.fit_one_cycle(cyc_len=cycles, max_lr=max_lr, wd=w_decay)Точность предсказаний

Validation Error = 0.3492 значит, что после обучения на новом (проверочном, validation set) наборе данных модель в среднем (медиана) ошибается на 34% относительно реальной цены трансфера. И это у нас получилось всего лишь в результате работы нескольких строк кода, взятых из тьюториала.
34% ошибки, много это или мало? Все познается в сравнении. Единственным сравнимым источником, данные которого можно принять за 'предсказание' суммы трансфера, является, конечно, transfermarkt. К счастью, в данных с kaggle есть поле, которое показывает как этот сайт оценивал того или иного игрока на момент трансфера, с этим и можно сравнить. Здесь нельзя не отметить, что transfermarkt никогда не утверждал, что их market value это вероятная цена трансфера. Наоборот, они подчеркивали, что это скорее 'честная стоимость' того или иного игрока. А то сколько денег за него заплатит конкретный клуб в конкретной ситуации — вещь очень индивидуальная и может колебаться в ту или иную сторону в очень широких пределах. Но это лучшее, что у нас есть, давайте сравним.

Ошибка transfermarkt — 35%, нашей модели — 35%. Очень странно и, если честно, очень подозрительно.
На этом месте предлагаю еще раз задуматься. Сайт с огромной историей, созданный как раз для того, чтобы показывать 'стоимость' игроков, который опирается на всю мощь эффекта толпы (он выводит стоимость из оценок как обычных посетителей, так и профессионалов рынка) и знания экспертов с одной стороны, и модель, которая ничего о футболе не знает, ничего не видит кроме данных которые мы ей дали (а вне этих данных в реальном мире еще очень много чего есть, что люди с transfermarkt принимают во внимание) с другой, показывают одинаковую ошибку. Более того, наша модель позволяет предсказывать также и цену аренды игрока, что market value, по понятным причинам, не показывает (с учетом таких сделок результат transfermarkt был еще хуже).
Честно говоря, я все еще думаю, что у меня тут какая-то ошибка, все слишком хорошо, чтобы быть правдой. Но, тем не менее, пойдем дальше.
Простой способ проверить себя — это попробовать усреднить предсказания из 2-х источников (модели и transfermarkt). Если предсказания действительно независимы друг от друга и тут нет какой-то досадной ошибки, то результат должен улучшиться.

И правда, усреднение прогнозов снижает ошибку предсказания до 32% (!). Это может показаться немного, но надо понимать, что мы выцеживаем еще немного информации из данных, которые итак отжаты по максимуму.
Но то, что мы сделаем дальше, на мой взгляд, даже более удивительно и интересно, хотя и выходит за рамки тьюториала fast.ai.
Feature Importance
Нейросети, не сказать, что уж совсем незаслужено, зачастую считают 'черным ящиком'. Мы знаем какие данные туда можем положить, мы можем получить предсказания модели, мы даже можем оценить насколько ее предсказания в среднем верны. Но объяснить по каким именно критериям модель 'приняла' то или иное решение, мы не можем. Сама внутренняя структура сети настолько сложна, и что более важно, нелинейна, что впрямую проследить всю цепочку принятия решений и сделать оттуда значимые в реальном мире выводы, на данный момент, похоже, невозможно. Но очень хочется. Очень хочется понять что же больше всего влияет на сумму трансфера.
Хорошо, внутрь сети мы залазить не будем. Но что значит 'важность' каждого поля, назовем ее Feature Importance (FI)? Один из вариантов понять 'важность' — это посчитать насколько все станет хуже, если бы у нас данного поля не было. А это-то мы как раз можем измерить. У нас теперь есть инструмент, который дает предсказания на любом наборе данных. Так вот, если мы просто посчитаем насколько увеличится ошибка предсказания, когда подставим в поле случайные данные, то как раз сможем оценить насколько сильно оно (поле) влияет на конечный результат, а значит насколько оно 'важное'. Чтобы оставаться в рамках реального распределения данных, поле будем заполнять не просто случайными числами, а случайно перемешанными значениями его самого (то есть будем просто перемешивать столбец, например 'год трансфера', в исходной таблице). Для верности этот процесс можно провести по несколько раз для каждого поля, усреднив результат. Все достаточно просто. Теперь посмотрим насколько вменяемый это дает результат:
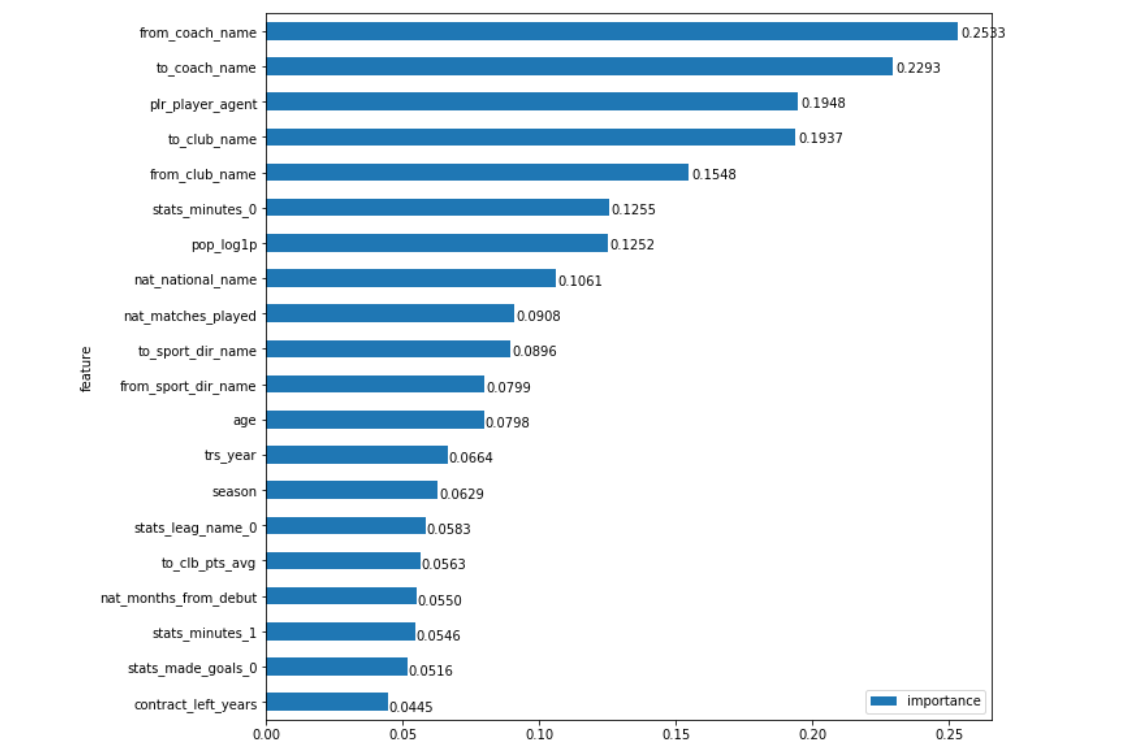
Мое чутье говорит: 'И да, и нет!'
С одной стороны сверху оказались поля которые ожидаешь там увидеть: тренеры команд откуда и куда игрок переходил (from_coach_name, to_coach_name), сами клубы участвовавшие в трансфере (from_club_name, to_club_name), агент игрока (plr_player_agent), его известность в соц.сетях (pop_log1p) и т.д. Но с другой… Интуитивно не кажется, что имена тренеров должны иметь больший вес в цене трансфера, чем, например, сами клубы (про то, что, условная Бенфика умеет дорого продавать своих игроков мы знаем хорошо). Неужели бренд тренера сильнее влияет на цену, чем бренд клуба. Неужели приход условного Манчини настолько сильно заставляет клуб переплачивать? Что это, тот случай, когда данные нам дают новую, немного контринтуитивную, информацию или просто ошибка в модели?
Давайте разбираться. При пристальном взгляде на график, глаз довольно быстро цепляется за странную вещь. Чуть ниже центра рядом находятся 2 поля trs_year и season, они представляют собой год совершения трансфера и сезон в который будет осуществлен переход (в общем случае, они могут не совпадать, хоть это и бывает не так часто). Во-первых, кажется, что они должны быть выше, мы знаем насколько сильно росли цены на футболистов в последние годы, а во-вторых они явно значат примерно одно и тоже. Что же с этим делать? Просто просуммировать их важность? Не факт, что так можно сделать! Но что мы точно можем сделать — так это применить тот же подход (перемешивание значений) не отдельно к двум этим полям, а группой. То есть измерить как изменится ошибка, если сразу в 2-х этих столбцах будут случайные значения. Ну и раз мы делаем так с годами, надо посмотреть нет ли у нас других настолько же 'связанных' полей.
Например, для клуба у нас есть несколько параметров: собственно сам клуб (club_name), а также набор информации о нем — из какой он лиги, страны и т.д. (club_is_first_team, clb_lg_name, clb_lg_country, clb_lg_group). Только в части случаев нам интересно узнать насколько влияет на цену, например, отдельно страна в которую переходит игрок (clb_lg_country), чаще всего нам важно понимать какой совокупный вес имеет поле 'клуб', который уже находится в определенной стране, лиге и т.д.
Таким образом мы можем объединить все поля в группы по смысловому наполнению. В этом нам поможет как просто знание предметной области и здравый смысл, так и рассчитанная 'близость' фич. Последняя как раз и показывает насколько поля коррелируют друг с другом, то есть насколько возможно их рассматривать как единую группу.
Применив этот подход получаем еще более соответствующий интуитивным представлениям график важности полей:
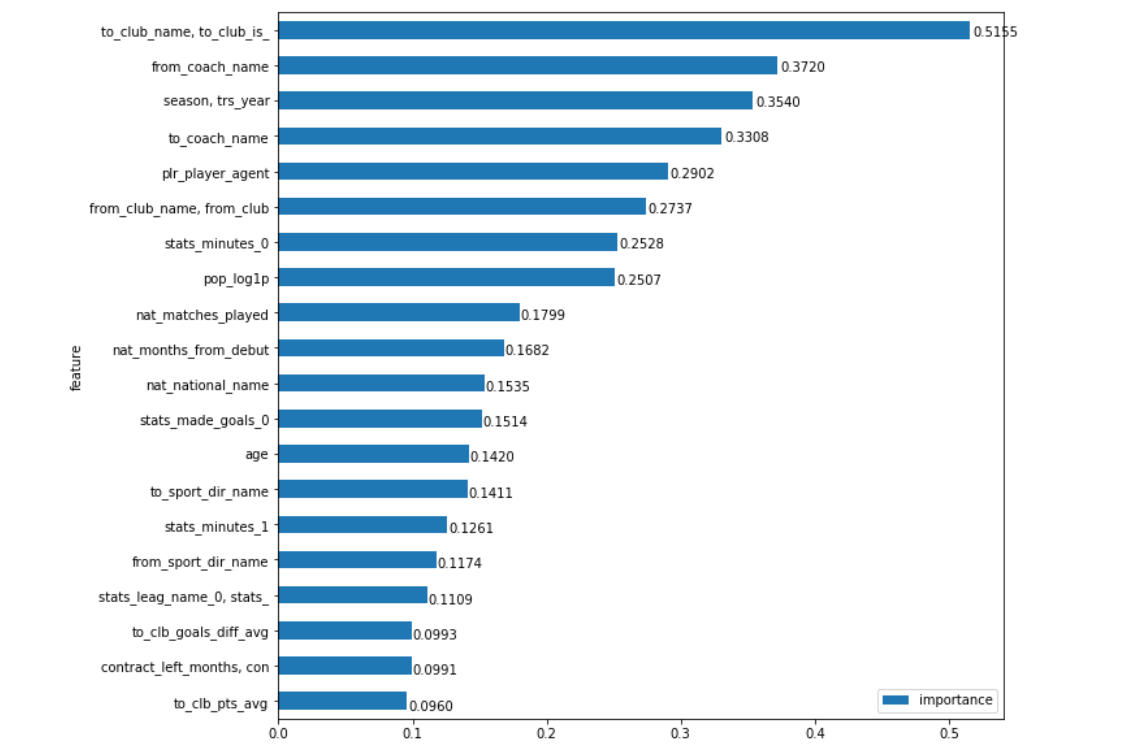
Вот так. Именно то, какой клуб покупает игрока в наибольшей степени влияет на сумму трансфера, с весьма хорошим отрывом. Привет Ман Сити, Барселона, Зенит и, например, та же Бенфика (ведь 'сильно влияет' это же и про то, что некоторые клубы наоборот умеют покупать качественных игроков дешевле 'рынка'). Это, как мне кажется, самое интересное в работе c данными — когда она получается, то выводы с одной стороны очевидны (ну ктож сомневался, что клуб-покупатель мощнейше влияет на сумму трансфера), а с другой — немного удивительные (и кандидатов на первое место, интуитивно, могло быть несколько, и отрыв от второго не казался таким существенным)
Здесь еще много всего интересного открывается. Например, имя тренера откуда игрок покупается, с точки зрения модели, все еще более важно чем клуб… Пусть разница и сильно сократилась. Логичное объяснение этому найти в принципе можно (хотя иногда его можно найти для чего угодно). Есть тренеры (Гвардиола, Клопп, Бенитес, Бердыев), придерживающиеся в разных клубах определенной идеологии игры, которая лучше раскрывает или наоборот делает менее яркими те или иные позиции на поле, а заметность игрока сильно влияет на его цену. Про клубы так сказать практически нельзя. И то, что тренеров не уходящих радикально от своих принципов игры мы видим намного чаще, чем клубы меняющие тренеров, но остающиеся в рамках одной философии (так, навскидку, разве что Аякс приходит в голову, и под очень большим вопросом Барселона), говорит о том, что, возможно, определенные менеджеры раскрывают игроков стабильнее, чем клубы. Хотя тут я бы не стал сильно держаться за свое утверждение.
Из чисто статистических показателей выше всего оказывается просто количество времени которое провел игрок на поле в прошлом году в своем основном соревновании (stats_minutes_0). Это-то, как раз, вполне логично, потому что то, насколько данный игрок был 'основным' в своем клубе в прошлом сезоне — кажется более универсальным статистическим показателем его успешности, чем другие — например, количество забитых голов или полученных карточек.
Популярность игрока (pop_log1p) замыкает эту группу из 8-ми самых важных параметров. Тут стоит вспомнить, что данные у нас представлены за последние 10 лет. Думаю, важность этого поля была бы выше, если бы мы рассматривали последние лет 5, а для среднего значения за последнее десятилетие это вполне объяснимый результат, тем более если учитывать отрыв от следующего места.
Ну и последнее на что бы хотелось бы обратить внимание — это важность поля агент (plr_player_agent). Оставлю это без комментариев, ибо если в спорах о (не)нужности агентов еще и можно сломать поля копий, то в степени их влияния на современный трансферный рынок сомневаться не приходится (хотя модель и предлагает ее не переоценивать).

Кстати, самое, может быть, интересное в этом методе анализа — его доступность: необязательно делать 'идеальную' модель, чтобы получать информацию о важности параметров. Во многих случаях бывает достаточно, чтобы она просто худо-бедно предсказывала, статистически значимо отличалась от подбрасывания монетки, и вы уже получите результаты, которые, зачастую, содержат в себе интересные инсайты или подскажут с какой новой стороны можно посмотреть на данные.
Засим пора закругляться, чтобы более не увеличивать итак перегруженный текст. На прощание хотелось бы еще раз призвать всех интересующихся темой опробовать (лучший, на мой взгляд, для новичков) курс по Deep Learning — fast.ai и применить полученные знания в 'вашей области экспертизы', вполне вероятно вы будете там первым :)
А если вам понравится, то я попробую осилить вторую часть текста о моих экспериментах в которых модель с помощью не менее мощного инструмента — Partial Dependency подскажет: клиентом какого агентства лучше всего становиться футболисту, какие клубы ведут наиболее эффективную трансферную политику, какой тренер лучше всего увеличивает стоимость игроков (кроме очевидных кандидатов есть много не особенно раскрученных 'брендов' к которым явно стоит присмотреться повнимательнее) и многое другое.
Habrahabr.ru прочитано 9948 раз
