
Система «Федерация». Часть 7/8 Двухфазная оценка систем
В концепции системы Федерация (часть 2) было показано , что оценка должна быть двух фазной, но перед рассмотрением полной схемы двухфазной оценки я бы хотел «подсветить» еще один важный момент, который нужно обязательно учесть: оценка будет вестись группой экспертов и тут опять возникает две противоположных проблемы:
Унификация: все эксперты имеют свое понимание о «прекрасном», но научный подход (простите вырвалось) требует того, чтобы результат не зависел от экспериментатора, т.е. оценка должна быть объективной, насколько это возможно. Требуются общие «правила игры» для обеспечения максимальной объективности, опять же, насколько это возможно среди живых людей
«РазноМнения»: унификация необходима, но недостаточна для объективности, нужна возможность использовать мнения нескольких экспертов, если есть такая возможность. В таких случаях могут возникнуть дискуссии и можно решать такие споры на ринге, за карточным столом или в перетягивании каната, но все же нужен механизм суперпозиции (ой! опять вырвалось) оценок различных экспертов
Итак, теперь полная постановка задачи двухфазной оценки систем:
оценить решение задач потенциального заказчика в конкретной системе
обеспечить «унификацию»/разноМнение при общей оценке системы
«приземлить» оценку на конкретную организацию
Так выглядит постановка задачи к проектированию процесса проведения оценки ИТ-продуктов в системе «Федерация». Прошу прощения, профДеформация — сначала требования, потом архитектура.

Общая схема решения поставленной выше задачи выглядит так:
по каждому критерию эксперт анализирует оцениваемую систему в разрезе определенного критерия
результатом такого анализа должно быть заключение — есть ли какие-то риски в решении задачи в рамках данной системы?
оценка риска проводится по следующей шкале от 100 до 0 баллов :
Согласовано: задача решена хорошо, рисков нет (или точнее не вижу, но об этом чуть ниже)
Согласовано с замечаниями: есть замечания по реализации (например, масштабирование есть, но требуется время на переключение — RTO или используется СУБД Oracle и есть риски ИТ-суверенитета). Одним словом, задачу можно решить, но с некоторым «подВыподВертом»
Энергично не согласовано: задача не решена. Может наметки решения задачи и есть, но выполнить данную задачу, если придется, штатными средствами системы не удастся. Ну хоть подумал — тут за «намерения» 10 баллов из 100 .
Таким образом, получается унифицированная оценка системы вообще. Пока нет четкого понимания, где продукт будет применяться, но определенные особенности, или риски, проанализированы специалистами в этой области и их оценка доступна для использования. По сути определена область применения системы по мнению независимых экспертов.
Рассмотрим на примере:
система обладает расширенными автоматического масштабирования
использует «неСуверенную» СУБД Oracle
имеет основным языком пользовательского интерфейса и системных сообщений — великий и могучий.
обеспечивает определенную степень защиты информации
Зафиксируем результат первой фазы «Централизованная оценка».
Решение попало нам в каталог групповых решений и пусть лежит.
Трем организациям, финКомпании (скажем лизинг), среднему и неБольшому заграничному Банку) Gруппы, занадобилось решение в какой-то функциональной области, или как у нас ее любовно зовут — «плашка». Пусть CRM, операционный CRM.
Очевидно, что проведенная централизованная оценка не может быть перенесена на рассматриваемые дочки «как есть». Как было показано выше, нужна локализация централизованной оценки (приземление). Т.е. нам нужно иметь возможность оценить важность каждой оценки, или ее вес, для конкретной организации. По сути применить профиль или фильтр, который может быть наложена от каждой организации, для учета ее специфики.
Матрица, учитывающая специфику конкретной организации (локализация) включает в себя следующие аспекты:
Требуемый ИТ-суверенитет: допустим, организации в юрисдикции РФ — должны «импортозаместиться», в обязательном порядке (требования регулятора на минуточку), в свою очередь зарубежные дочки имеют более мягкие условия. Прямого запрета на использование СУБД Oracle в Брунее нет пока, но могут «прилететь» вторичные санкции — и сам себе злобный Буратино. Не обязан, но тебя предупреждали и ответственность на «дочке», которая переходит в статус «infant Terrible».
Весовая категория: размер имеет значение. Что нужно среднему банку, не обязательно, а то и вредно, малому. Линейное масштабирование штука дорогая как в эксплуатации, так и в инфраструктуре. Зачем это неБольшому банку? Шипованная резина в комплекте — замечательно, но в Брунее не поймут такую «опцию».
Требования безопасности: опять в разных организациях разные требования, у ним разные регуляторы
Таким образом, продукт должен быть действительно гибким, причем не абстрактно, а вполне конкретно — как в рамках общих стандартов (централизация), так и в рамках специфики «дочек». Эту тему мы смотрели в рамках «Шапки архитектора» — см. часть 3. Шапка архитектора.
Весовая шкала каждого локального критерия: «применимо», «неприменимо» и «частично применимо». Локальные коэффициенты, применяемые к оценке «централизованного» эксперта 1, 0 и 0.5.
Теперь, посмотрим каждую фазу поглубже и в конце рассмотрим конкретный пример. Все будет хорошо.

Основные принципы понятны, теперь, как организовать оценку с учетом задач «Унификации» и «РазноМнения» и независимости от личности эксперта (ну минимальной зависимости)?
Логика анализа должна быть единой: Никаких не подтверждённых фактами утверждений. «У меня складывается впечатление, что до Луны семь килОметров, может быть восемь. Ну молодец, это »5» — обоснуй!
Эксперт должен проводит анализ по следующей формуле:
вижу факт: — язык пользовательского интерфейса и системных сообщений русский и не может быть переведен на другой.
следствие: Из этого эксперт, делает вывод об эксплуатации данной системы
не вызывает никакой проблемы в компаниях Gруппы на территории РФ
может вызвать проблемы в Грузии, Армении и Азербайджане и т.д.,
точно будут проблемы в Китае и Иране
в Индии проблем не будет — там русскоязычный персонал
Аналогично, с надежностью — есть средства обеспечения отказоустойчивости (standIn или что-то подобное), но они слишком «тяжелы» для небольших организаций.
Таким образом, причинно-следственные связи будут нормированы (за этим модератор присмотрит), а что делать, если два эксперта из одного факта выводят разные следствия? Может кто-то что-то просто просмотрел или в принципе различное понимание. На кефире или на квасе, метаданные или сборка на интерфейсах и т.д? По моей любимой теореме Гёделя — даже если две цепочки рассуждения построены на безупречной формальной логике, но в основе различные аксиомы (заповеди), стыковать или дискутировать вверху «цепочек рассуждений» (если изобразить позиции каждого из в виде дерева), бессмысленно — корень, предпосылки разные. Что делаем: боксерский ринг, монетка, шахматно-шашечный турнир?

Мы исходим из того, что наши эксперты неглупые люди: если Беня, что-то говорит за масштабирование, его нужно послушать, он в этом специалист.
Точно нужно фиксировать все мнения специалистов, но как с ними работать? Ответ универсальный — нормировать.
На уровне схемы:
Эксперт 1 дает оценку, по определенному критерию критериальной модели — фиксируем
Согласен: Потом эксперт 2 дает оценку, аналогичную оценке эксперта 1. Т.е. соглашается с его мнением. Зачем нам куча разных вариантов, одного и того же? Если согласен с оценкой, «нажми +».
Согласен частично: Эксперт 3, в принципе согласен с оценкой первых двух, но замечает еще важный факт и его следствие. Разделяем его оценку на две части — общую (+ к существующей оценке) и даем ему зафиксировать свое собственное особое мнение.
Дальнейшие сценарии будет лишь комбинации описанных выше. Особое мнение тоже можно плюсовать, и оно станет еще одной общей оценкой.
Оценки всех экспертов оцениваются в разрезе рисков централизованной оценки см. рис 1 и получаем общую централизованную оценку:
100 — 60 баллов: рисков нет или они гипотетические
60–30 баллов: есть не существенные риски
30–0 баллов: риски есть и существенные
Каждое снижение должно быть обосновано и проверено модератором на «обоснованность».

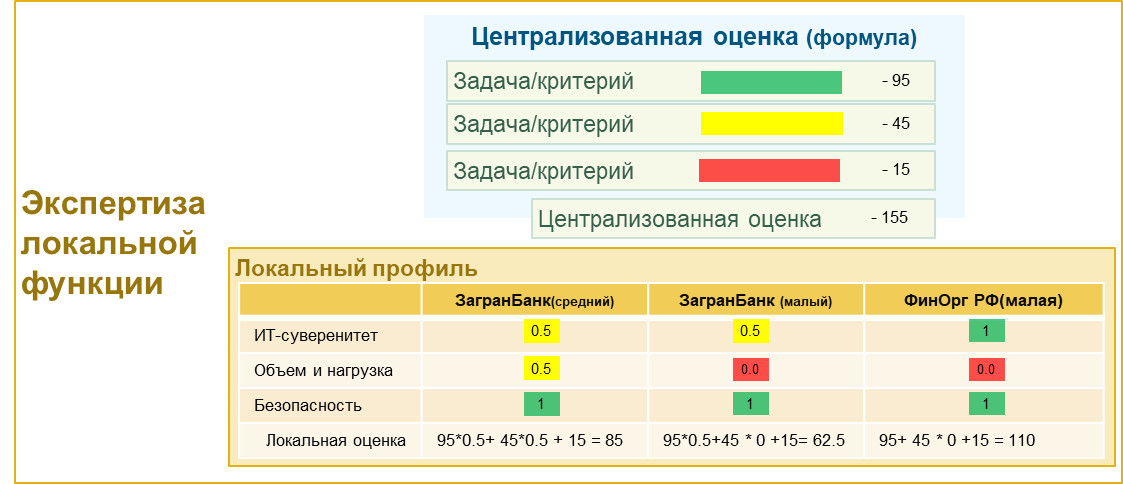
В итоге получаем сумму оценок системы одним или несколькими экспертов по всем критериям. Например, как показано на рис 4. Общая оценка 155 баллов.

Переходим к фазе 2, приземляем централизованную оценку на конкретную организацию.
К каждому критерию оценки нужно применить локальный профиль — «развесовку» критериев для конкретной организации:
Применимо (учитываем полностью) : 1.0
Применимо частично (учитываем частично) : 0.5
Не применимо (обнуляем критерий) : 0.0
Например, по трем критериям имеем следующие централизованные оценки: 95, 45 и 15 баллов соответственно (рис. 4). Общая централизованная оценка по этим критериям 155 баллов. Принято.

Имеем, три локальных профиля для крупного и неБольшого заграничного банков, и для неБольшой финансовой организации, например, лизинг.
ИТ-суверенитет: Для загранБанков, как было показано выше, требования российского регулятора в части импортозамещения, не столь критичны, но ИТ-суверенитет — важен и для них. Поэтому
1 балл для финОрганизации
0.5 для загранБанков
Объем и нагрузка: критерии обеспечения производительности (линейное масштабирование)
для малых организаций вообще не существенны — 0
для средней организации — важны, но не столь существенны ставим 0.5
для большой будет 1.0
Безопасность: тут, чтобы не усложнять очевидную цепочку рассуждения. Пусть задачи ребят из ИБ не обсуждаются.
Все — 1
В итоге, из 155 баллов централизованной оценки в локальные «зачет» двух банков и одной финОрганизации пойдет 85, 62.5 и 110 баллов соответственно.
Такая архитектура двухфазной оценки по критериальной модели заложена в систему «Федерация». По-моему, справедливо и объективно, насколько это может быть возможным.
Теперь осталось посмотреть на финальный элемент «Федерации» — каталог продуктов.
Habrahabr.ru прочитано 7535 раз
