
[Перевод] Я изучила 900 самых популярных инструментов ИИ на базе open source — и вот что обнаружила

Четыре года назад ИТ-эксперт Чип Хуэн* проанализировала экосистему ML с открытым исходным кодом. С тех пор многое изменилось, и она вернулась к изучению темы, на этот раз сосредоточившись исключительно на стеке вокруг базовых моделей.
О результатах нового исследования читайте под катом.
*Обращаем ваше внимание, что позиция автора может не всегда совпадать с мнением МойОфис.
Данные
Я искала на GitHub по ключевым словам gpt, llm и generative ai. Результаты поиска подтвердили огромную популярность ИИ: только по одному слову gpt я получила 118 тысяч результатов.
Чтобы облегчить себе жизнь, я ограничила поиск репозиториями с не менее чем 500 звездами. Для llm было найдено 590 результатов, для gpt — 531, а для generative ai — 38. Кроме того, я периодически проверяла тренды GitHub и социальные сети на предмет появления новых репозиториев.
После долгих часов работы я нашла 896 репозиториев. Из них 51 — это руководства (например, dair-ai/Prompt-Engineering-Guide) и агрегированные списки (например, f/awesome-chatgpt-prompts). Эти материалы полезны и я включила их в итоговый перечень, но больше меня интересует программное обеспечение: анализ проводился по 845 программным репозиториям.
Это был болезненный, но полезный процесс. Благодаря ему я стала гораздо лучше понимать, над чем работают люди, насколько удивительно сотрудничество разработчиков открытого кода и насколько сильно китайская экосистема open source отличается от западной.
Полный список репозиториев ИИ с открытым исходным кодом размещен на сайте llama-police; список обновляется каждые шесть часов. Большинство из них вы также можете найти в моём списке cool-llm-repos на GitHub.
Добавьте недостающие репозитории!
Несомненно, я пропустила множество репозиториев. Вы можете добавить свои варианты здесь. Список будет автоматически обновляться каждый день.
Не стесняйтесь присылать репозитории с менее чем 500 звёздами. Я буду отслеживать их и добавлю в список, когда они достигнут 500 звезд!
Новый стек ИИ
Я считаю, что стек ИИ состоит из 4 уровней: инфраструктура, разработка моделей, разработка приложений и приложения.
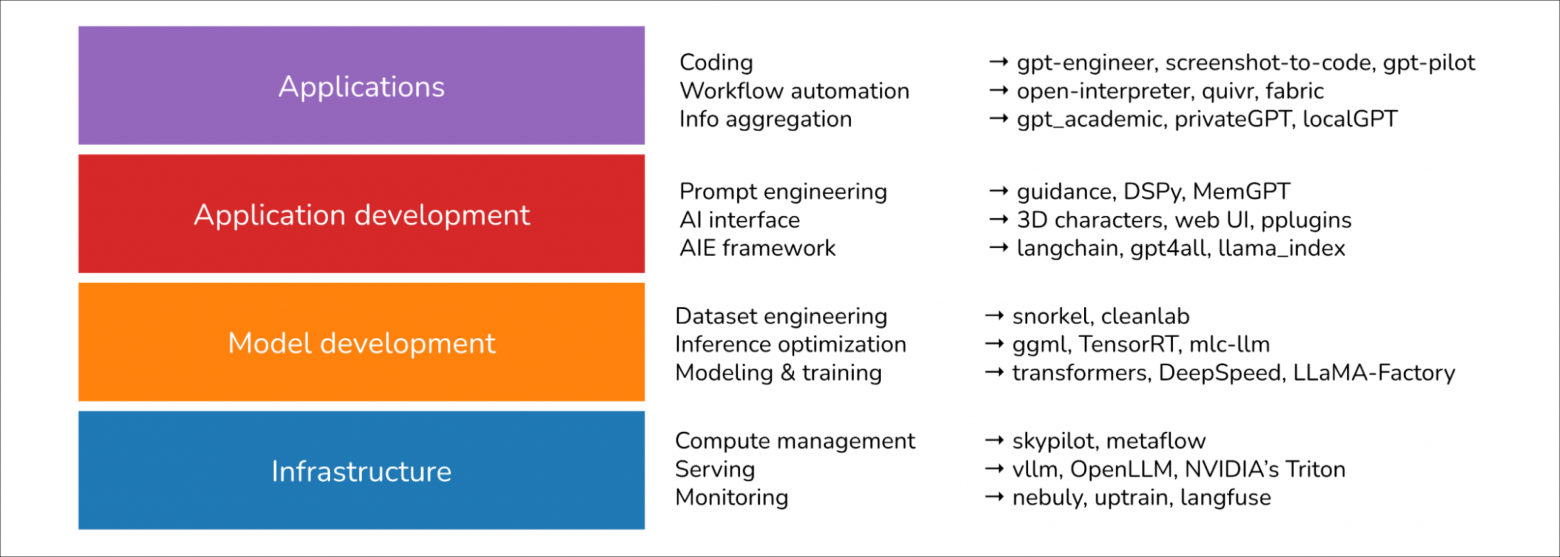
Инфраструктура
В нижней части стека находится инфраструктура, включающая инструменты для обслуживания (vllm, NVIDIA’s Triton), управления вычислениями (skypilot), векторного поиска и баз данных (faiss, milvus, qdrant, lancedb), …
Разработка моделей
Этот уровень включает инструменты для разработки моделей, в том числе фреймворки для моделирования и обучения (transformers, pytorch, DeepSpeed), оптимизации инференса (ggml, openai/triton), инжиниринга данных, оценки, … Все, что связано с изменением весов модели, включая тонкую настройку, происходит на этом уровне.
Разработка приложений
Имея доступные модели, каждый может разрабатывать на их основе приложения. Именно на этом уровне за последние два года произошло больше всего событий, и он продолжает стремительно развиваться. Этот уровень также известен как ИИ-инжиниринг.
Разработка приложений включает в себя промпт-инжиниринг, RAG, ИИ-интерфейсы, …
Приложения
Существует множество приложений с открытым исходным кодом, построенных на основе существующих моделей. Наиболее популярные типы приложений — для кодирования, автоматизации рабочих процессов, агрегации информации…
Помимо упомянутых четырёх слоев я также выделяю еще одну категорию — репозитории моделей, которые создаются компаниями и исследователями для обмена кодом, связанным с их моделями. Примеры репо в этой категории — CompVis/stable-diffusion, openai/whisper и facebookresearch/llama.
Стек ИИ с течением времени
Я подсчитала совокупное количество репозиториев в каждой категории с разбивкой по месяцам. В 2023 году, после внедрения Stable Diffusion и ChatGPT, начался бум новых репозиториев. Кривая выглядит плоской в сентябре 2023 года по трём возможным причинам.
Я включила в анализ только репозитории с не менее чем 500 звёздами, а репозиториям требуется время для получения такого количества звезд.
Большинство «низко висящих фруктов» уже собрано. Остались наиболее трудоёмкие варианты, в которых заинтересованы немногие.
Люди поняли, что в области генеративного ИИ трудно быть конкурентоспособным, поэтому ажиотаж поутих. В начале 2023 года все мои разговоры с компаниями об ИИ были посвящены генеративному ИИ, но последние разговоры стали более приземлёнными. Некоторые даже упоминали scikit-learn. Я планирую вернуться к этому вопросу через несколько месяцев, чтобы детальнее понять ситуацию.
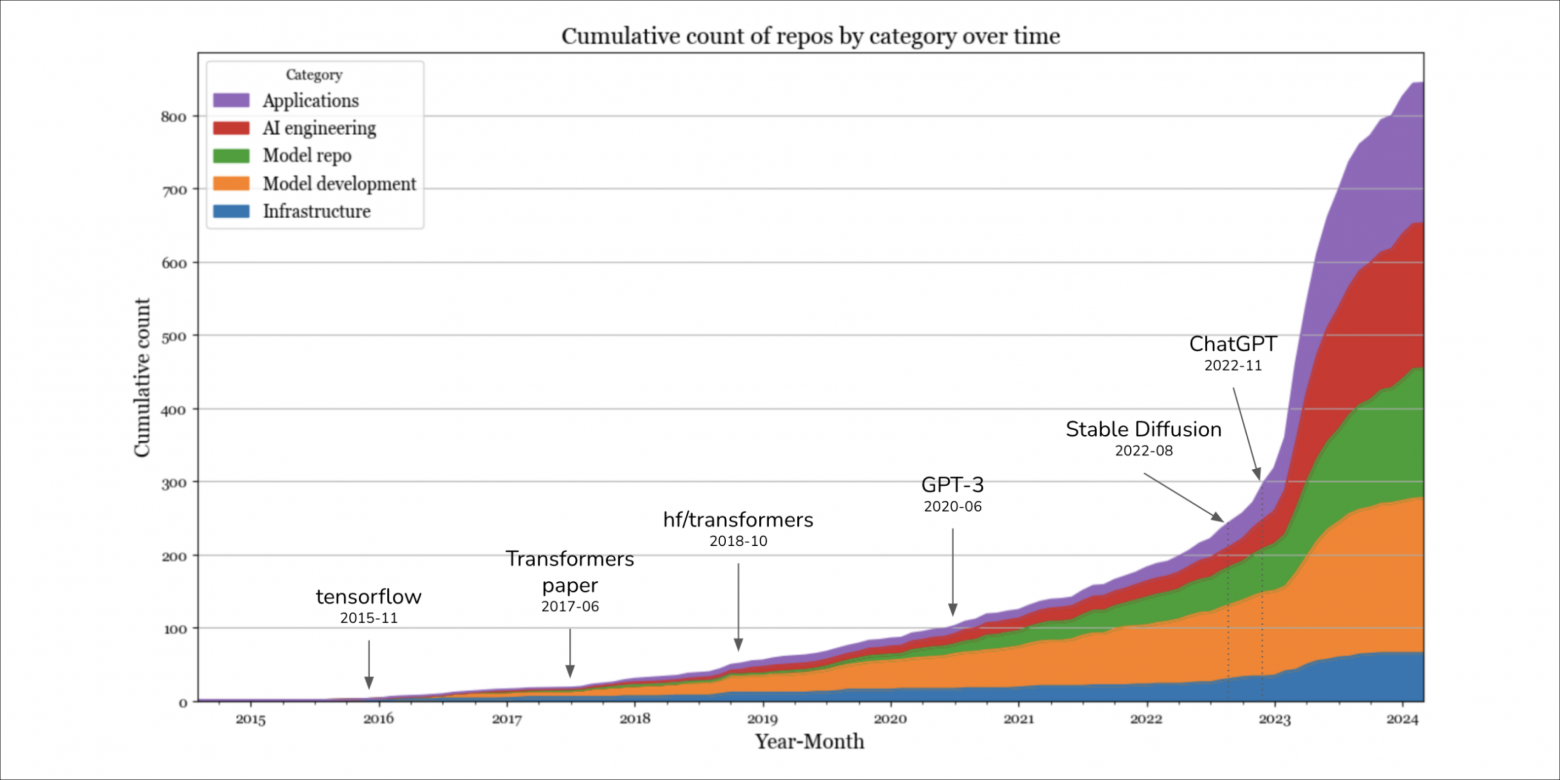
В 2023 году наибольший рост наблюдался на уровнях приложений и разработки приложений. Небольшой рост на инфраструктурном уровне был далек от уровня роста, наблюдавшегося на других уровнях.
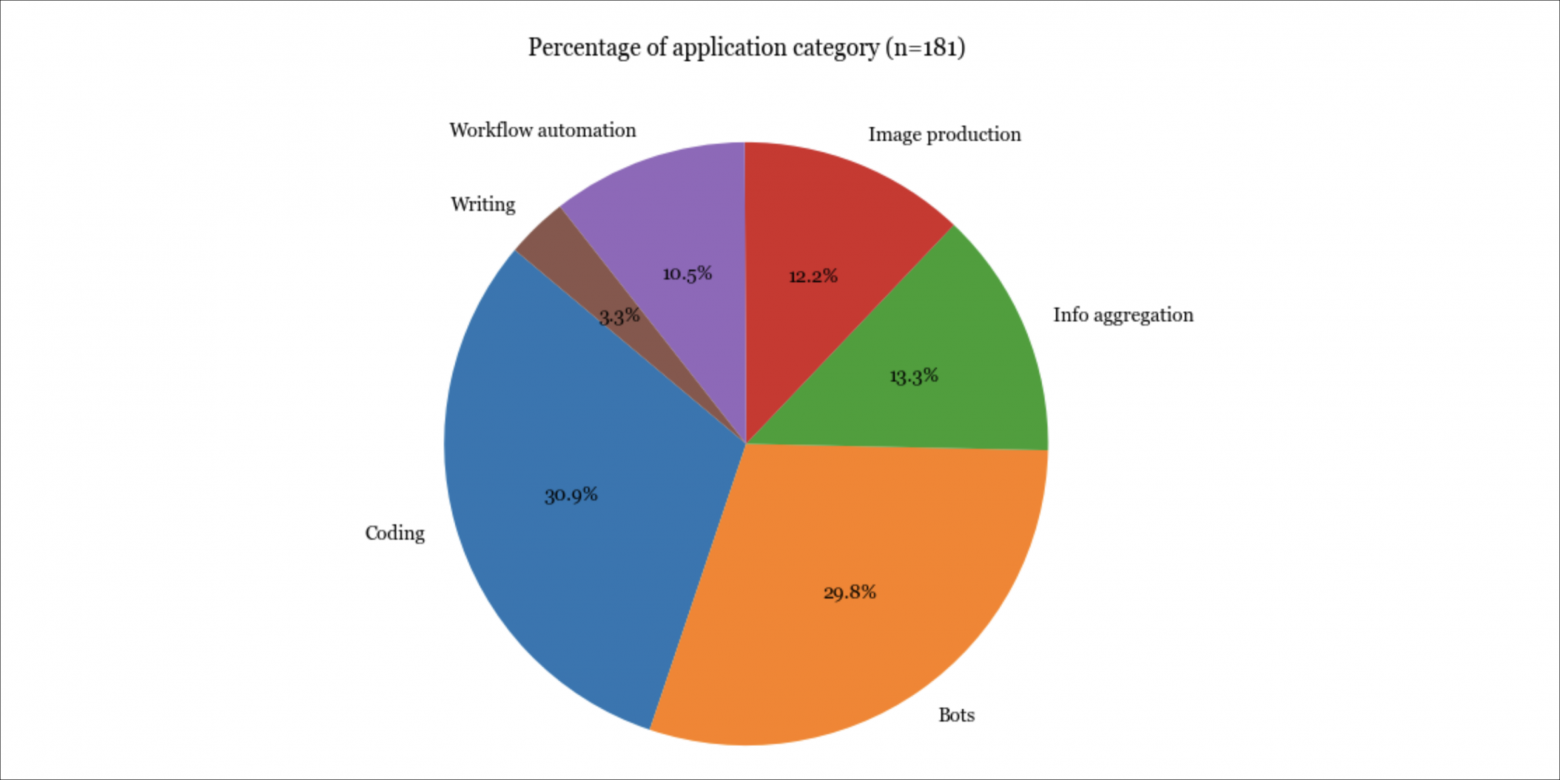
Приложения
Неудивительно, что самыми популярными являются приложения для кодинга, боты (например, ролевые игры, боты WhatsApp, боты Slack) и агрегаторы информации (в духе «подключим это к нашему Slack, чтобы суммировать сообщения за день»).
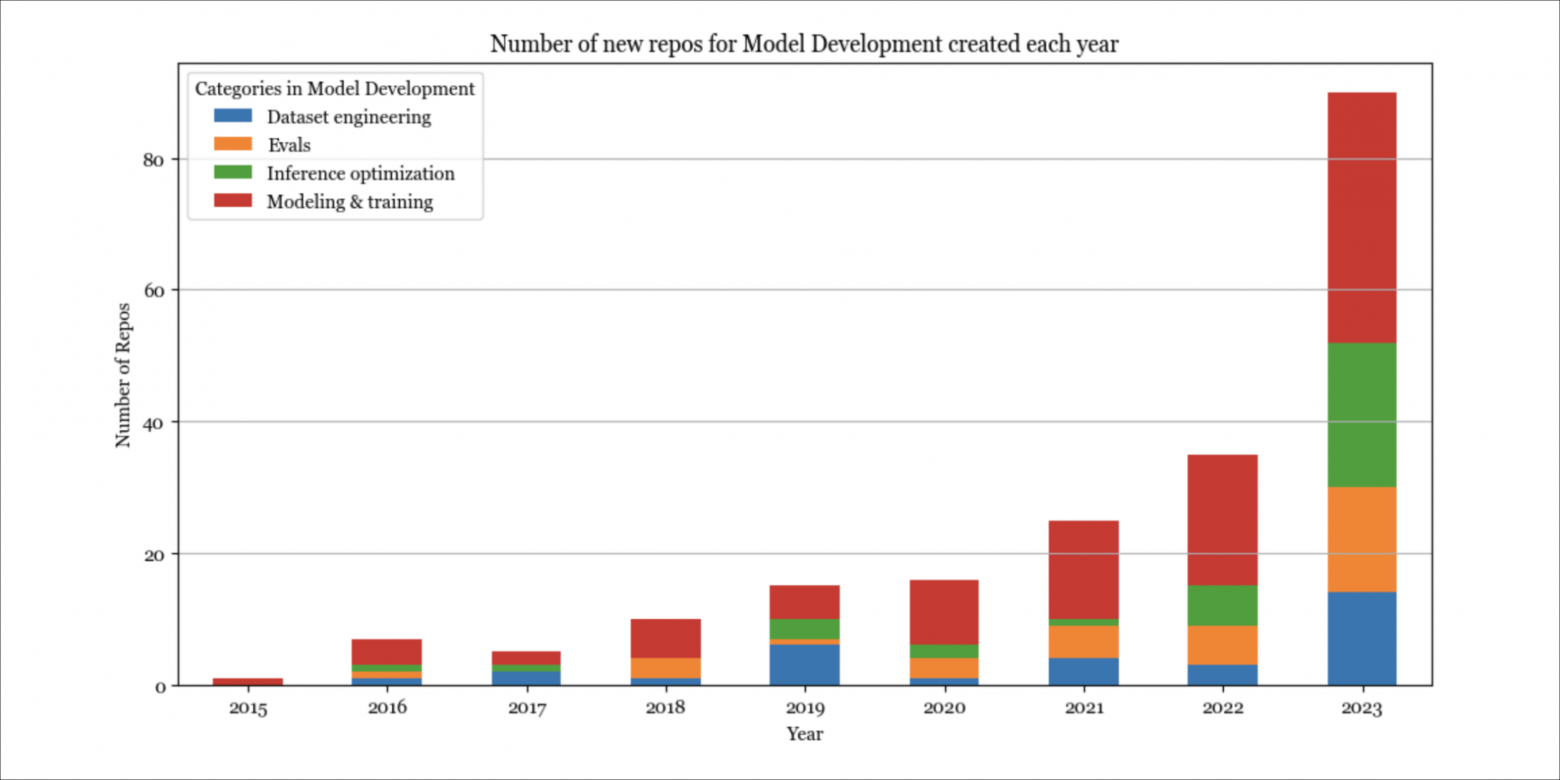
ИИ-инжиниринг
2023 год стал годом ИИ-инжинринга. Поскольку многие из инструментов этого направления похожи, их сложно классифицировать. В настоящее время я разделяю их на следующие категории: промпт-инжиниринг, ИИ-интерфейс, агент и фреймворк ИИ-инжиниринга (AIE).
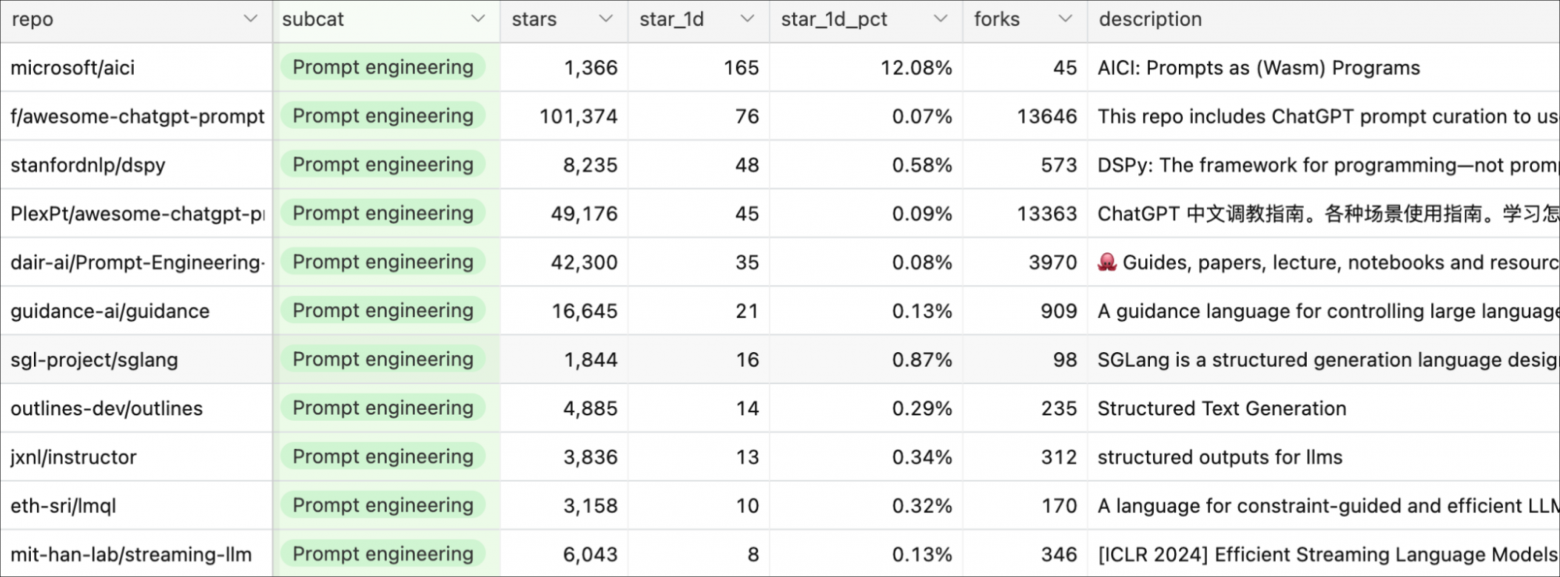
Промпт-инжиниринг выходит далеко за рамки работы с промптами и охватывает такие вещи, как ограниченная выборка (структурированный вывод), управление долговременной памятью, тестирование и оценка промптов и т. д.
Интерфейс ИИ обеспечивает взаимодействие конечных пользователей с вашим приложением ИИ. Эта категория вызывает у меня наибольший интерес. Среди интерфейсов, которые набирают популярность, можно выделить следующие:
Веб- и десктоп-приложения.
Расширения для браузеров, позволяющие пользователям быстро запрашивать модели ИИ во время просмотра веб-страниц.
Боты чат-приложений, таких как Slack, Discord, WeChat и WhatsApp.
Плагины, позволяющие разработчикам встраивать решения ИИ в такие приложения, как VSCode, Shopify и Microsoft Offices. Подход с использованием плагинов характерен для ИИ-приложений, которые могут использовать инструменты для выполнения сложных задач (агенты).
Фреймворк ИИ-инжиниринга — это общий термин для всех платформ, которые помогают разрабатывать приложения ИИ. Многие из них построены на основе RAG, но зачастую они также предоставляют другие инструменты, такие как мониторинг, оценка и т. д.
Агент — странная категория, поскольку многие её инструменты представляют собой лишь усложненную разработку промптов с потенциально ограниченным генерированием (например, модель может выводить только предопределённые действия) и интеграцией плагинов (например, чтобы позволить агенту использовать инструменты).
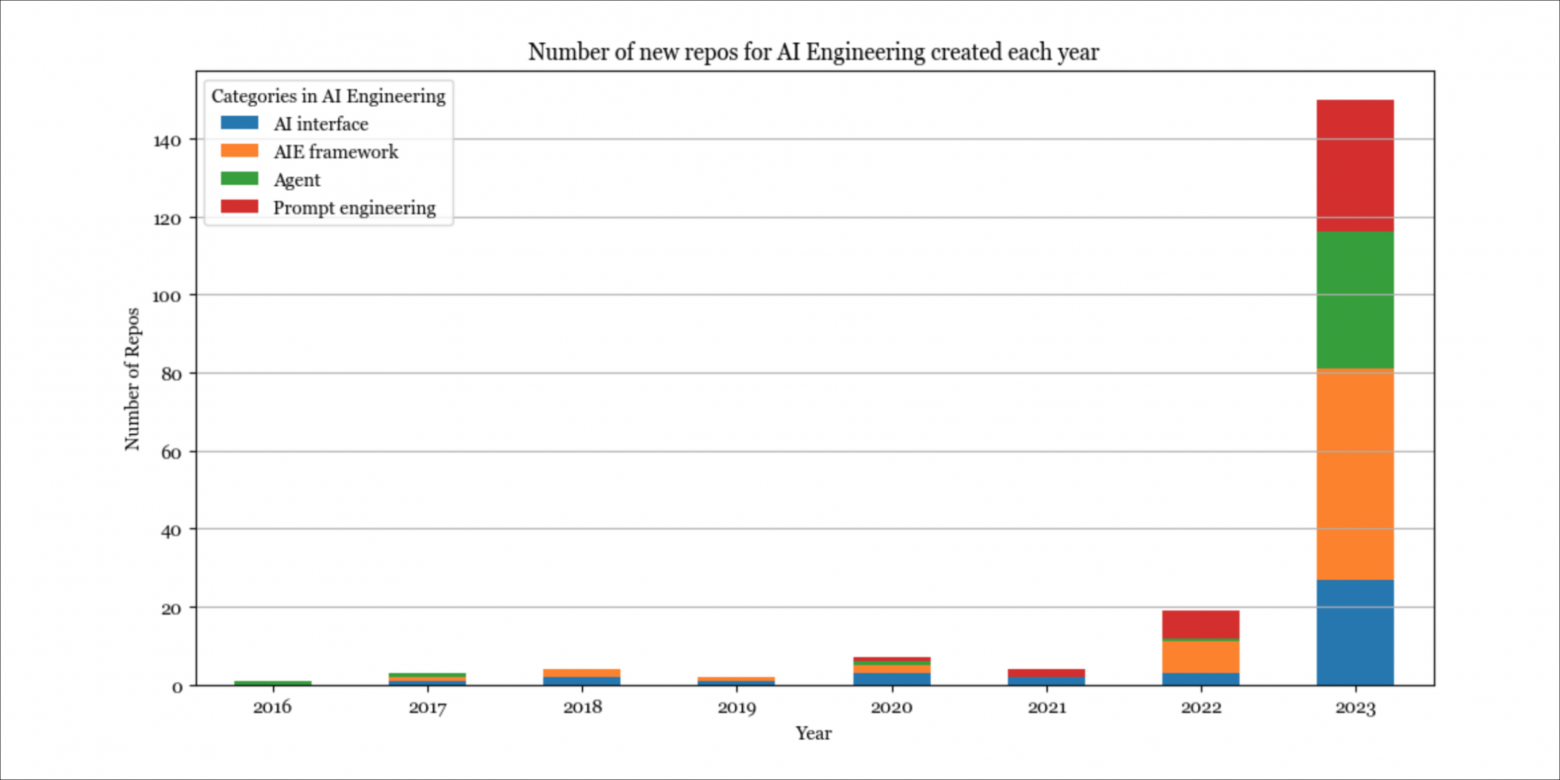
Разработка моделей
До появления ChatGPT в стеке ИИ доминировала разработка моделей. Взрыв этого направления в 2023 году был обусловлен растущим интересом к оптимизации инференса, оценке и тонкой настройке параметров (что относится к »Моделированию и обучению»).
Оптимизация инференса всегда была важна, но сегодня масштаб базовых моделей делает ее решающей с точки зрения задержки и стоимости. Основные подходы к оптимизации остаются прежними (квантование, факторизация с низким рангом, прунинг, дистилляция), но было разработано множество новых методов специально для трансформер-архитектуры и нового поколения аппаратных средств. Например, в 2020 году 16-битное квантование считалось передовым. Сегодня мы видим 2-битное квантование и даже меньше 2-битного.
Аналогично, оценка всегда была важна, но сегодня, когда многие относятся к моделям как к «черным ящикам», её роль укрепилась. Появилось множество новых эталонов и методов оценки, таких как сравнительная оценка (см. Chatbot Arena) и AI-as-a-judge.
Инфраструктура
Инфраструктура — это управление данными, вычислениями и инструментами для обслуживания, мониторинга и прочей работы платформы. Несмотря на все изменения, которые принес генеративный ИИ, инфраструктурный слой ИИ с открытым исходным кодом остался более или менее прежним. Это может быть связано с тем, что инфраструктурные продукты, как правило, не относятся к open source.
Самая новая категория на этом уровне — векторные базы данных от таких компаний, как Qdrant, Pinecone и LanceDB. Однако многие утверждают, что этой категории вообще не должно быть. Векторный поиск существует уже давно. Вместо того чтобы создавать новые базы данных только для векторного поиска, компании, занимающиеся БД, такие как DataStax и Redis, внедряют векторный поиск туда, где уже есть данные.
Разработчики ИИ с открытым исходным кодом
ПО с открытым исходным кодом, как и многое другое, распределяется по принципу «длинного хвоста». Горстка аккаунтов контролирует большую часть репозиториев.
Компании-миллиардеры, состоящие из одного человека?
845 репозиториев размещены на 594 уникальных аккаунтах GitHub. Есть 20 аккаунтов, на которых размещено не менее 4 репозиториев. На этих 20 аккаунтах размещено 195 репозиториев, или 23% всех репозиториев в списке. Эти 195 репозиториев набрали в общей сложности 1 650 000 звёзд.
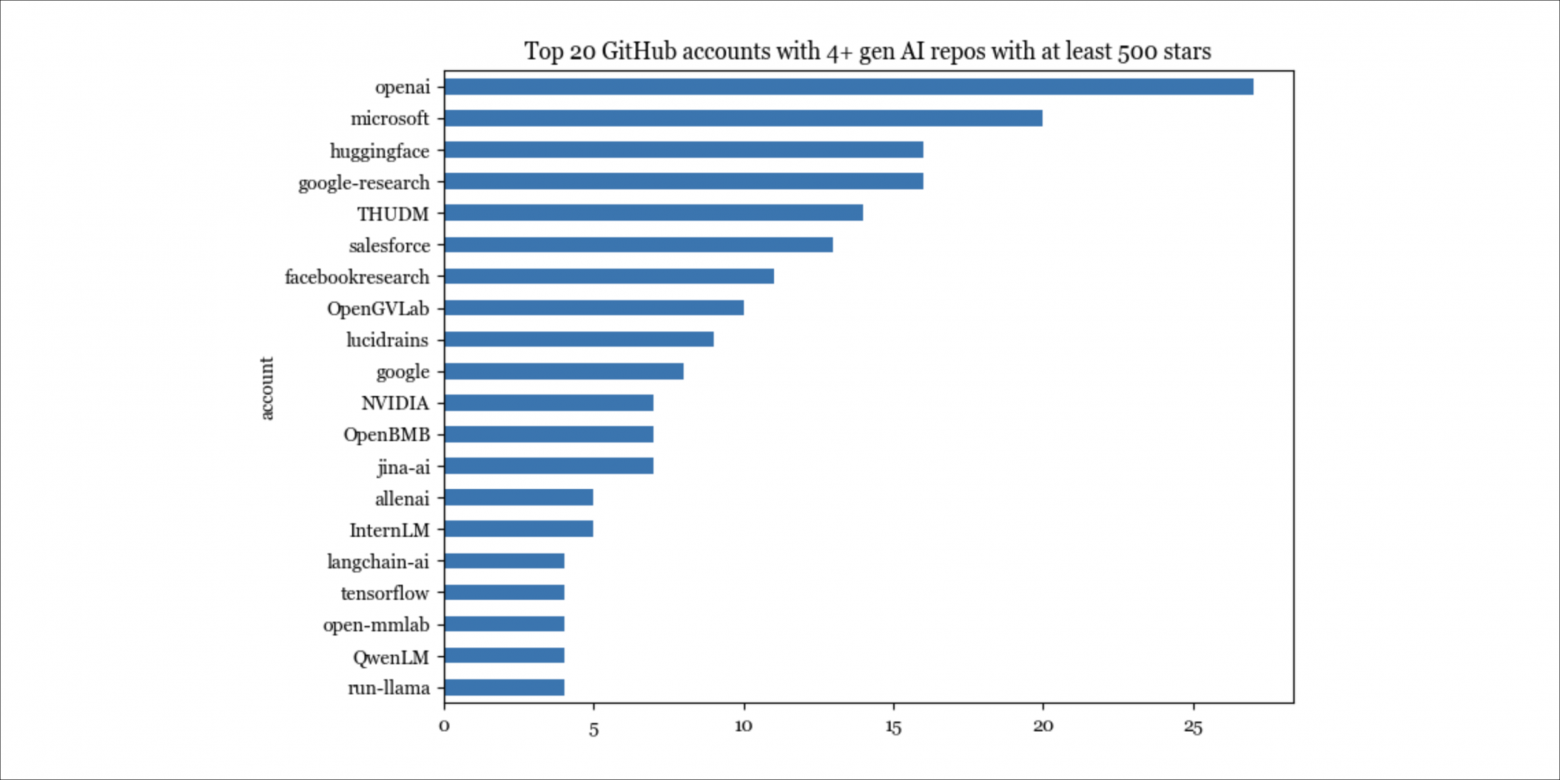
На Github аккаунтом может быть как организация, так и частное лицо. 19/20 ведущих аккаунтов — это организации. Из них 3 принадлежат Google: google-research, google, tensorflow.
Единственный индивидуальный аккаунт среди упомянутых 20 — lucidrains. Среди 20 аккаунтов с наибольшим количеством звёзд (учитываются только репозитории gen AI) есть четыре индивидуальных аккаунта:
lucidrains (Фил Ванг), который умеет внедрять самые современные модели с безумной скоростью.
ggerganov (Георгий Герганов): бог оптимизации, пришедший из физики.
Illyasviel (Люмин Чжан): создатель Foocus и ControlNet, в настоящее время — доктор философии Стэнфорда.
xtekky: full-stack разработчик, создавший gpt4free.
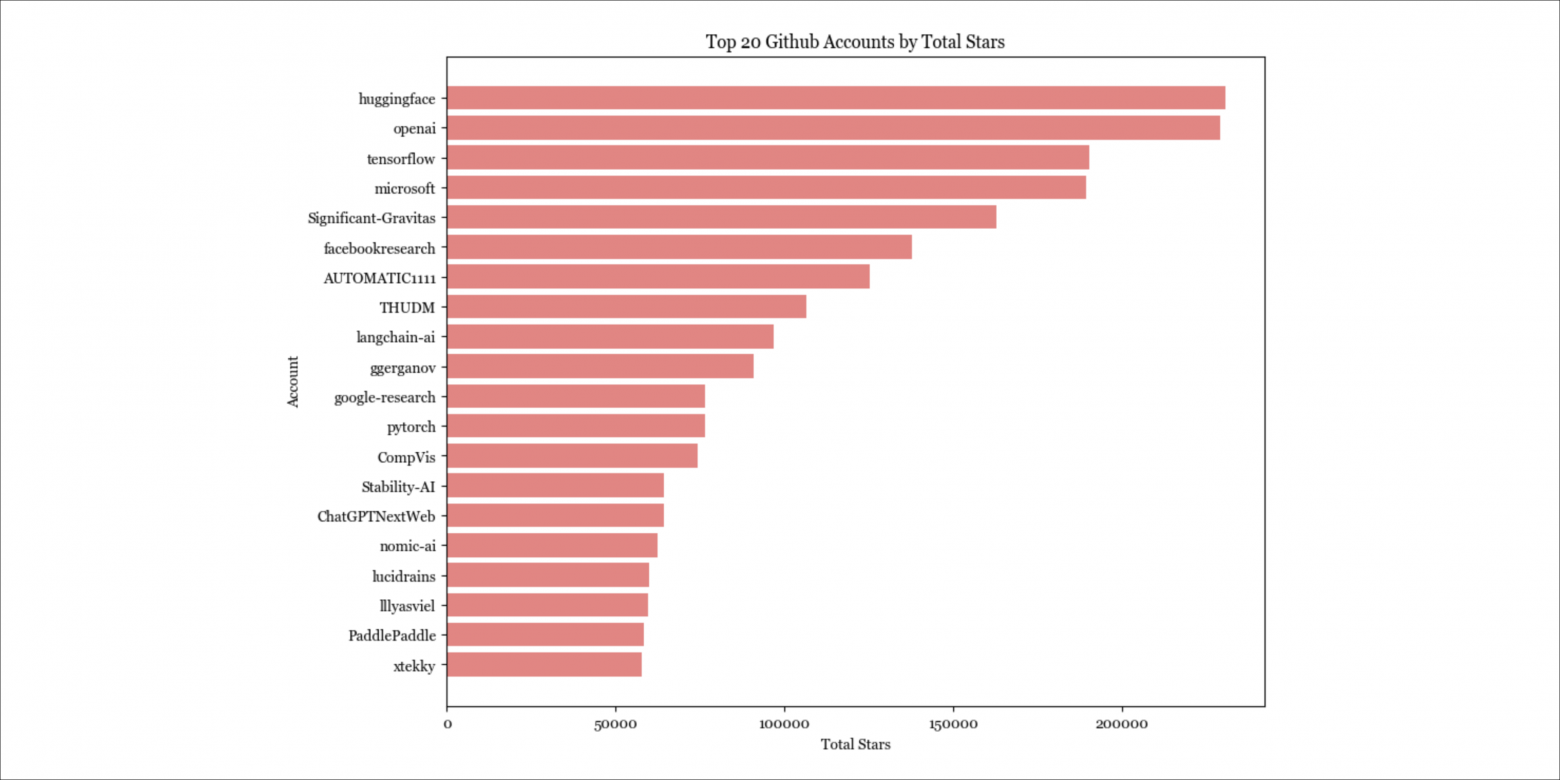
Неудивительно, что чем ниже мы опускаемся в стеке, тем меньше видим приложений от частных лиц. ПО на инфраструктурном уровне реже всего запускается и размещается со стороны частных пользователей, в то время как более половины приложений размещаются на индивидуальных аккаунтах.
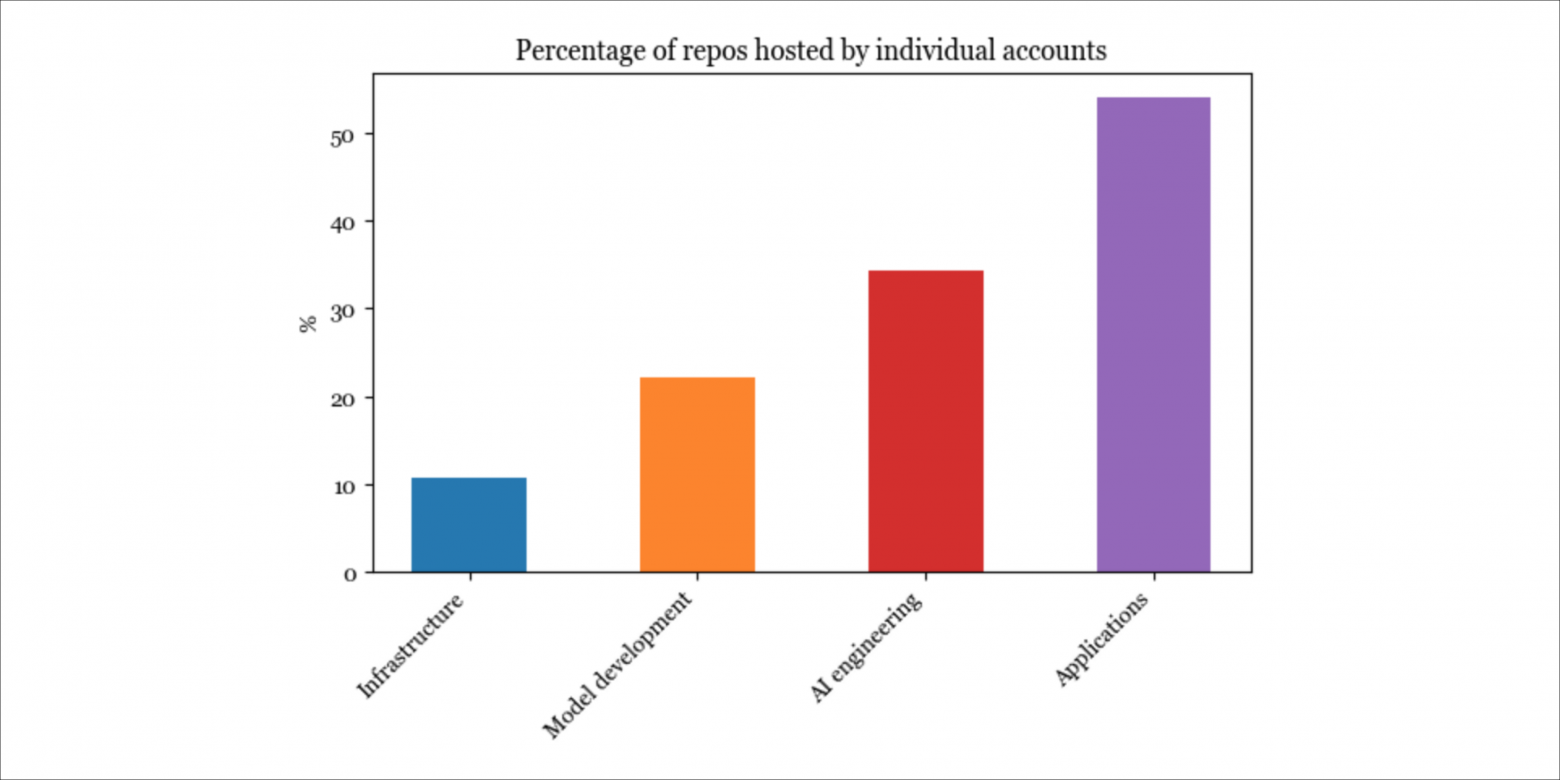
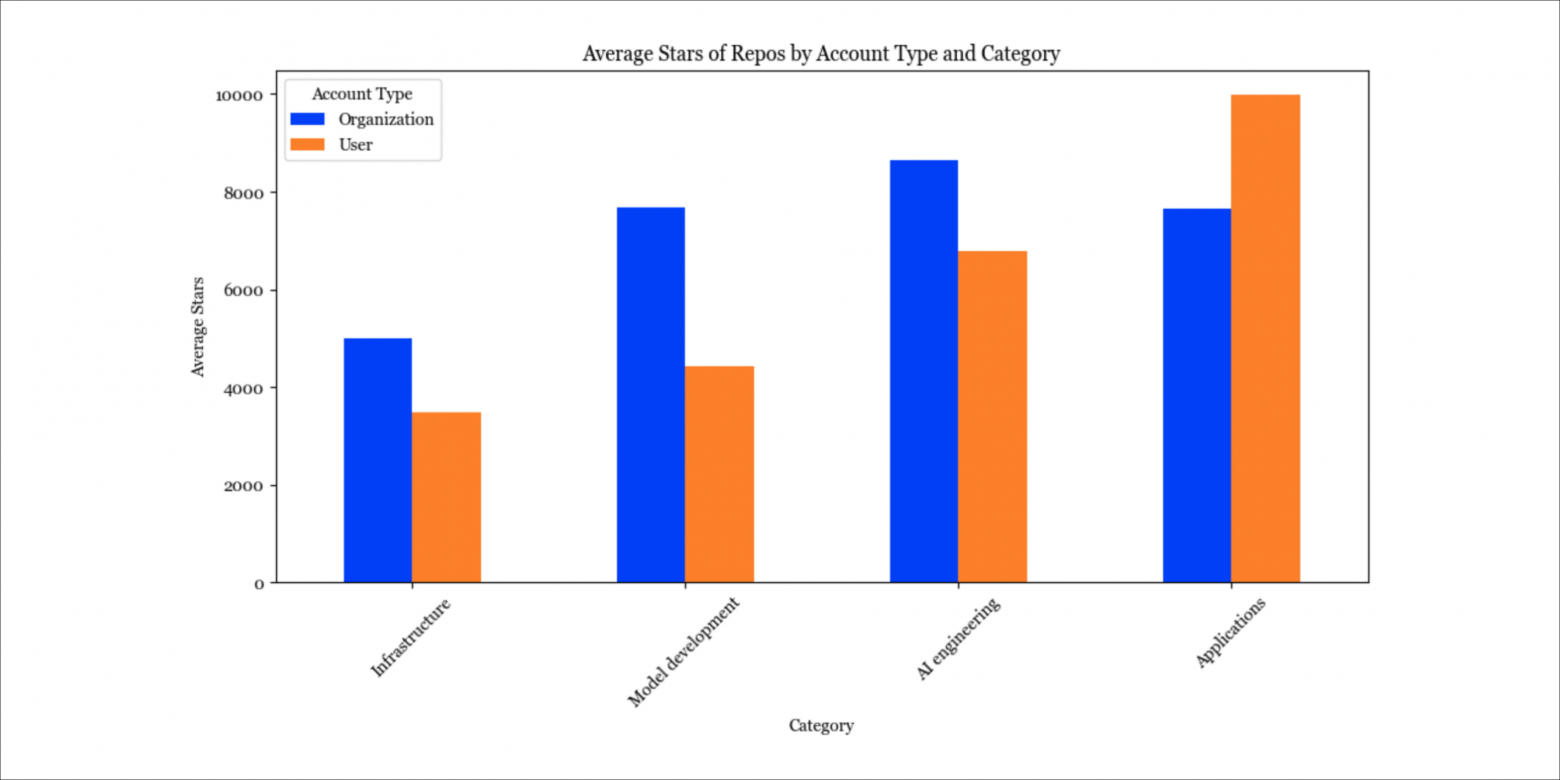
Приложения, созданные частными лицами, в среднем набирают больше звёзд, чем приложения, созданные организациями. Некоторые люди предположили, что мы увидим множество дорогих компаний, состоящих из одного человека (см. интервью Сэма Альтмана и обсуждение на Reddit). Думаю, они могут быть правы.
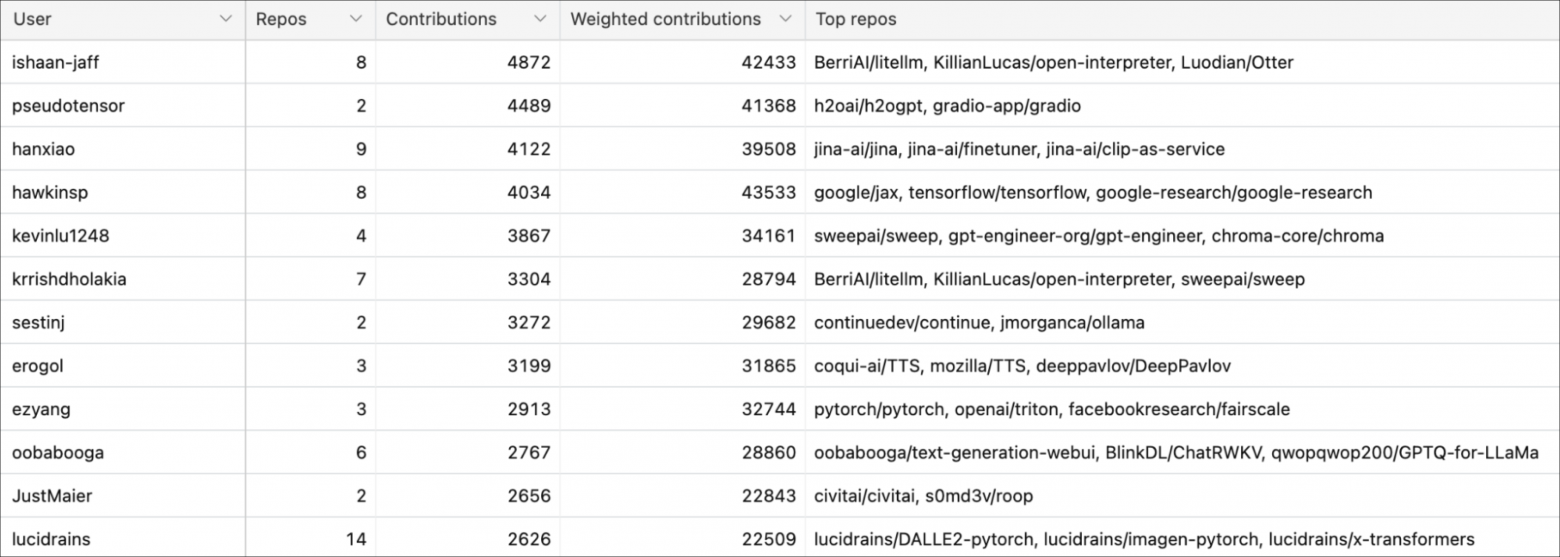
1 миллион коммитов
Более 20 000 разработчиков внесли свой вклад в эти 845 репозиториев. В общей сложности они сделали почти миллион коммитов!
50 самых активных разработчиков сделали более 100 000 коммитов, в среднем более 2 000 коммитов каждый. Полный список 50 самых активных разработчиков открытого кода можно посмотреть здесь.
Растущая китайская экосистема open source
Уже давно известно, что китайская экосистема ИИ отличается от американской (я также упоминала об этом в блоге в 2020 году). Ранее у меня сложилось впечатление, что GitHub не слишком широко используется в Китае, и, возможно, на моё мнение тогда повлияла история с запретом GitHub в Китае в 2013 году.
Теперь я убедилась в обратном. На GitHub есть много, очень много популярных репозиториев ИИ, ориентированных на китайскую аудиторию, — например, их описания написаны на китайском языке. Есть репозитории для моделей, разработанных для китайцев или китайцев + англичан, такие как Qwen, ChatGLM3, Chinese-LLaMA.
Хотя в США многие исследовательские лаборатории отошли от архитектуры RNN для языковых моделей, семейство моделей RWKV на основе RNN по-прежнему популярно.
Существуют также инструменты для разработки ИИ, позволяющие интегрировать модели ИИ в такие распространённые в Китае продукты, как WeChat, QQ, DingTalk и т. д. У многих популярных инструментов промпт-инжиниринга есть зеркала на китайском языке.
Из топ-20 аккаунтов на GitHub, 6 созданы в Китае:
THUDM: Knowledge Engineering Group (KEG) & Data Mining Университета Цинхуа.
OpenGVLab: команда General Vision Шанхайской лаборатории искусственного интеллекта.
OpenBMB: Open Lab for Big Model Base, основанная ModelBest и группой NLP в Университете Цинхуа.
InternLM: от Шанхайской лаборатории искусственного интеллекта.
OpenMMLab: из Китайского университета Гонконга.
QwenLM: ИИ-лаборатория Alibaba, которая публикует семейство моделей Qwen.
Живи быстро, умирай молодым
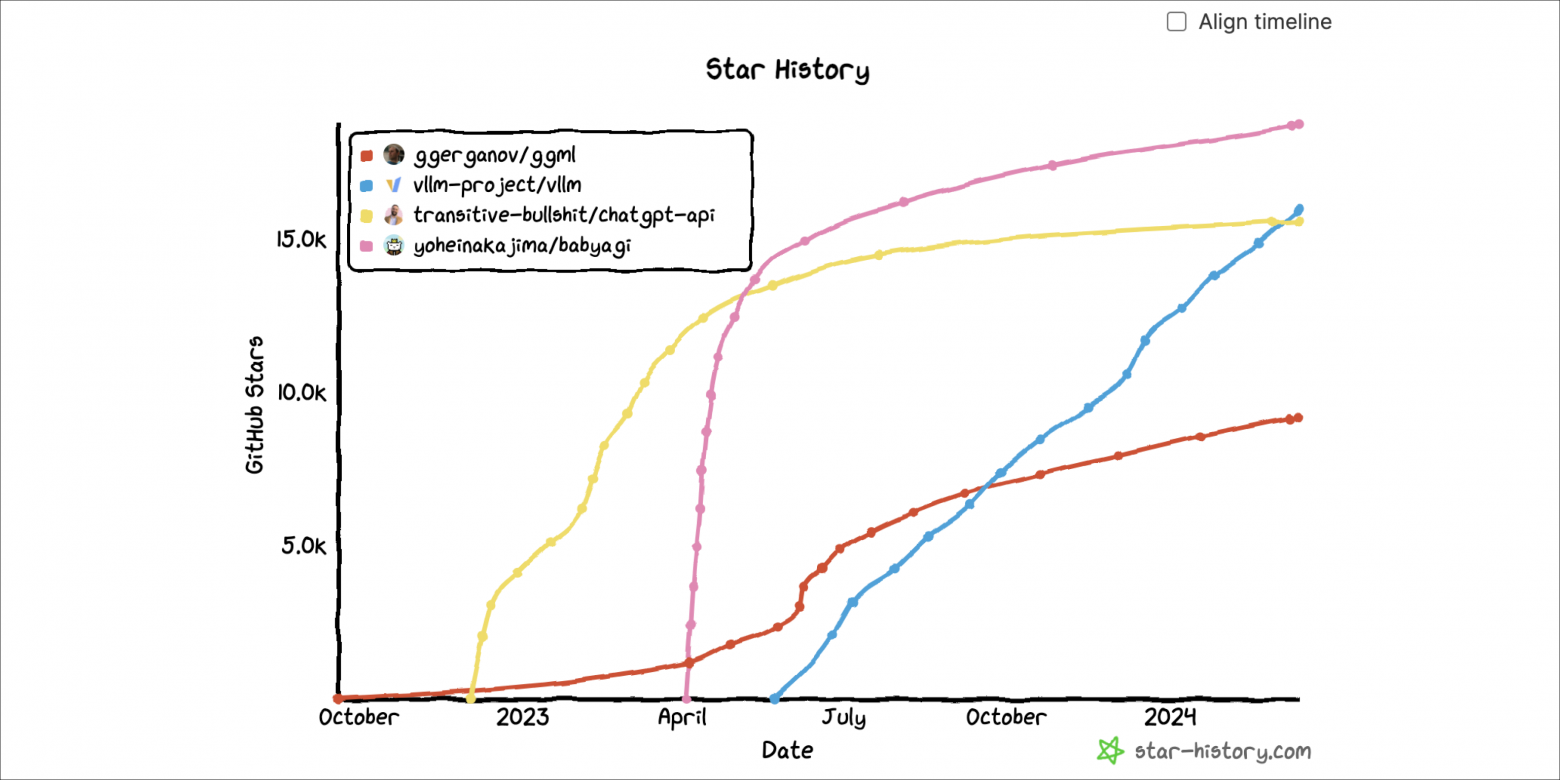
В прошлом году я заметила одну закономерность: многие репозитории быстро набирали огромное количество зрителей, а затем быстро угасали. Некоторые мои друзья называют это «кривой хайпа». Из этих 845 репо, имеющих не менее 500 звезд на GitHub, 158 репо (18,8%) не получили ни одной новой звезды за последние 24 часа, а 37 репо (4,5%) не получили ни одной новой звезды за последнюю неделю.
Вот примеры траектории роста двух таких репо в сравнении с кривой роста двух более стабильных примеров.
Мой персональный выбор
В сообществе рождается много классных идей. Вот некоторые из моих любимых.
Оптимизация пакетного инференса: FlexGen, llama.cpp
Ускоренный декодер: Medusa, LookaheadDecoding
Слияние моделей: mergekit
Ограниченная выборка: outlines, guidance, SGLang
Кажущиеся нишевыми инструменты, которые действительно хорошо решают конкретную проблему — такие как einops и safetensors.
Заключение
Я включила в свой анализ только 845 репозиториев, но просмотрела несколько тысяч. Это помогло мне получить общее представление об экосистеме ИИ. Надеюсь, список будет полезен и вам. Пожалуйста, дайте мне знать, какие репозитории я упустила, и я добавлю их в список!
Habrahabr.ru прочитано 44907 раз
