Технология сегментации изображений, используемая Google в портретном режиме фотосъемки, стала доступна сторонним разработчикам
Компания Google открыла исходные коды модели семантической сегментации изображений DeepLab-v3+. Эта технология, позволяющая понять, какой объект относится в том или ном участке кадра, используется, в частности, в портретном режиме фотосъемки в смартфонах Pixel 2 and Pixel 2 XL, позволяя размывать фон. Впрочем, возможности ее применения не ограничиваются.

Решение Google раскрыть эту технологию позволит сторонним разработчикам использовать очень мощный алгоритм, реализованный средствами библиотеки Tensorflow и позволяющий присвоить каждому пикселю снимка определенную смысловую метку, такую, как «дорога», «небо», «человек» и т.п.
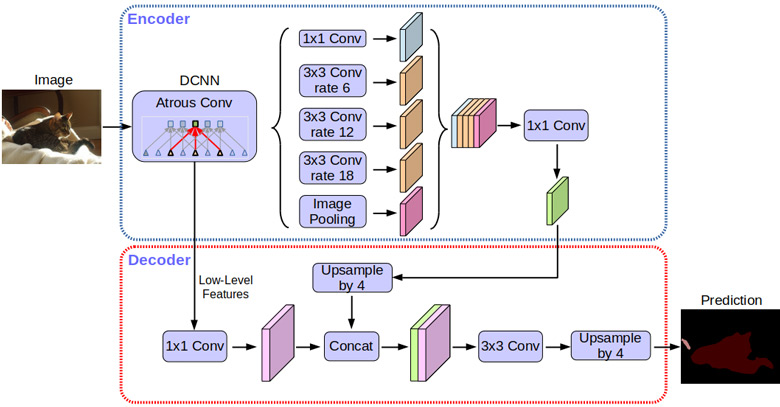
Современные модели семантической сегментации, построенные на сверточных нейронных сетях, достигли точности, на которую трудно было рассчитывать всего несколько лет назад. Наряду с моделью, Google раскрывает код, используемый для ее обучения и оценки, а также экземпляры модели, предварительно обученные на множествах для тестов Pascal VOC 2012 и Cityscapes.
Комментировать
© iXBT
