Расследование Wired. Как утечка Яндекса раскрыла, что именно компания знает про нас и делает с этими данными
В январе 2023 года хакеры слили исходный код части сервисов Яндекса. Это была одна из самых крупных утечек компании. Объем архивов составляет почти 45 ГБ.
По слухам, слив был организован недовольным сотрудником. Он не содержал пользовательские данные, но зато раскрыл подробности о работе сервисов Яндекса.
Поиск Яндекса, Алиса, Такси, Почта и Диск — все эти сервисы были затронуты утечкой.
Кроме того, в опубликованных архивах был код двух систем аналитики Яндекса: Метрики и Крипты. Журналисты Wired совместно с экспертами изучили код, и выяснили, как Яндекс собирает и обрабатывает информацию.
Яндекс собирает огромное количество данных для показа рекламы

Сервисы Яндекса собирают большие объемы данных о людях. Их можно использовать для выявления интересов пользователей, когда они «сопоставляются и анализируются» со всей информацией, которой владеет компания. Об этом говорится в исследовании Кейли МакКри, инженера по конфиденциальности в компании Confiant, которая занимается кибербезопасностью.
Судя по отметкам времени, включенным в данные, код был изменен в июле 2022 года. В основном он написан на русском и английском языке, и содержит расистские оскорбления. Яндекс заявил, что это никак не влияет на работу сервисов, но носит «глубоко оскорбительный и совершенно неприемлемый характер».
МакКри проанализировала код Метрики и Крипты. Яндекс Метрика — это аналог Google Analytics, который позволяет владельцам сайтов отслеживать статистику и поведение пользователей. Данные из Метрики передаются в Крипту — сервис для подбора персонализированной рекламы.
Эта технология даёт рекламодателям максимально точно таргетировать свою целевую аудиторию. Выяснить, принадлежит ли пользователь к такому сегменту, Крипта может по его поведению в интернете.
Яндекс
Компания утверждает, что Крипта анализирует около 300 факторов с помощью различных методов машинного обучения.
Все приложения и сервисы, которые есть у Яндекса, а их, как предполагается, более 90, в той или иной форме передают данные в Крипту для создания рекламных сегментов.
Кейли МакКри, инженер по конфиденциальности Confiant
Некоторые данные передаются, когда люди пользуются сервисами Яндекса. Например, делятся своим местоположением, чтобы посмотреть, где они находятся на карте.
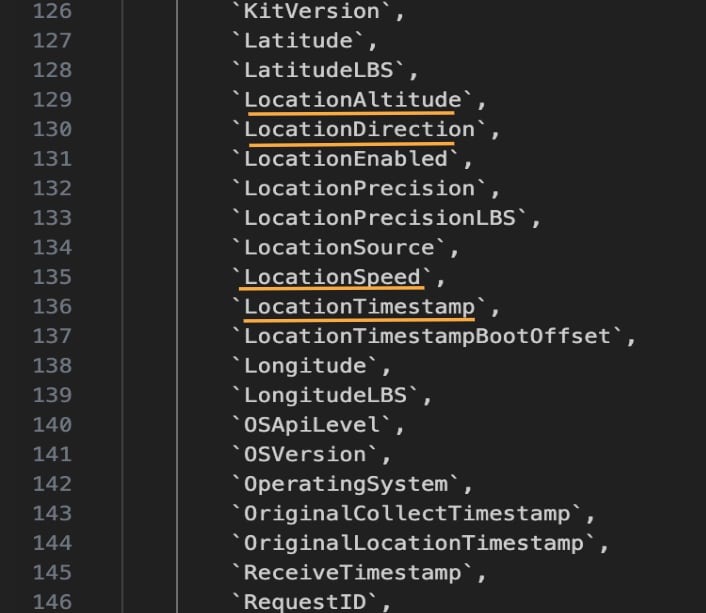
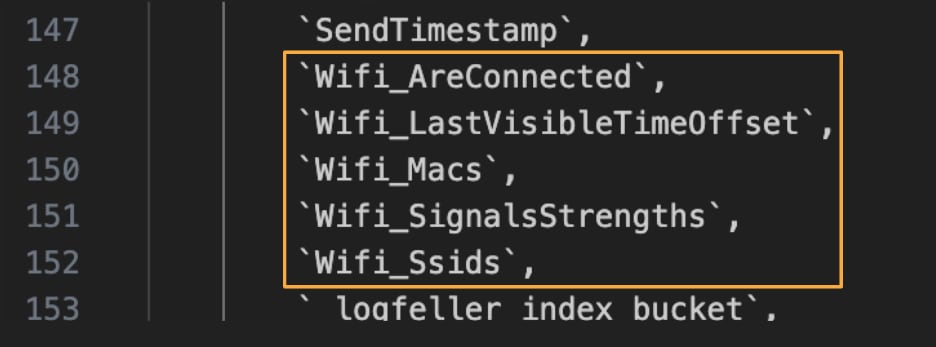
Часть информации собирается автоматически. Компания может узнать данные об устройстве, местоположение, историю поиска, домашний и рабочий адрес, историю прослушивания музыки и просмотра фильмов, данные электронной почты и многое другое.
Исходный код Метрики показал, что сервис может собирать точные данные о геопозиции, включая высоту, направление и скорость движения. Метрика также запоминает имена сетей Wi-Fi, к которым подключаются люди.
Яндекс объединяет пользователей в сегменты. Их бесчисленное множество
Все данные, которые собирает Метрика, передаются в Крипту. Затем они привязываются к общим идентификаторам, которые дополнительно хэшируются.
Пользователь для Крипты — это не конкретный человек с именем и фамилией, а набор идентификаторов. Но почему набор? Дело в том, что каждое устройство и браузер, которым человек пользуется для выхода в сеть, имеет свой уникальный идентификатор — файл cookie, который сайты используют, чтобы узнавать пользователя и, например, не спрашивать каждый раз пароль для входа. Свои идентификаторы есть и у приложений — если приложение (например, Карты или Навигатор) отправляет данные на сервера Яндекса, информацию из его идентификатора Крипта тоже учитывает.
Яндекс
Крипта понимает, когда разные идентификаторы принадлежат одному пользователю. После этого Крипта распределяет людей по сегментам на разные темы, но которым можно показать одну и ту же рекламу.
Крипта анализирует поведение человека в интернете и «вычисляет вероятность» его принадлежности к тому или иному сегменту.
Объем данных, который Яндекс получает через Метрику, настолько огромен, что просто невозможно даже представить. Этого достаточно, чтобы создать любую группу или сегмент аудитории.
Григорий Бакунов, бывший директор по распространению технологий Яндекса
Сегменты, которые создает Крипта, кажутся очень специфичными, но в то же время они показывают, насколько мощными являются данные о нашей онлайн-жизни, когда они собраны в одном месте. Среди них есть группы людей, которые пользуются Яндекс Станциями, любители кино могут быть сгруппированы по жанру, есть сегмент пользователей ноутбуков, которые искала отель Radisson на карте.

Пример сегментов в Крипте.
Группа «курильщиков» отслеживает людей, которые покупают товары, связанные с курением, например, электронные сигареты. «Дачники» могут находить людей, у которых есть дачи, используя данные о местоположении. Сегмент «путешественники» тоже использует геопозицию для поиска путешественников, поездки разбиваются на международные и внутренние. Часть кода предназначалась для получения данных из приложения Почта и включала поля «отели» и «посадочные талоны».

Яндекс может объединять идентификаторы в «семьи», если их IP-адреса «пересекаются». Данные о «семье» могут включать количество людей, их пол и возраст.
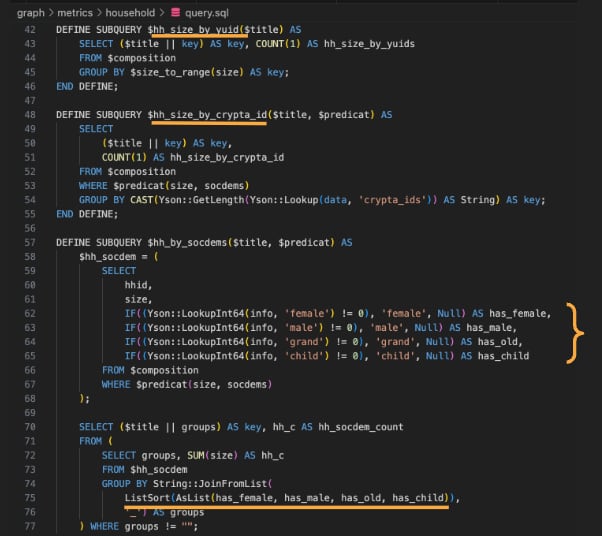
Сервисы Яндекса позволяют предсказывать, есть ли у пользователя дети. Например, люди могут заказывать такси с детскими сиденьями. По словам директора по защите данных Яндекса Ивана Черевко, это может быть свидетельством того, что пользователю будет интересен контент для родителей.
Один элемент в коде Crypta показывает, как все эти данные могут быть объединены. Существует пользовательский интерфейс, который действует как профиль кого-либо. В этом интерфейсе показывается семейное положение человека, прогнозируемый доход, наличие детей и три увлечения, которые включают в себя общие темы, такие как бытовая техника, еда, одежда и отдых.
Черевко заявил, что это «внутренний инструмент Яндекса», где сотрудники могут видеть, как алгоритмы Крипты их классифицируют, и они могут получить доступ только к своей собственной информации.
Сбор данных в таком количестве — стандартная практика для интернет-компаний
Интерфейс Google Analytics, аналога Яндекс Метрики.
МакКри отметила, что часть этой информации «не кажется чем-то необычным» для интернет-рекламы. Такого же мнения придерживается и Иван Черевко.
Он добавил, что группировка пользователей по интересам является «стандартной отраслевой практикой». Сбор информации позволяет показывать людям конкретную рекламу: «товары для сада пользователям, которые интересуются дачами и автозапчасти — тем, кто посещает АЗС». Но все данные в Яндексе обезличены.
Для Крипты каждый пользователь представляется в виде набора идентификаторов, и система не может связать их с физическим лицом в реальном мире. Такой набор является только вероятностным.
Иван Черевко, директор по защите данных Яндекса
Крипта не имеет доступа к электронной почте пользователей. Информация об отелях и посадочных талонах, обнаруженная в коде Почты, была экспериментом. Крипта получала от Почты только обезличенную информацию, но этот метод не используется с 2019 года. Также Черевко сообщил, что Яндекс удаляет геолокацию пользователей, собранную Метрикой, через 14 дней.
Каким образом Яндекс на самом деле собирает информацию — неизвестно

Скриншот форума, где был выложен архив.
45 ГБ исходного кода охватывают многие сервисы Яндекса. В основном используются языки программирования Python, C++ и YQL.
Утечка содержала только код, а не настоящий репозиторий, который показывал бы историю версий. Это означает, что можно только предположить, что делает код, но невозможно точно утверждать, какие части кода использовались или действуют в настоящее время.
Черевко утверждает, что «фрагменты кода» устарели, они отличаются от версий, используемых в настоящее время, и что часть исходного кода «никогда фактически не использовалась» Яндексом.
Также, по словам представителя Яндекса, компания использует данные пользователей только для создания новых сервисов и улучшения существующих. Она никогда не продает данные и не раскрывает их третьим лицам без согласия пользователя.
