Рассказываем, как работает нейросеть Speech2Face. Она создаёт лица по голосу
Пытались ли вы когда-либо представить, как выглядит незнакомый человек, с которым вы разговариваете по телефону? Особенно, если это очередной раздражающий звонок из банка с предложением кредита.
Скоро послать «занудную брюнетку 25 лет с зелеными глазами и мягким голосом» поможет специальная нейронная сеть.
Идея «восстановить» внешность человека по короткой аудиозаписи говорящего человека родилась появилась у основателей проекта Speech2Face. Рассказываем какие технологии помогают им в этом.
Speech2Face анализирует лица в роликах на YouTube
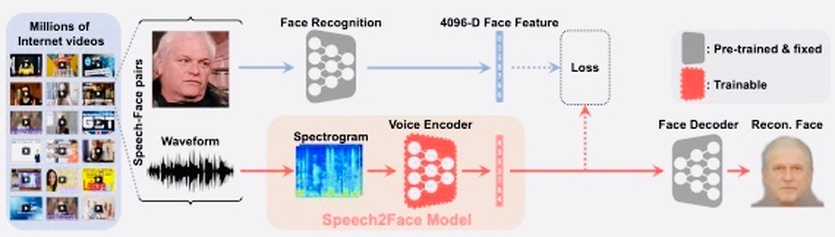
В проекте Speech2Face в качестве источников вводных данных используются миллионы видеороликов в Интернете и, в частности, на Youtube. Во время обучения сеть анализирует аудиовизуальные, голосовые корреляции. Они позволяют создавать изображения, отражающие различные физические характеристики говорящих, такие как возраст, пол и этническая принадлежность.
Любопытно, что некоторые особенности предсказанных сетью лиц могут не быть физически связаны с речью, например, цвет волос. Однако, многие люди, говорящие определенным образом, (например, на одном языке) также имеют некоторые общие визуальные черты.
Демонстрация работы датасета AVSpeech, на котором работает Speech2Face:
Метод не сможет восстановить точную внешность человека по его голосу. Это связано с тем, что модель обучена лишь отмечать визуальные особенности и фиксировать связь визуальных функций с вокальными и речевыми атрибутами.
Другими словами, модель не будет воспроизводить изображения конкретных людей.
Вы сможете знать, что вам позвонила блондинка, но точную ее внешность все равно не узнаете. Увы.
Speech2Face состоит из спектограмм и векторых данных
В качестве основы используется датасет AVSpeech и предобученная сеть VGG-Face, которая способна сопоставлять особенности речи с рядом биометрических характеристик человека.
Модель принимает спектограмму* аудиозаписи голоса, после чего выдает векторные данные с характеристиками лица, которые в свою очередь уже декодируются в финальное изображение лица.
* cпектограмма — визуальное представление аудиоволн
Используемые данные — это коллекция видеороликов с YouTube, а значит входные данные не в равной степени представляют все население мира. Другими словами, модель неточна и данные распределены неравномерно. Очевидно, что определенные национальности (например, африканские) система знает хуже других.
Например, если определенный язык не отображается в данных обучения, реконструкция внешности не будет хорошо отражать черты лица, которые могут коррелировать с этим языком.
Поэтому сейчас технология активно тестируется и проверяется, чтобы гарантировать максимально точный результат. В случае нахождения серьезных разночтений голоса и внешности создатели собирают более репрезентативные данные.
Speech2Face пока ошибается, но результаты все равно удивляют
Нельзя сказать, что на данный момент система работает точно. Так, в примере приводятся несколько лиц (в том числе известных личностей), но выдаваемый результат далеко не всегда совпадает с оригиналом.
Например, система сильно состарила внешность Дэниела Крейга и ошиблась с цветом волос Марии Шараповой.

Любопытно, что чем длиннее входная аудиозапись, тем и ближе сгенерированное изображение к истинному.

Повторюсь, что на данный момент цель проекта состоит не в том, чтобы восстановить точное изображение человека, а скорее в том, чтобы восстановить характерные физические особенности, которые коррелируют с его речью. Но авторы Speech2Face планируют продолжить исследования.
Возможно, в недалеком будущем мы сможем скачать приложение, способное предугадывать внешность неизвестного телефонного собеседника. Звучит фантастически, но в нынешнее время высоких технологий и нейросетей все возможно. Ждем. [Arxiv]
