Проект по добавлению в GCC поддержки распараллеливания процесса компиляции
В рамках исследовательского проекта Parallel GCC началась работа по добавлению в GCC возможности, позволяющей разделять процесс компиляции на несколько параллельно выполняемых потоков. В настоящее время для повышения скорости сборки на многоядержных системах на уровне утилиты make применяется запуск отдельных процессов компилятора, каждый из которых выполняет сборку отдельного файла с кодом. Новый проект экспериментирует с обеспечением распараллеливания на уровне компилятора, что потенциально позволит повысить эффективность работы на многоядерных системах.
Для тестирования подготовлена отдельная распараллеливающая ветка GCC, для задания числа потоков в которой предложен новый параметр »--param=num-threads=N». На начальном этапе реализован вынос в отдельные потоки выполнения межпроцедурных оптимизаций, которые циклично вызываются для каждой функции и хорошо поддаются распаралелливанию. В отдельные потоки вынесены операции GIMPLE, отвечающие за независящие от оборудования оптимизации, оценивающие взаимодействие функций между собой.
На следующем этапе в отдельные потоки также планируется вынести межпроцедурные RTL-оптимизации, учитывающие особенности аппаратной платформы. После этого планируется реализовать распараллеливание внутрипроцедурных оптимизаций (IPA), применяемых к коду внутри функции, независимо от особенностей вызова. Ограничивающим звеном пока является сборщик мусора, в который добавлена глобальная блокировка, отключающая операции сборки мусора во время работы в многопоточном режиме (в будущем сборщик мусора будет адаптирован для многопоточного выполнения GCC).
Для оценки изменения производительности подготовлен тестовый набор, осуществляющий сборку файла gimple-match.c, включающего более 100 тысяч строк кода и 1700 функций. Тесты на системе с CPU Intel Core i5–8250U с 4 физическими ядрами и 8 виртуальными (Hyperthreading) показали снижение времени выполнения оптимизаций Intra Procedural GIMPLE с 7 до 4 секунд при запуске 2 потоков и до 3 секунд при запуске 4 потоков, т.е. достигнуто увеличение скорости рассматриваемого этапа сборки в 1.72 и 2.52 раза, соответственно. Тесты также показали, что использование виртуальных ядер при Hyperthreading не приводит к росту производительности.
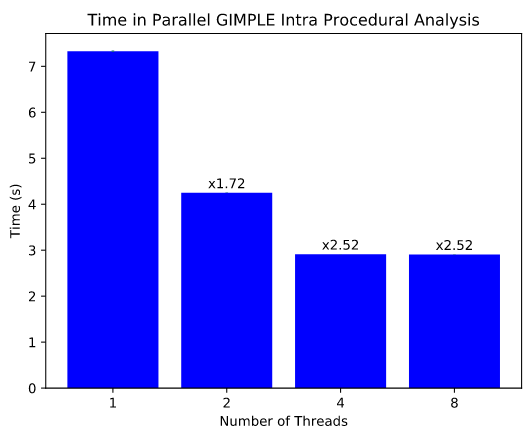
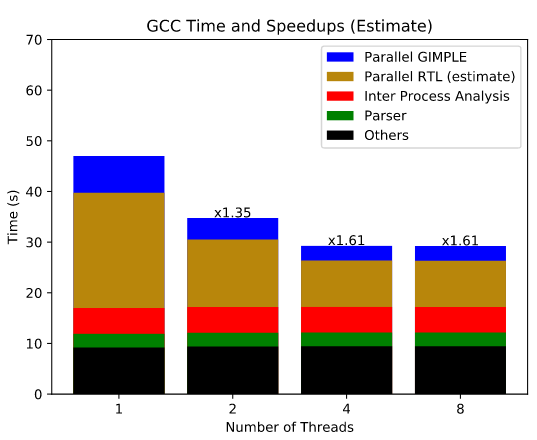
Общее время сборки сократилось приблизительно на 10%, но по прогнозам распараллеливаие RTL-оптимизаций позволит добиться более ощутимых результатов, так как данная стадия занимает при компиляции существенно больше времени. Ориентировочно после распараллеливания RTL общее время сборки сократится в 1.61 раза. После этого еще на 5–10% можно будет сократить время сборки за счёт распараллеливания оптимизаций IPA.
© OpenNet
