Представлено внутреннее соединение Nvidia NVLink, призванное ускорить обмен между GPU и CPU
Компания Nvidia рассказала о планах использовать высокоскоростное внутреннее соединение, получившее название Nvidia NVLink, в своих будущих GPU. По словам производителя, Nvidia NVLink позволит GPU и CPU обмениваться данными в 5–12 раз быстрее, чем это возможно сегодня. За счет этого будет устранено узкое место, ограничивающее рост производительности компьютеров. Как утверждается, Nvidia NVLink «проложит путь к новому поколению суперкомпьютеров, которые будут в 50–100 раз быстрее самых производительных сегодняшних систем».
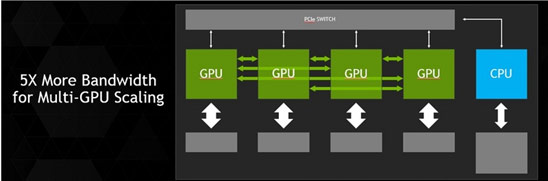 Новую технологию Nvidia планирует использовать в архитектуре графических процессоров Pascal, которая будет представлена в 2016 году и придет на смену Nvidia Maxwell. В создании Nvidia NVLink принимала участие компания IBM, которая намерена использовать разработку в будущих версиях процессоров Power.
Новую технологию Nvidia планирует использовать в архитектуре графических процессоров Pascal, которая будет представлена в 2016 году и придет на смену Nvidia Maxwell. В создании Nvidia NVLink принимала участие компания IBM, которая намерена использовать разработку в будущих версиях процессоров Power.
C помощью NVLink процессоры IBM Power будут тесно связаны с GPU Nvidia Tesla, что позволит полнее использовать потенциал ускорения вычислений с помощью GPU.
В настоящее время для «общения» x86-совместимых CPU и GPU используется шина PCI Express 3.0. Она в несколько медленнее типичного контроллера памяти, встроенного в CPU. В случае процессоров IBM Power разница еще заметнее, поскольку их подсистема памяти обладает большей пропускной способностью, чем у процессоров x86. Так как возможности NVLink соответствуют пропускной способности подсистемы памяти CPU, новое соединение позволит GPU иметь доступ к памяти, используемой CPU, на полной скорости.
Более того, используя модель Unified Memory, программисты могут рассматривать память, доступную CPU, и память, доступную GPU, как один блок. Другими словами, им не придется задумываться над тем, где физически находятся данные.
Производитель отмечает, что его будущие GPU будут также поддерживать и PCIe, поскольку использование NVLink возможно только с совместимыми CPU и между несколькими совместимыми GPU.
Источник: Nvidia
#vk
© iXBT
