Новости первого дня GPU Technology Conference 2015 — часть 3 из 3
Наш корреспондент завершает рассказ о первом дне GPU Technology Conference 2015, начатый в первой и продолженный во второй новостях на эту тему.
Глава Nvidia рассказал на GTC и о следующем поколении графической архитектуры — Pascal. Ничего особенно нового о ней мы не услышали, а о самом существовании было давно известно. Pascal — это следующая архитектура GPU компании, которая ожидается к выходу в 2016 году. Кроме всего прочего, от новинки ожидают до 10-кратного увеличения производительности в задачах deep learning, по сравнению с текущими чипами Maxwell.
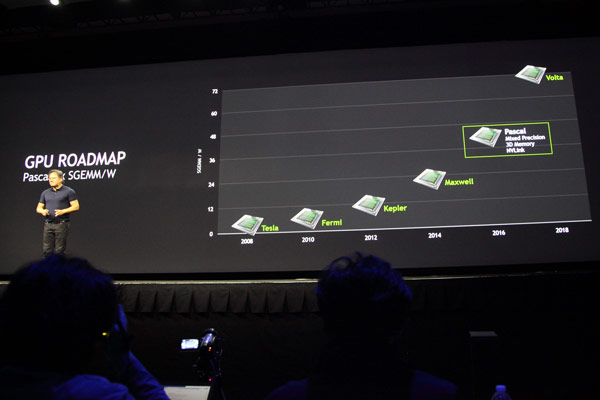 По ходу своего выступления Дженсен раскрыл некоторые детали Pascal и показал обновленный план по выпуску графических решений в ближайшие годы, выразив надежду, что новая архитектура после более чем трёхлетней разработки проявит себя с положительной стороны. Так как основной темой нынешней GTC является deep learning (использование самообучающихся нейросетей), то рассказали о том, как это сказалось на дизайне Pascal, анонсированном на прошлой конференции.
По ходу своего выступления Дженсен раскрыл некоторые детали Pascal и показал обновленный план по выпуску графических решений в ближайшие годы, выразив надежду, что новая архитектура после более чем трёхлетней разработки проявит себя с положительной стороны. Так как основной темой нынешней GTC является deep learning (использование самообучающихся нейросетей), то рассказали о том, как это сказалось на дизайне Pascal, анонсированном на прошлой конференции.
Графические решенияя Pascal будут иметь три основных достоинства, связанных с подобным применением, что вызовет более точное и быстрое обучение сложных и глубоких нейросетей. Вместе с максимальным объёмом памяти в 32 гигабайта (что почти втрое больше, чем у анонсированного только что Titan X), выделяется ещё одно новшество — Pascal поддерживает вычисления смешанной точности. Также в GPU следующей архитектуры будет применяться память с объемной компоновкой (stacked DRAM), которая в пять раз быстрее в приложениях deep learning. Также необходимо помнить и о поддержке высокоскоростных внутренних соединений NVLink, объединяющих два или более GPU. Всё вместе это в результате должно дать 10-кратный прирост в указанных задачах.
 Вычисления смешанной точности в Pascal используются для двойного ускорения расчётов, которым достаточно 16-битной «половинной» точности вычислений — они вдвое быстрее, чем привычные FP32 (одинарная точность). Увеличенная производительность таких вычислений даст прирост скорости классификации и свёртки (convolution) — двух важных шагах deep learning, при сохранении достаточной точности вычислений.
Вычисления смешанной точности в Pascal используются для двойного ускорения расчётов, которым достаточно 16-битной «половинной» точности вычислений — они вдвое быстрее, чем привычные FP32 (одинарная точность). Увеличенная производительность таких вычислений даст прирост скорости классификации и свёртки (convolution) — двух важных шагах deep learning, при сохранении достаточной точности вычислений.
Применение памяти с объемной компоновкой позволит увеличить скорость доступа к данным и одновременно повысить энергетическую эффективность. Это очень важно, так как именно ограничения ПСП зачастую определяют и конечную скорость сложных параллельных расчётов, и внедрение 3D-памяти обеспечит трёхкратный рост ПСП при таком же увеличении объёма буфера кадра (объема видеопамяти) — это позволит исследователям строить нейросети большего размера и ускорить некоторые из частей тренировки машинного алгоритма при глубоком обучении.
Как уже было известно, графические процессоры архитектуры Pascal будут иметь микросхемы памяти поставленные друг на друга и на GPU, вместо того, чтобы быть размещёнными на печатной плате. Уменьшение длины проводников между чипами памяти и GPU приведет к повышению быстродействия и энергетической эффективности.
 Добавление поддержки скоростного соединения NVLink к Pascal ускорит перемещение данных между GPU и CPU в 5–12 раз, по сравнению с передачей данных по ныне используемой шине PCI Express, что также серьёзно ускорит приложения deep learning, требующие быстрого сообщения между графическими процессорами. Это особенно важно для глубокого обучения, так как одно только появление NVLink позволит вдвое увеличить количество GPU в системе, одновременно работающих над одной и той же задачей deep learning.
Добавление поддержки скоростного соединения NVLink к Pascal ускорит перемещение данных между GPU и CPU в 5–12 раз, по сравнению с передачей данных по ныне используемой шине PCI Express, что также серьёзно ускорит приложения deep learning, требующие быстрого сообщения между графическими процессорами. Это особенно важно для глубокого обучения, так как одно только появление NVLink позволит вдвое увеличить количество GPU в системе, одновременно работающих над одной и той же задачей deep learning.
Источник: Собственный корреспондент iXBT на GPU Technology Conference 2015
Теги: Nvidia Комментировать
© iXBT
