Сайт дня: NewOCR - подрастающий убийца FineReader
Сегодня сайтом дня объявляется онлайновый сервис распознавания текста NewOCR.

Чуть меньше года назад я писал про замечательный сайт ABBYY FineReader Online, который для того времени казался безусловно лучшим решением. Да, он слегка платный. Зато отлично распознаёт и понимает разные языки. Хотя немного, совсем капельку неудобный. Но что тут говорить, все привыкли, что конкуренты заметно отстают, так что выбора-то и нет.
За этот почти год я убедился, что выбор есть. Все годы, пока развивалась индустрия программ OCR (оптического распознавания текста) конкуренты отставали от FineReader на несколько шагов. Когда FineReader ещё не было, OCR-программы напоминали детские демки, так что это не считается. Но шли годы, OCR-программы, такие как Tesseract и Cuneiform, гнались за FineReader, и постепенно добежали до такого уровня, когда ими стало можно пользоваться. Возможно, FineReader ещё лучше, но это уже тот уровень, когда начинает играть роль понятие "достаточно".
Потестировав недавно Tesseract и Cuneiform на смартфоновых снимках русскоязычного текста я убедился, что их наконец-то достаточно. Возможно, их ещё и год назад было бы достаточно, если бы я тогда взялся потестировать.
Естественно, я сразу же начал искать к ним хороший интерфейс (благо, это свободные программы и интерфейс можно выбирать). В конце концов мне понравился веб-интерфейс на сайте NewOCR. Он простой, понятный, быстрый, и поддерживает обе OCR-программы и оба нужных мне языка (среди прочих).
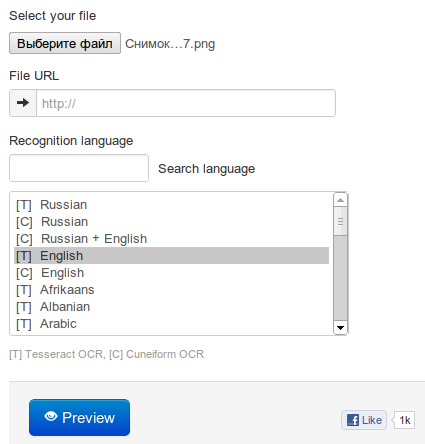
Выбор файла и метода на сайте NewOCR
Всё предельно понятно, выбираем файл из сети или с компьютера (поддерживаются форматы JPEG, PNG, GIF, BMP, TIFF, PDF и DjVu), выбираем язык и способ распознавания (в Cuneiform можно распознать смешанный, русско-английский текст; в Tesseract пока почему-то нельзя) и практически всё.
Для примера, распознаем скриншот их хелпов самого сайта NewOCR. Вот такой:

Тестовый скриншот
В предварительном просмотре нам предлагают выбрать область для распознавания. Конечно, у десктопного варианта FineReader возможностей больше, а с онлайновым - вполне сравнимо.

Предварительный просмотр и выбор области распознавания на сайте NewOCR
Далее текст распознаётся. Неожиданно быстро, хотя возможно NewOCR просто ещё недостаточно популярен, чтобы быть перегруженным. Хорошо распознаются не только качественные скриншоты, но и довольно шумные сканы и мутные снимки. Всего год назад эти же программы работали ощутимо хуже. Интересно, что Tesseract и Cuneiform ошибаются немного по-разному, так что особо сложный текст можно распознавать и тем и другим, а потом сливать результаты каким-нибудь онлайновым diff-ом (если интересно - скажите, я напишу про один из таких).
Распознанный текст на NewOCR вполне предсказуемо можно сохранить в разных форматах, перевести или редактировать (в Google).
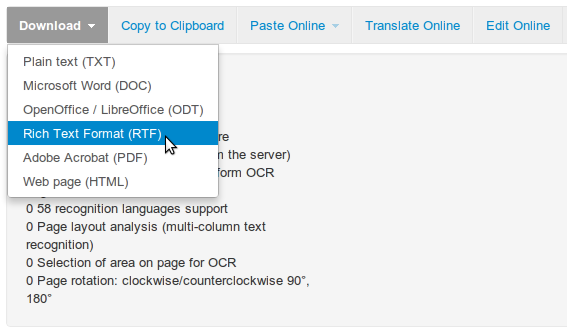
Распознанный текст и варианты действий с ним на сайте NewOCR
Программы Tesseract и Cuneiform дорабатываются сообществом, но очень медленно. Видимо, разработчики уже поняли, что распознают они нормально, и больше проблем именно с интерфейсами. К счастью, сейчас эти программы стоят того, чтобы делать к ним хорошие интерфейсы, такие, например, как сайт NewOCR
Знаете ещё хорошие сайты? Пишите на sitesoftheday@ferra.ru.
© Ferra.ru
