Mozilla добавит в Firefox 130 AI-возможность для генерации описаний изображений
Разработчики Firefox поделились планами по расширению использования в браузере возможностей на основе механизмов машинного обучения. Начиная с выпуска Firefox 130, намеченного на 3 сентября, в браузер будет включена функциональность для автоматической генерации текстовых описаний изображений. Тестирование реализации уже началось в ночных сборках Firefox, в которых подобная функциональность встроена в PDF-просмотршик. На первом этапе для тестирования работы алгоритма описание генерируется только при добавлении новых изображений в качестве подсказки, но в дальнейшем его планируют применить и для существующих изображений.
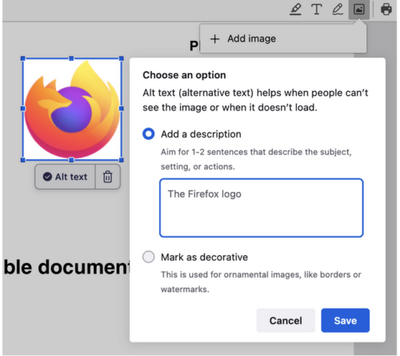
Предполагается, что наличие текстовых описаний, которые можно будет выводить через экранные ридеры, упростит работу людей, имеющих проблемы со зрением. Функция реализована через интеграцию модели машинного обучения, выполняемой на локальной системе пользователя без обращения к внешним сервисам, по аналогии с тем как уже работает встроенная система перевода с одного языка на другой.
Модель для генерации текстовых описаний занимает примерно 200 МБ на диске, использует данные модели DistilGPT2 и охватывает 182M параметров. Для анализа изображений задействован декодировщик на базе модели Vision Transformer (ViT). Для работы с моделью в состав браузера включён ONNX Runtume, скомпилированный в представление WASM, и библиотека Transformers.js. Модель загружается динамически перед первым использованием.

Источник: http://www.opennet.ru/opennews/art.shtml? num=61297
© OpenNet
