Meta* представили TRIBE v2 — модель, предсказывающую активность мозга по видео, аудио и тексту
Meta* представили TRIBE v2 — новую модель, которая объединяет видео, аудио и текст для предсказания активности человеческого мозга. Разработка предлагает новый подход к изучению работы мозга через симуляцию его реакции на различные стимулы.
TRIBE v2 (Tri-modal Brain Encoder) использует мультимодальную архитектуру, объединяющую данные из трёх источников: видео, аудио и текста. Модель обучалась на массиве данных, включающем более 1000 часов записей фМРТ 720 участников, и способна предсказывать активность мозга в 20 484 вершинах кортикальной поверхности («точки» на поверхности коры головного мозга, которые модель отслеживает для анализа активности) и 8 802 вокселах подкорковых структур («объёмные элементы» внутри более глубоких структур мозга, таких как таламус, базальные ганглии или гиппокамп). Иными словами, TRIBE v2 предсказывает активность мозга не только на поверхности коры, но и глубоко внутри мозга, охватывая 3D-структуру нейронной активности. Это делает её одной из самых точных моделей для анализа нейронной активности.
Ключевая особенность TRIBE v2 — использование предобученных нейросетей для обработки каждой модальности. Видео анализируется с помощью V-JEPA 2, аудио — через Wav2Vec-Bert, а текст — с использованием Llama 3.2. Эти данные объединяются трансформером с 1 миллиардом параметров, который моделирует временные зависимости и интеграцию модальностей. Такой подход позволяет модели предсказывать реакцию мозга даже в условиях отсутствия одной из модальностей благодаря механизму «modality dropout».
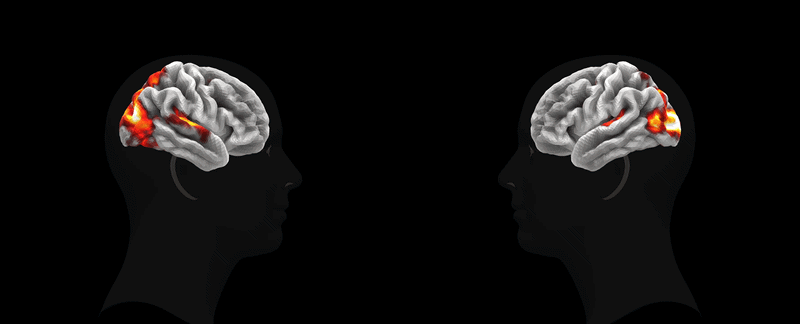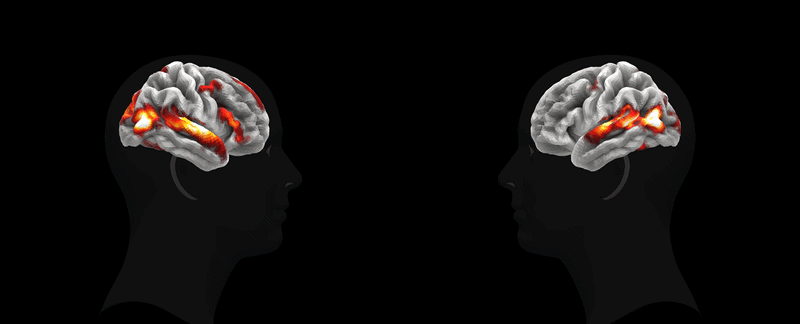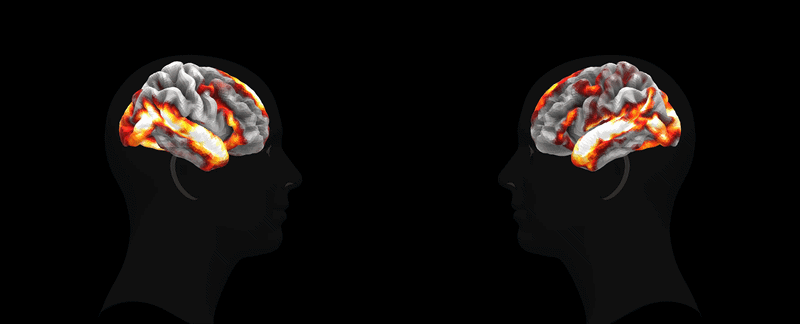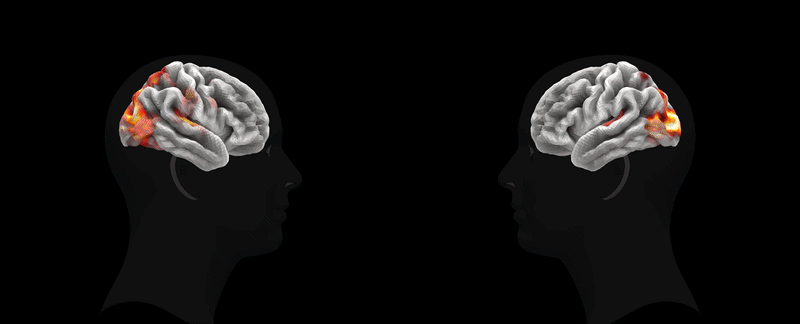 Анимация: Meta*
Анимация: Meta*TRIBE v2 воспроизводит результаты классических экспериментов. Например, модель точно идентифицирует специализированные области коры, такие как FFA (распознавание лиц), PPA (восприятие локаций) и VWFA (обработка письменных знаков). Она также успешно воспроизводит карты активации для сложных нейролингвистических задач, таких как различие между речью и другими звуками или обработка сложных предложений. Кроме того, модель демонстрирует высокую степень генерализации, предсказывая реакцию мозга на новые стимулы без дополнительного обучения.
TRIBE v2 объясняет около 54% вариации сигнала, а в отдельных областях достигает 80%, что превосходит возможности традиционных методов, таких как fMRI. Примечательно, что модель способна предсказывать групповой усреднённый ответ на стимулы точнее, чем записи активности отдельных участников. Это открывает новые перспективы для нейронаучных исследований, позволяя изучать мозг in-silico и тестировать гипотезы без необходимости проведения дорогостоящих экспериментов.
Модель также демонстрирует действие законов масштабирования: точность её предсказаний растёт с увеличением объёма данных. Это делает TRIBE v2 перспективной платформой для дальнейшего развития, особенно с учётом её способности адаптироваться с минимальным количеством данных.
Несмотря на свои достижения, TRIBE v2 имеет ограничения. Она не учитывает такие сенсорные входы, как обоняние и осязание, и рассматривает мозг как «пассивного наблюдателя», а не активного агента. Кроме того, модель ограничена временным разрешением фМРТ, что затрудняет анализ быстрых нейронных процессов. Однако потенциал для масштабирования и интеграции новых данных делает её мощным инструментом для будущих исследований.
* Компания Meta (Facebook и Instagram) признана в России экстремистской и запрещена
© iXBT
