ИИ перестанет «забывать»: Андрей Карпати предложил новый способ работы с LLM вместо RAG
Андрей Карпати, бывший директор по искусственному интеллекту Tesla и сооснователь OpenAI, представил новый подход к управлению знаниями, который может изменить подход к исследовательским проектам. Его метод, названный LLM Knowledge Bases, предлагает использовать большие языковые модели (LLM) для создания и поддержания структурированных баз знаний в формате Markdown (.md). Этот подход решает проблему потери контекста в ИИ-проектах, делая процесс работы более эффективным и прозрачным.
Карпати описал свою систему как способ решения проблемы «статичности» ИИ, когда контекст работы теряется после завершения сессии. В отличие от традиционных решений, таких как векторные базы данных и Retrieval-Augmented Generation («генерация, дополненная поиском», RAG), его подход делает акцент на простоте и прозрачности. Вместо сложных алгоритмов поиска система Карпати использует LLM для создания, редактирования и поддержания базы знаний. Исходные материалы, такие как научные статьи, репозитории и веб-контент, сохраняются в формате Markdown. Карпати использует инструмент Obsidian Web Clipper для преобразования веб-страниц в локальные файлы, включая изображения.
 Изображение сгенерировано: Grok
Изображение сгенерировано: GrokLLM анализирует собранные данные, создаёт структурированные статьи, генерирует ссылки между связанными концепциями и пишет энциклопедические заметки. Этот процесс позволяет превратить разрозненные данные в связную базу знаний. Система регулярно проводит «проверки здоровья» (linting), исправляя несоответствия, добавляя новые связи и обновляя информацию. Это делает базу знаний «живой» и самовосстанавливающейся.
Карпати подчёркивает, что использование Markdown делает систему прозрачной и доступной. Каждый файл можно легко прочитать, отредактировать или удалить вручную. Это устраняет проблему «чёрного ящика», характерную для векторных баз данных и «скиллов», где сложно отследить источник информации или их применение. Кроме того, система Карпати позволяет эффективно использовать ресурсы LLM. Вместо обработки больших объёмов данных в реальном времени, модель работает с уже структурированной информацией, что снижает нагрузку и повышает точность.
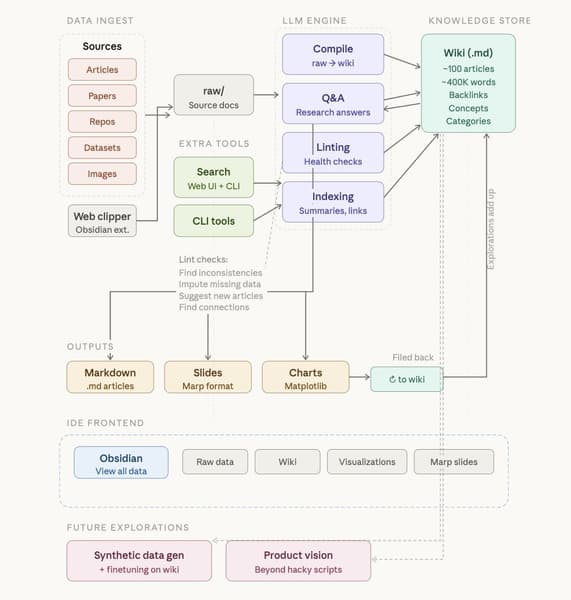 Архитектура системы. Источник: X@himanshu
Архитектура системы. Источник: X@himanshuХотя система Карпати изначально разрабатывалась для личных исследовательских проектов, у неё большой потенциал для корпоративного использования. Компании могут использовать этот подход для создания «корпоративной библии», которая будет автоматически обновляться и синхронизироваться с внутренними данными. Это особенно актуально для организаций с большим объёмом неструктурированных данных, таких как отчёты, логи и внутренние вики.
Карпати видит дальнейшее развитие своей системы в направлении генерации синтетических данных и дообучения моделей. По мере роста базы знаний она может стать подходящим набором данных для обучения специализированных ИИ-моделей, которые будут интегрировать знания напрямую в свои веса. Его подход уже вызвал интерес в сообществе. Например, Лекс Фридман, известный подкастер и исследователь, использует схожую систему для создания временных баз знаний, которые помогают ему в работе.
Я часто использую систему для генерации динамического HTML (с JavaScript), что позволяет мне сортировать/фильтровать данные и интерактивно работать с визуализациями. Еще одна полезная функция — система генерирует временную, узкоспециализированную мини-базу знаний, которую я затем загружаю в LLM для голосового взаимодействия во время длительной пробежки на 7–10 миль
Лекс Фридман
Другие эксперты отмечают, что метод Карпати может стать основой для новых продуктов, способных трансформировать управление знаниями как в личных, так и в корпоративных масштабах.
© iXBT
