Facebook открыл код распределённого SQL-движка для петабайтных хранилищ
Компания Facebook перевела в разряд открытых систему Presto, созданную в качестве высокопроизводительной альтернативы технологиям MapReduce и Hive, ранее используемым для выполнения запросов в многопетабайтных хранилищах на базе платформы Hadoop. Presto находится в разработке с осени прошлого года и развивается для решения проблем с длительным временем отклика, свойственным существующим средствам обработки данных для имеющегося в Facebook хранилища на базе Hadoop, размер которого превысил 300 петабайт. 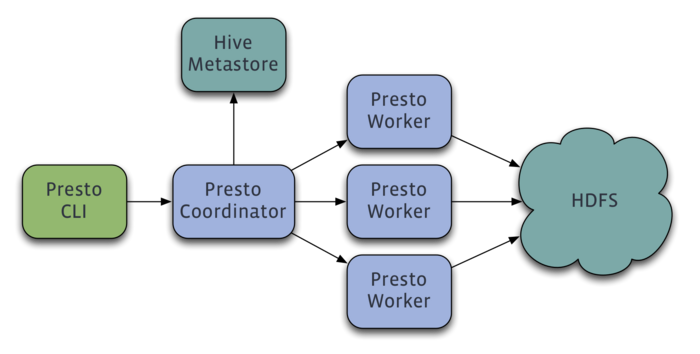 Presto позволяет формировать запросы с использованием языка SQL, обеспечивая при этом в десять раз более высокую производительность и отзывчивость, по сравнению с Hive/MapReduce. Движок не ограничивается работой поверх Hadoop и может использоваться в связке с обычными реляционными БД и проприетарными системами хранения. Для абстрагирования от нижележащего хранилизща в Presto применяется механизм подключаемых бэкендов. В отличие от Hive, Presto не транслирует запрос в серию последовательно выполняемых MapReduce-задач, каждая из которых читает данные с диска и записывает на диск промежуточный результат. Вместо этого, Presto предоставляет собственный механизм выполнения запросов, отличающийся улучшенной системой планирования, выполнением обработки данных в оперативной памяти и применением конвейерной обработки, при которой несколько стадий запроса выполняется за один раз.
Presto позволяет формировать запросы с использованием языка SQL, обеспечивая при этом в десять раз более высокую производительность и отзывчивость, по сравнению с Hive/MapReduce. Движок не ограничивается работой поверх Hadoop и может использоваться в связке с обычными реляционными БД и проприетарными системами хранения. Для абстрагирования от нижележащего хранилизща в Presto применяется механизм подключаемых бэкендов. В отличие от Hive, Presto не транслирует запрос в серию последовательно выполняемых MapReduce-задач, каждая из которых читает данные с диска и записывает на диск промежуточный результат. Вместо этого, Presto предоставляет собственный механизм выполнения запросов, отличающийся улучшенной системой планирования, выполнением обработки данных в оперативной памяти и применением конвейерной обработки, при которой несколько стадий запроса выполняется за один раз.
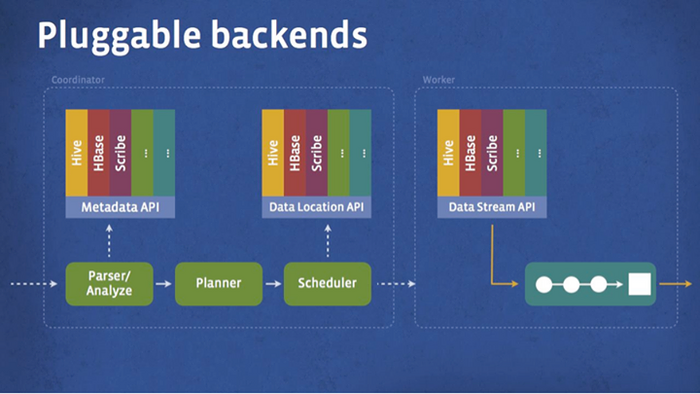 Сформированный в Presto запрос может охватывать несколько источников данных, агрегируя полученные сведения в единый итоговый результат. В качестве основной области применения Presto называется выполнение аналитических запросов, для которых допустимо время отклика от долей секунды до нескольких минут. Тем самым Presto является первым открытым решением для задач быстрой аналитики, которые ранее были доступны только через дорогие проприетарные системы или через использование свободных систем, требующих излишнего аппаратного обеспечения.
Сформированный в Presto запрос может охватывать несколько источников данных, агрегируя полученные сведения в единый итоговый результат. В качестве основной области применения Presto называется выполнение аналитических запросов, для которых допустимо время отклика от долей секунды до нескольких минут. Тем самым Presto является первым открытым решением для задач быстрой аналитики, которые ранее были доступны только через дорогие проприетарные системы или через использование свободных систем, требующих излишнего аппаратного обеспечения.
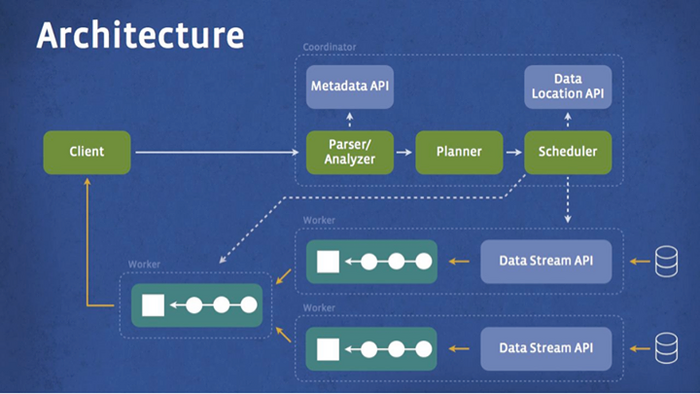 Движком поддерживается большинство элементов, определённых в спецификации ANSI SQL, включая возможность объединения таблиц, использования математических функций, строковых преобразований, регулярных выражений, операций с данными в формате JSON, оконных функций для отсеивания набора строк из результирующего запроса. Для формирования запросов можно использовать специальную консольную облочку, модули интеграции с интегрированными средами разработки и биндинги для различных языков программирования.
Движком поддерживается большинство элементов, определённых в спецификации ANSI SQL, включая возможность объединения таблиц, использования математических функций, строковых преобразований, регулярных выражений, операций с данными в формате JSON, оконных функций для отсеивания набора строк из результирующего запроса. Для формирования запросов можно использовать специальную консольную облочку, модули интеграции с интегрированными средами разработки и биндинги для различных языков программирования.
Код Presto написан на языке Java и распространяется под лицензией Apache 2. Для увеличения производительности части плана выполнения запроса динамически компилируются в Java-байткод, что позволяет JVM использовать дополнительные оптимизации и сгенерировать машинный код. Код Presto создан с учётом обхода типичных проблем Java-кода c распределением памяти и сборкой мусора.
© OpenNet
