Энтузиасты воссоздали метод мгновенной генерации PDF-файлов с одинаковым хэшем SHA-1
Не дожидаясь компании Google, которая на 90 дней отложила публикацию практических наработок в области подбора коллизий SHA-1, энтузиасты представили сразу несколько своих вариантов осуществления атаки, основанных на изначально доступном теоретическом описании. В частности, запущен альтернативный сервис SHA1 collider, позволяющий загрузить два разных изображения и сразу получить на выходе два PDF-файла, имеющих одинаковый хэш SHA-1, но выводящих разные изображения. Также подготовлен Python-скрипт для приведения двух многостраничных PDF-документов к виду с одинаковыми хэшами SHA-1.
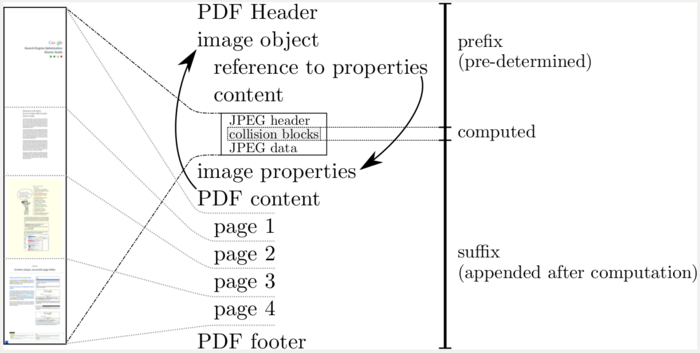
В случае предложенной атаки на PDF, для создания двух PDF-файлов с одинаковыми хэшами SHA-1 больших вычислительных ресурсов не требуется. Суть метода в том, что при помощи своих ресурсов Google рассчитал коллизию для типовых начальных блоков PDF, включающих заголовок PDF, дескриптор потока JPEG и заголовки JPEG. Cодержимое документов для которых нужно создать PDF с одинаковыми хэшами преобразуется в многослойный JPEG, в котором присутствует изображение как первого, так и второго документа.
Наполнение для вызова коллизии включается в состав JPEG. Далее этот общий JPEG прикрепляется к готовым начальным блокам и завершается типовым фиксированным завершающим блоком, содержащим команды отображения PDF. Отображение разных данных в разных PDF обеспечивается через переключение активного слоя в JPEG-изображении. При открытии первого PDF показывается первый слой, а при открытии другого — второй. Так как к уже имеющим коллизию данным прикрепляется одинаковое дополнение коллизия не нарушается, меняется только итоговый общий хэш.
© OpenNet
