Выпуск СУБД ScyllaDB 3.0, совместимой с Apache Cassandra
Представлен релиз СУБД ScyllaDB, позиционируемой как полностью совместимый аналог СУБД Apache Cassandra, переписанный с Java на C++ и демонстрирующий существенное увеличение производительности. Код проекта распространяется под лицензией AGPLv3.
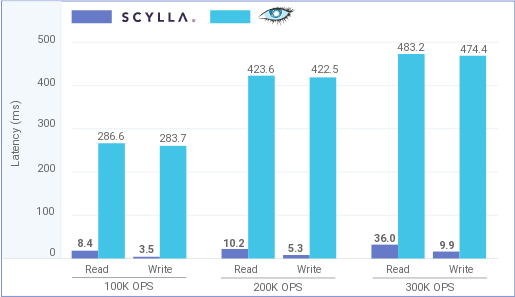
По сравнению с оригинальной СУБД Apache Cassandra проект ScyllaDB обеспечивает увеличение скорости обработки запросов на каждом узле в 10 раз, в 99% случаев успевая обработать запрос менее чем за миллисекунду. Обработка большего числа запросов на одном узле позволяет существенно снизить затраты на кластер (при использовании AWS EC2 в 2.5 раз), в котором для достижения заданных характеристик потребуется на порядок меньше узлов, чем при создании кластера на основе классической СУБД Cassandra. Например, 4-узловой кластер на базе Scylla вполне справляется с нагрузкой для которой потребовалось бы развернуть 40-узловой кластер на базе Cassandra.
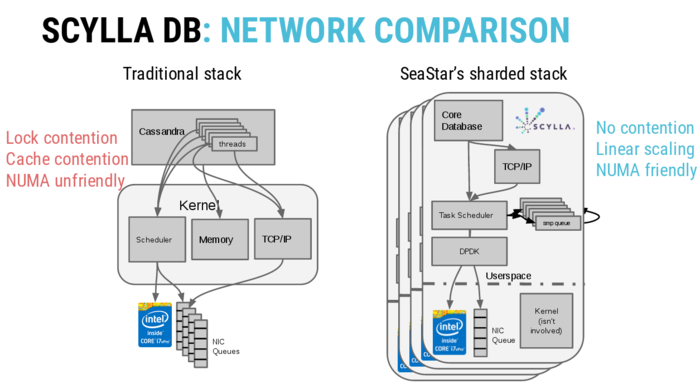
Одним из факторов, позволившим добиться высоких показателей производительности, является использование развиваемого теми же авторами C++ фреймворка Seastar, нацеленного на создание сложных серверных приложений, обрабатывающих запросы в асинхронном режиме. Seastar учитывает особенности современного оборудования, таких как распараллеливание на многоядерных системах, учёт попадания данных в процессорный кэш, оптимизация для накопителей SSD, прямой доступ к очереди пакетов на сетевой карте и полная утилизация пропускной способности 10/40-гигабитных сетевых карт.
Система построена на основе архитектуры shared-nothing, подразумевающей, что к каждому ядру CPU привязывается отдельный обособленный обработчик, которому выделена отдельная память (отсутствуют задержки из-за организации блокировок) и привязана отдельная очередь пакетов к сетевой карте. Каждый процесс-обработчик ScyllaDB включает в себя собственный оптимизирванный TCP/IP-стек, работающий в пространстве пользователя, прикреплённый к отдельному ядру CPU и напрямую взаимодействующий с сетевой картой.
Другие особенности ScyllaDB:
- Поддержка работы в качестве прозрачной замены Apache Cassandra;
- Возможность применения существующих клиентских драйверо от Apache Cassandra для подключения к ScyllaDB;
- Поддержка модели хранения данных на базе семейства столбцов (ColumnFamily, хэши с несколькими уровнями вложенности);
- Возможность использования SQL-подобного язык структурированных запросов CQL (Cassandra Query Language);
- Исключение задержек при проведении упаковки и восстановления целостности БД;
- Отсутствие сборщика мусора;
- Возможность переконфигурации кластера (удаление/добавление узлов) без остановки работы;
- Линейная масштабируемость, при которой производительность находится в прямой зависимости от числа процессорных ядер;
- Наличие средств для пакетной загрузки и выгрузки больших объёмов данных из хранилищ Hadoop и Spark.
Выпуск СУБД ScyllaDB 3.0 по функциональности соответствует ветке Apache Cassandra 3 и примечателен следующими улучшениями:
- Поддержка материализованных представлений, позволяющих сформировать виртуальную таблицу на основе произвольного CQL-запроса, содержимое которой не генерируется на лету как в обычных представлениях, а кэшируется между запросами в форме индекса;
- Добавлена поддержка глобальных для всего кластера вторичных индексов (GSI, Global Secondary Indexes), реализованных через материализованные представления и позволяющих более эффективно индексировать запросы по ключам с агрегированием данных на одном узле;
- Предложен новый формат хранения данных на диске, совместимый с Apache Cassandra 3.0 и требующий для хранения до 66% меньше места в хранилище по сравнению со старым форматом при активном использовании операций удаления записей. Применение нового формата отключено по умолчанию и может быть активировано через настройку «enable_sstables_mc_format»;
- Добавлен новый механизм хранения информации о репликах для сбойных узлов («hinted handoff»), вместо одного файла system.hints хинты теперь записываются в отдельные файлы, в разрезе один файл на один узел и реплицированный поток;
- Существенно улучшена работа операций полного (мульти-секционнного) сканирования БД, при которых данные перебираются без выборки по конкретному ключу;
- Добавлена поддержка фильтрации сложных запросов с возвращением только подмножества результатов. Фильтрация производится на стороне сервера и позволяет существенно снизить размер передаваемых по сети данных между кластером и приложением;
- Осуществлён переход на штатные утилиты Cassandra, включая nodetool, cassandra-stress и node_exporter 0.17;
- Увеличена производительность потоковой отправки данных при добавлении нового узла или восстановлении после сбоя.
© OpenNet
