Выпуск распределённой СУБД TiDB 3.0
Доступен релиз распределённой СУБД TiDB 3.0, развиваемой под впечатлением от технологий Google Spanner и F1. TiDB относится к категории гибридных систем HTAP (Hybrid Transactional/Analytical Processing), способных как обеспечивать выполнение транзакций в реальном времени (OLTP), так и выполнять обработку аналитических запросов. Проект написан на языке Go и распространяется под лицензией Apache 2.0.
Особенности TiDB:
- Поддержка SQL и предоставление клиентского интерфейса, совместимого с протоколом MySQL, что упрощает адаптацию для TiDB существующих приложений, написанных для MySQL, а также позволяет задействовать распространённые клиентские библиотеки. Кроме протокола MySQL для обращения к СУБД можно использовать API на базе JSON и коннектор для Spark.
- Из возможностей SQL поддерживаются индексы, агрегатные функции, выражения GROUP BY, ORDER BY, DISTINCT, слияния (LEFT JOIN / RIGHT JOIN / CROSS JOIN), представления, оконные функции и подзапросы. Предоставляемых возможностей достаточно для организации работы с TiDB таких web-приложений, как PhpMyAdmin, Gogs и Wordpress;
- Возможность горизонтального масштабирования и обеспечения отказоустойчивости: размер хранилища и вычислительную мощность можно наращивать простым подключением новых узлов. Данные распределяются по узлам с избыточностью, позволяющей продолжить работу в случае сбоя отдельных узлов. Сбои обрабатываются автоматически.
- Система гарантирует непротиворечивость и для клиентского ПО выглядит как одна большая СУБД, несмотря на то, что фактически для выполнения транзакции привлекаются данные со множества узлов.
- Для физического хранения данных на узлах могут применяться разные бэкенды, например, локальные движки хранения GoLevelDB и BoltDB или собственный движок распределённого хранилища TiKV.
- Возможность асинхронного изменения схемы хранения, позволяющая на лету добавлять столбцы и индексы без остановки обработки текущих операций.
Основные новшества:
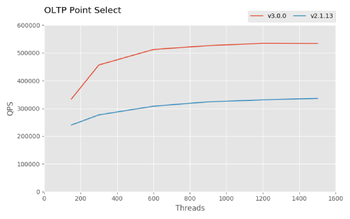
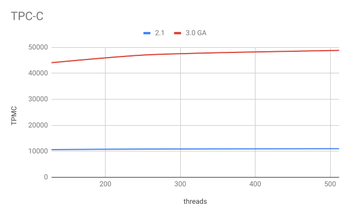
- Проведена работа по увеличению производительности. В тесте Sysbench выпуск 3.0 опережает ветку 2.1 в 1.5 раза при выполнении операций select и update, а в тесте TPC-C в 4.5 раза. Оптимизации затронули различные виды запросов, включая подзапросы «IN», «DO» и «NOT EXISTS», операции слияния таблиц (JOIN), использование индексов и многое другое;
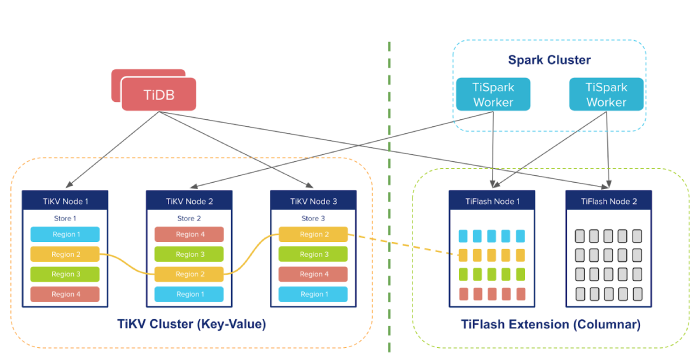
- Добавлен новый движок хранения TiFlash, позволяющий добиться более высокой производительности при решении аналитических задач (OLAP), благодаря хранению в привязке к столбцам. TiFlash дополняет собой ранее предлагаемое хранилище TiKV, хранящее данные в разрезе строк в формате ключ/значение и более опримальное для задач обработки транзакций (OLTP). TiFlash работает бок о бок с TiKV и данные продолжают как и раньше реплицироваться в TiKV с использоанием протокола Raft для определении консенсуса, но для каждой группы реплик Raft создаётся дополнительная реплика, которая используется в TiFlash. Подобный поход позволяет добиться лучшего разделения ресурсов между задачами OLTP и OLAP, а также делает данные транзакций мгновенно доступными для аналитических запросов;
- Реализован распределённый сборщик мусора, позволяющий существенно повысить скорость сборки мусора в крупных кластерах и повысить стабильность работы;
- Добавлена экспериментальная реализация системы разграничения доступа на основе ролей (RBAC). Также обеспечена возможность задания прав доступа для операций ANALYZE, USE, SET GLOBAL и SHOW PROCESSLIST;
- Добавлена возможность использования выражений SQL для выблрки из лога медленных запросов;
- Реализован механизм быстрого восстановления удалённых таблиц, позволяющий восстановить случайно удалённые данные;
- Унифицирован формат записываемых логов;
- Добавлена поддержка пессимистического режима блокировки, который делает обработку транзакций более близкой к MySQL;
- Добавлена поддержка оконных функций (window-функции или аналитические функции), совместимых с MySQL 8.0. Оконные функции позволяют для каждой строки запроса выполнить вычисления, используя другие строки. В отличие от агрегатных функций, которые свёртывают сгруппированный набор строк в одну строку, оконные функции производят агрегирование на основе содержимого «окна», включающего одну или более строк из результирующего набора. Среди реализованных оконных функций: NTILE, LEAD, LAG, PERCENT_RANK, NTH_VALUE, CUME_DIST, FIRST_VALUE, LAST_VALUE, RANK, DENSE_RANK и ROW_NUMBER;
- Добавлена экспериментальная поддержка представлений (VIEW);
- Улучшена система секционирования (партицирования), добавлена возможность распределения данным по секциям на основании диапазона значений или хэшей;
- Добавлен фреймворк для разработки плагинов, например, уже подготовлены плагины для использования белого списка IP или ведения лога аудита;
- Обеспечена экспериментальная поддержка функции «EXPLAIN ANALYZE» для построения плана выполнения SQL-запроса (SQL Plan Management);
- Добавлена команда next_row_id для получения идентификатора следующей строки;
- Добавлены новые встроенные функции JSON_QUOTE, JSON_ARRAY_APPEND, JSON_MERGE_PRESERVE, BENCHMARK, COALESCE и NAME_CONST.
© OpenNet
