Релиз открытой СУБД VoltDB 3.0, развиваемой одним из основателей Ingres и PostgreSQL
Представлен релиз инновационной открытой СУБД VoltDB 3.0, развиваемой под руководством Майкла Стоунбрейкера (Mike Stonebraker), одного из основателей проектов Ingres и PostgreSQL. СУБД VoltDB поддерживает горизонтальное масштабирование и ориентирована на обработку транзакций в реальном времени (OLTP). На недорогом кластере, собранном своими силами из обычных серверов, СУБД способна обрабатывать миллионы транзакций в секунду. СУБД распространяется в двух вариантах: коммерческом, с обеспечением полноценной поддержки, и свободном "Community Edition". Код опубликован под лицензией AGPLv3.VoltDB позволяет достичь уровня производительности NoSQL-систем, сохранив при этом поддержку выполнения запросов на языке SQL и гарантирированную транзакционную целостность данных (ACID, атомарность и изолированность транзакций). При оценке производительности в односерверной конфигурации СУБД VoltDB опередила традиционные OLTP СУБД в 45 раз, обработав 53 тыс. транзакций в секунду, в то время как другие СУБД на том же оборудовании могли выполнить только 1155 транзакций. На 12-узловом кластере СУБД VoltDB обеспечила выполнение 560 тыс. транзакций в сек. При этом, VoltDB уже достаточно давно используется в промышленной эксплуатации и позиционируется как полностью стабильный продукт.
Разгадка высокой производительности VoltDB кроется в непохожей на традиционные схемы внутренней архитектуре, комбинирующей хранение данных в памяти с концепцией распределенной организации и разбиением содержимого БД по разделам (партицирование). Производительность VoltDB увеличивается почти линейно при добавлении дополнительных серверов в кластер. Каждый однопоточный раздел работает в автономном режиме, что исключает необходимость в блокировках и фиксации операций. Данные автоматически реплицируются внутри кластера, что позволяет добиться высокой доступности и исключает необходимость ведения журнала. Все данные каждого узла полностью прокэшированы в ОЗУ, что обеспечивает максимальную пропускную способность и исключает необходимость буферизации.
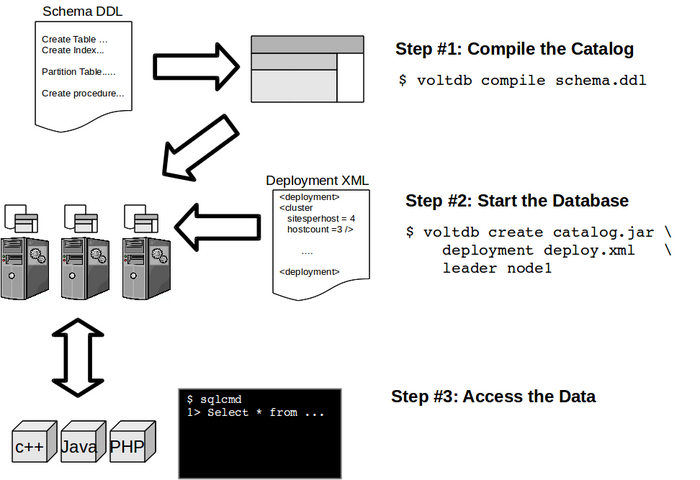
На одном сервере запускается несколько узлов VoltDB, каждый из которых привязывается к отдельному ядру CPU. Для сохранения данных на диск используется концепция снапшотов, отражающих срез данных, актуальных на момент создания снапшота. Работа с данными осуществляется через хранимые процедуры на языке Java, копии которых прикрепляются к каждому из разделов (ODBC/JDBC и прямое выполнение SQL-операторов для всей базы не поддерживается). При выполнении запроса, затрагивающего несколько разделов, в каждом из нужных разделов вызывается хранимая процедура, а затем результаты агрегируются.
Среди новшеств, добавленных в VoltDB 3.0:
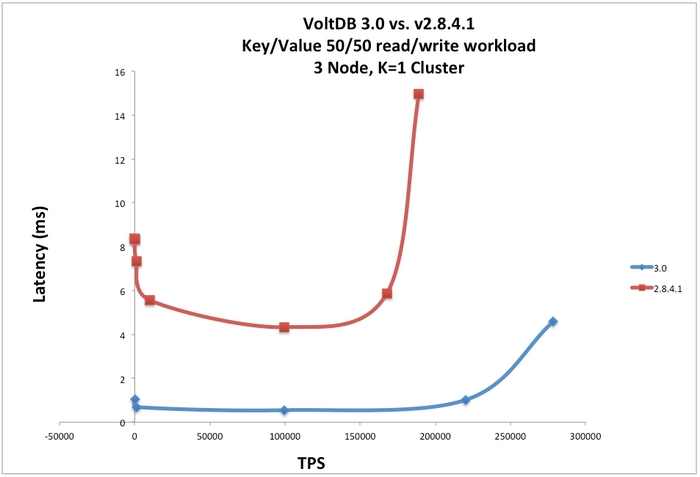
- Переработана архитектура координации выполнения транзакций, что позволило минимизировать обмен данными между узлами в процессе выполнения запроса. В результате была увеличена пропускная способность и уменьшена задержка выполнения запросов. По сравнению с VoltDB 2.x версия 3.0 позволяет выполнить на том же оборудовании гораздо больше транзакций и существенно снизить задержки для работающих в синхронном режиме клиентов, в которых выполнение продолжается только после завершения каждого запроса (в асинхронном режиме управление передаётся дальше не дожидаясь выполнения запроса, готовность которого оценивается через обработку событий);
- Для упрощения разработки высокопроизводительных приложений добавлена поддержка шаблона project.xml для размещения данных в кластере и команды compile для автоматической компиляции схемы. Расширены возможности изменения схемы БД на лету, добавлены команды для создания и изменения индексов, применимые для работающего кластера;
- Расширен поддерживаемый синтаксис SQL, добавлена возможность использования выражения UNION и операторов LIKE/NOT LIKE, подготовлен полный набор строковых и числовых функций. Реализована поддержка определения индексов с использованием функций, работающих на уровне столбцов;
- Реализован интерфейс для доступа к данным с использованием формата JSON. Указанная возможность позволяет гибко управлять и менять схему хранения, которая теперь может задаваться в произвольном виде. Для манипуляции со структурированными JSON-данными, прикреплёнными к столбцу, представлена новая функция field();
- Новые средства для импорта и экспорта данных. Добавлены модули для импорта данных из лога Apache и из CSV-файлов. Переработана поддержка экспорта, отмечается, что новая реализация экспортирует данные в 20 раз быстрее прежней. Добавлен JDBC-коннектор для экспорта данных в СУБД PostgreSQL, Oracle и MySQL;
- Новая утилита voltadmin с реализация интерфейса командной строки для централизованного управления всем кластером VoltDB;
- Добавлен переработанный высокопроизводительный драйвер для PHP и новые драйверы для Node.js и Google Go.



© OpenNet
