Увидела свет платформа для распределённой обработки данных Apache Hadoop 2
Организация Apache Software Foundation представила релиз Apache Hadoop 2.0.0, свободной платформы для организации распределённой обработки больших объёмов данных с использованием парадигмы map/reduce, при которой задача делится на множество более мелких обособленных фрагментов, каждый из которых может быть запущен на отдельном узле кластера. Хранилище на базе Hadoop может охватывать тысячи узлов и содержать эксабайты данных (общий объём цифровой информации на Земле оценивается в 161 эксабайт). В состав Hadoop входит реализация распределенной файловой системы Hadoop Distributed Filesystem (HDFS), автоматически обеспечивающей резервирование данных и оптимизированной для работы MapReduce-приложений. Для упрощения доступа к данным в Hadoop хранилище разработана БД HBase и SQL-подобный язык Pig, который является своего рода SQL для MapReduce, запросы которого могут быть распараллелены и обработаны несколькими Hadoop-платформами. Проект оценивается как полностью стабильный и готовый для промышленной эксплуатции. Hadoop активно используется в крупных промышленных проектах, предоставляя возможности, аналогичные платформе Google Bigtable/GFS/MapReduce, при этом компания Google официально делегировала Hadoop и другим проектам Apache право использования технологий, на которые распространяются патенты, связанные с методом MapReduce.
Hadoop-кластеры, обрабатывающие десятки петабайт информации, развёрнуты в таких компаниях, как Yahoo, Facebook, Amazon, AOL, Apple, eBay, HP, LinkedIn, Netflix, Rackspace и Twitter. Рекордсменом является Hadoop-кластер Yahoo, состоящий из 35 тысяч узлов. Hadoop лежит в основе платформы Oracle Big Data и некоторых продуктов компаний Microsoft, IBM, Teradata и SAP. Hadoop является одним из ключевых звеньев суперкомпьютера IBM Watson, который выиграл сражение с лучшими игроками телевизионной игры-викторины «Jeopardy!».
Особенности выпуска Apache Hadoop 2:
Реализация YARN (MapReduce 2.0), позволяющего одновременно запускать различные приложения для обработки данных (например, Apache Hadoop MapReduce и Apache Storm) и сервисы (например, Apache HBase). Основная идея YARN заключается в выделении в отдельные демоны частей, связанных с отслеживанием выполнения заданий (JobTracker), управленем ресурсами и планированием работ. Ключевые компоненты YARN: ResourceManager (RM, управляет распределением всех ресурсов системы для всех приложений), NodeManager (координирует работу каждого узла) и ApplicationMaster (AM, запускается для каждого приложения и обеспечивает выполнение заданий с использованием полученных от ResourceManager ресурсов). 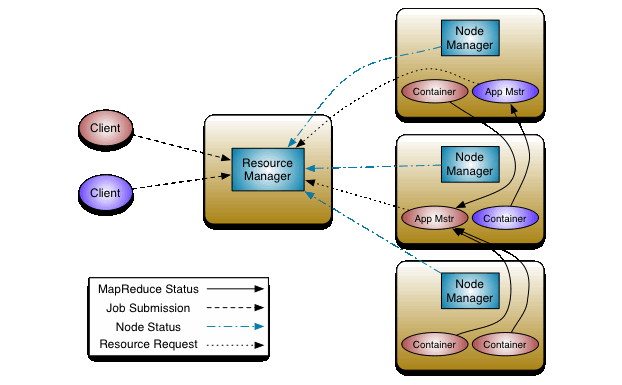 Обеспечение высокой доступности для HDFS; Средства для объединения разных экземпляров HDFS (Federation HDFS); Возможность создания снапшотов данных в HDFS; Поддержка доступа к HDFS через NFSv3; Обеспечение бинарной совместимости с существующими приложениями MapReduce, созданными для Apache Hadoop 1.x; Поддержка платформы Microsoft Windows.
Обеспечение высокой доступности для HDFS; Средства для объединения разных экземпляров HDFS (Federation HDFS); Возможность создания снапшотов данных в HDFS; Поддержка доступа к HDFS через NFSv3; Обеспечение бинарной совместимости с существующими приложениями MapReduce, созданными для Apache Hadoop 1.x; Поддержка платформы Microsoft Windows.
© OpenNet
