Релиз распределенного реплицируемого блочного устройства DRBD 9.2.0
Опубликован релиз распределенного реплицируемого блочного устройства DRBD 9.2.0, позволяющего реализовать подобие массива RAID-1, сформированного из объединённых по сети нескольких дисков разных машин (зеркалирование по сети). Система оформлена в виде модуля для ядра Linux и распространяется под лицензией GPLv2. Ветка drbd 9.2.0 может использоваться для прозрачной замены drbd 9.x.x и полностью совместима на уровне протокола, файлов конфигурации и утилит.
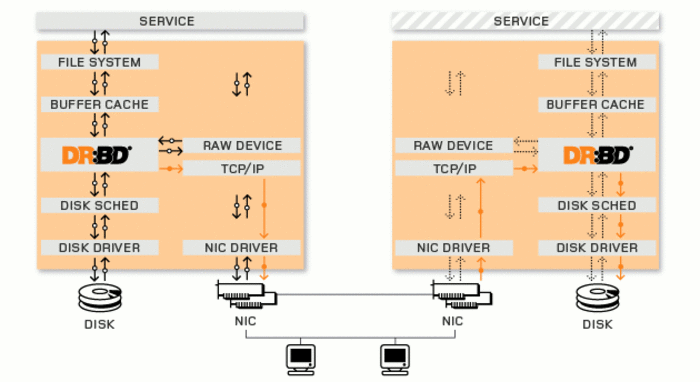
DRBD даёт возможность объединить накопители узлов кластера в единое отказоустойчивое хранилище. Для приложений и системы такое хранилище выглядит как одинаковое для всех систем блочное устройство. При использовании DRBD все операции с локальным диском отправляются на другие узлы и синхронизируются с дисками других машин. В случае выхода из строя одного узла, хранилище автоматически продолжит работу за счёт оставшихся узлов. При возобновлении доступности сбойного узла, его состояние будет автоматически доведено до актуального вида.
В состав кластера, формирующего хранилище, может входить несколько десятков узлов, размещённых как в локальной сети, так и территориально разнесённых в разные центры обработки данных. Синхронизация в подобных разветвлённых хранилищах выполняется с использованием технологий mesh-сети (данные растекаются по цепочке от узла к узлу). Репликация узлов может производиться как в синхронном режиме, так и в асинхронном. Например, локально размещённые узлы могут применять синхронную репликацию, а для выноса на удалённое размещённые площадки может применяться асинхронная репликация с дополнительным сжатием и шифрованием трафика.
В новом выпуске:
Снижены задержки для зеркалируемых запросов на запись. Более плотная интеграция с сетевым стеком позволила снизить число переключений контекста планировщика.
Снижена конкуренция между вводом/выводом приложений и вводом/выводом ресинхронизации за счёт оптимизации блокировок при ресинхронизации экстентов.
- Значительно повышена производительность ресинхронизации на бэкендах, в которых применяется динамическое выделение места в хранилище («thin provisioning»). Производительность удалось поднять благодаря объединению операций trim/discard, которые выполняются значительно дольше обычных операций записи.
Добавлена поддержка сетевых пространств имён (network namespaces), которая позволила реализовать возможность интеграции с Kubernetes для передачи сетевого трафика репликаций через привязанную к контейнерам отдельную сеть, вместо сети хост-окружения.
- Добавлен модуль transport_rdma для использования в качестве транспорта Infiniband/RoCE вместо TCP/IP поверх Ethernet. Использование нового транспорта позволяет снизить задержки, уменьшить нагрузку на CPU и обеспечить получение данных без лишних операций копирования (zero-copy).
Источник: http://www.opennet.ru/opennews/art.shtml? num=57896
© OpenNet
