ИИ DeepMind Agent57 проходит игры Atari лучше человека
Заставить нейронную сеть проходить несложные видеоигры — идеальный способ проверить эффективность её обучения благодаря простой возможности оценивать результаты прохождения. Разработанный в 2012 году компанией DeepMind (часть холдинга Alphabet) эталонный тест из 57 каноничных игр Atari 2600 стал лакмусовой бумажкой для проверки возможностей самообучающихся систем. И вот Agent57, передовой RL-агент (Reinforcement Learning — обучение с подкреплением) DeepMind, на днях показал огромный скачок по сравнению с предыдущими системами и стал первой итерацией ИИ, превосходящей базовые показатели игрока-человека.
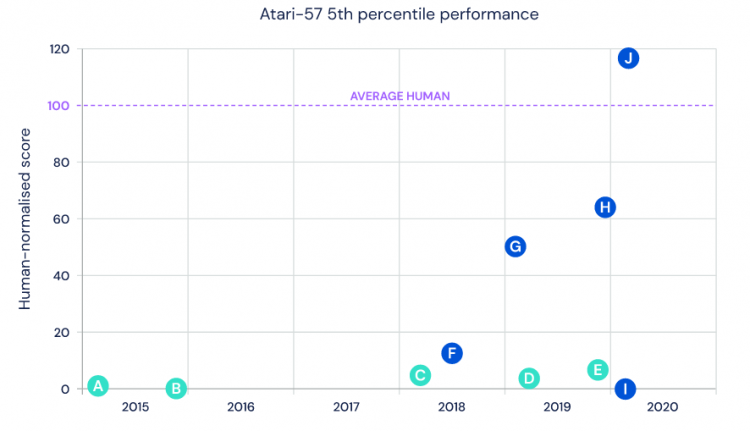
J — показатель RL-агента Agent57
ИИ Agent57 учитывает опыт предыдущих систем компании и объединяет алгоритмы эффективного исследования среды с мета-контролем. В частности, Agent57 доказал свои сверхчеловеческие навыки в Pitfall, Montezuma’s Revenge, Solaris и Skiing — играх, которые были серьезным испытанием для предыдущих нейросетей. Согласно результатам исследований, для достижения лучших результатов Pitfall и Montezuma’s Revenge заставляют ИИ больше экспериментировать. Solaris и Skiing сложны для нейросетей, потому что признаков успеха не так много — ИИ в течение длительного времени не знает, совершает ли он правильные действия. DeepMind основывалась на своих старых агентах ИИ, чтобы Agent57 мог принимать более правильные решения в отношении исследования среды и оценки результатов прохождение игр, а также оптимизировать компромисс между краткосрочным и долгосрочным поведением в таких играх как Skiing.
Результаты впечатляют, но ИИ ещё предстоит пройти долгий путь. Эти системы могут справиться только с одной игрой за раз, что, по словам разработчиков, противоречит возможностям человека: «Истинная гибкость, которая так легко даётся человеческому мозгу, всё ещё находится за пределами досягаемости ИИ».
Источник:
© 3DNews
