Доступна система распределённых вычислений Apache Storm 2.0
Увидел свет значительный выпуск системы распределённой обработки событий Apache Storm 2.0, примечательный переходом на новую архитектуру, реализованную на языке Java, вместо ранее применяемого языка Clojure.
Проект позволяет организовать гарантированную обработку различных событий в режиме реального времени. Например, Storm можно применять для анализа потоков данных в режиме реального времени, выполнения задач для машинного обучения, организации непрерывных вычислений, реализации RPC, ETL и т.п. Система поддерживает кластеризацию, создание отказоустойчивых конфигураций, режим гарантированной обработки данных и обладает высокой производительностью, достаточной для обработки более миллиона запросов в секунду на одном узле кластера.
Поддерживается интеграция с различными системами обработки очередей и технологиями баз данных. Архитектура Storm подразумевает приём и обработку неструктурированных постоянно обновляемых потоков данных с использование произвольных сложных обработчиков с возможностью секционирования между различными стадиями вычислений. Проект был передан сообществу Apache после поглощения Twitter компании BackType, изначально разработавшей фреймворк. На практике Storm применялся в BackType для анализа отражения событий в микроблогах, путём сопоставления на лету новых твитов и используемых в них ссылок (например, производилась оценка, как внешние ссылки или публикуемые в Twitter анонсы, ретранслируются другими участниками).
Функциональность Storm сравнивается с платформой Hadoop, при этом ключевым отличием является то, что данные не размещены в хранилище, а поступают извне и обрабатываются в режиме реального времени. В Storm нет встроенной прослойки для организации хранилища и аналитический запрос начинает применяться к поступающим данным до тех пор, пока не будет отменен (если в Hadoop используются занимающие конечное время MapReduce-работы, то в Storm применяется идея непрерывно выполняемых «топологий»). Выполнение обработчиков может быть распределено на несколько серверов — Storm автоматически распараллеливает работу с потоками на разные узлы кластера.
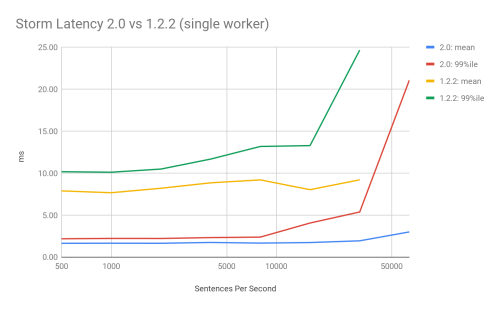
Изначально система была написана на языке Clojure и выполняется внутри виртуальной машины JVM. В фонде Apache была запущена инициативы по переводу Storm на новое ядро, написанное на Java, результаты которой предложены в выпуске Apache Storm 2.0. Все базовые компоненты платформы переписаны на Java. Поддержка написания обработчиков на Clojure сохранена, но теперь предлагается в виде биндингов. Для работы Storm 2.0.0 требуется наличие Java 8. Полностью переработана модель многопоточной обработки, что позволило добиться заметного прироста производительности (для некоторых топологий задержки сократились на 50–80%).
В новой версии также предложен новый типизированный API Streams, позволяющий задавать обработчики, используя операции в стиле функционального программирования. Новый API реализован поверх штатного базового API и поддерживает автоматическое объединение операций для оптимизации их обработки. В API Windowing для оконных операций добавлена поддержка сохранения и восстановления состояния в бэкенде.
В планировщик запуска обработчиков добавлена поддержка учёта дополнительных ресурсов при принятии решений, не ограничивающихся CPU и памятью, таких как параметры сети и GPU. Внесено большое число улучшений, связанных с обеспечением интеграции с платформой Kafka. Расширена система контроля доступа, в которой появилась возможность создания групп администраторов и делегирования токенов. Добавлены улучшения, связанные с поддержкой SQL и метрик. В интерфейсе администратора появились новые команды для отладки состояния кластера.
Области применения Storm:
- Обработка потоков новых данных или обновлений БД в реальном времени;
- Непрерывные вычисления: Storm может выполнять непрерывные запросы и обрабатывать непрерывные потоки, передавая результаты обработки клиенту в режиме реального времени.
- Распределенный удаленный вызов процедур (RPC): Storm может быть использован для обеспечения параллелизма выполнения ресурсоёмких запросов. Задание («топология») в Storm представляет собой распределенную по узлам функцию, которая ожидает поступления сообщений, которые нужно обработать. После приёма сообщения, функция обрабатывает его в локальном контексте и возвращает результат. Примером использования распределенного RPC может быть параллельная обработка поисковых запросов или выполнение операций над большим набором множеств.
Особенности Storm:
- Простая модель программирования, значительно упрощающая обработку данных в режиме реального времени;
- Поддержка любых языков программирования. Имеются модули для языков Java, Ruby и Python, адаптация для других языков не вызывает сложности благодаря очень простому коммуникационному протоколу, для реализации поддержки которого требуется около 100 строк кода;
- Отказоустойчивость: для запуска задания по обработке данных требуется сформировать jar-файл с кодом. Storm самостоятельно распространит данный jar-файл по узлам кластера, подключит связанные с ним обработчики и организует мониторинг. При завершении задания код будет автоматически отключен на всех узлах;
- Горизонтальная масштабируемость. Все вычисления производятся в параллельном режиме, при возрастании нагрузки к кластеру достаточно просто подключить новые узлы;
- Надежность. Storm гарантирует, что каждое поступающее сообщение будет полностью обработано как минимум один раз. Один раз сообщение будет обработано только в случае отсутствия ошибок при прохождении всех обработчиков, если возникли проблемы, то неудачные попытки обработки будут повторены.
- Скорость. Код Storm написан с оглядкой на высокую производительность и использует для быстрого асинхронного обмена сообщениями систему ZeroMQ.
© OpenNet
