Baidu выпустила ERNIE 2.0 — новую модель для понимания человеческого языка при помощи ИИ
В марте этого года китайская компания Baidu представила первую версию ERNIE (Enhanced Representation through kNowledge IntEgration), нового фреймворка и модели для обработки естественного языка (Natural Language Processing — NLP), который поднял настоящую волну в сообществе разработчиков NLP-систем, опередив Google BERT (Bidirectional Encoder Representations from Transformers) в различных задачах по анализу текстов на китайском языке. Теперь Baidu сообщила о выпуске новой версии модели — ERNIE 2.0. В своей исследовательской работе учёные из Baidu утверждают, что ERNIE 2.0 превосходит модели BERT и более современную XLNet в 16 задачах NLP на китайском и английском языках.

Baidu представила новую версию предварительно обученной нейронной модели ERNIE 2.0
ERNIE представляет собой предварительно обученную нейронную сеть, созданную при помощи PaddlePaddle — открытой платформы для глубокого обучения, созданной в Baidu. Процесс предварительного обучения NLP-моделей, таких как BERT, XLNet и ERNIE, в основном базируется на нескольких простых задачах, моделирующих использование слов или предложений с учётом их связи и семантики. Например, BERT использует модель двунаправленного языка (bidirectional language model) и задачу по прогнозированию следующего предложения, чтобы получить информацию о совпадениях, а XLNet применяет модель языковых перестановок (permutation language model).
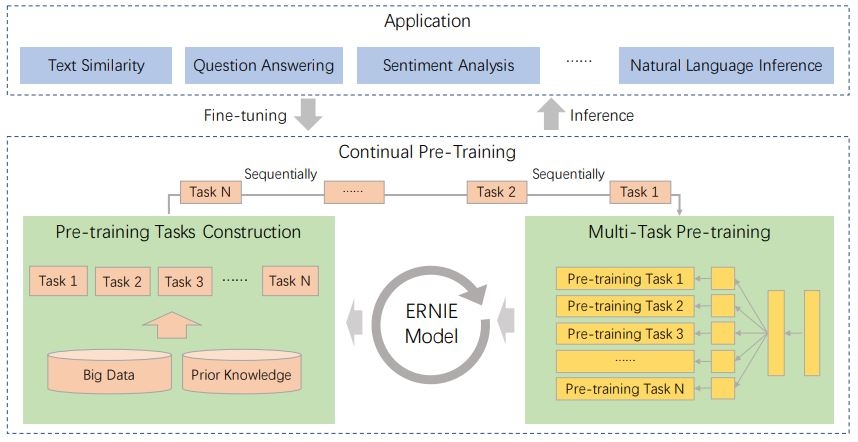
Структура ERNIE 2.0, в которой различные задачи для обучения могут ставиться одновременно и добавляться по мере необходимости, а сама модель может быть настроена для решения любого типа задач в области понимания естественного языка.
Но помимо порядка слов и их связи, в лингвистических системах есть гораздо более сложная лексическая, синтаксическая и семантическая информация. Например, различные название и имена собственные — имена людей, географические названия и названия организаций — содержат концептуально важную информацию. В то же время информация о порядке и последовательности предложений даёт возможность NLP-моделям изучать языковые конструкции с учетом их структуры, а семантическое сходство и логические связи между предложениями позволяют исследовать семантические языковые правила. Таким образом языковым моделям для максимальной точности и производительности необходимо учитывать как минимум три указанных подхода. И исследователи Baidu задались вопросом: »Возможно ли использовать их параллельно и непрерывно? ».

Входные данные для ERNEIE включают в себя токены (единицы анализа текста), сами анализируемые предложения, информацию о позициях токенов в них и необходимые для выполнения задачи.
Основываясь на этой идее, они предложили структуру для непрерывного обучения модели пониманию языка, в которой задачи предварительного обучения могут создаваться в любой момент и выполняться за счёт заложенной многозадачности для обучения и кодирования лексической, синтаксической и семантической информации между ними. И всякий раз, когда добавляется новая задача, эта структура может постепенно обучать распределенные представления, не забывая ранее обученные параметры.
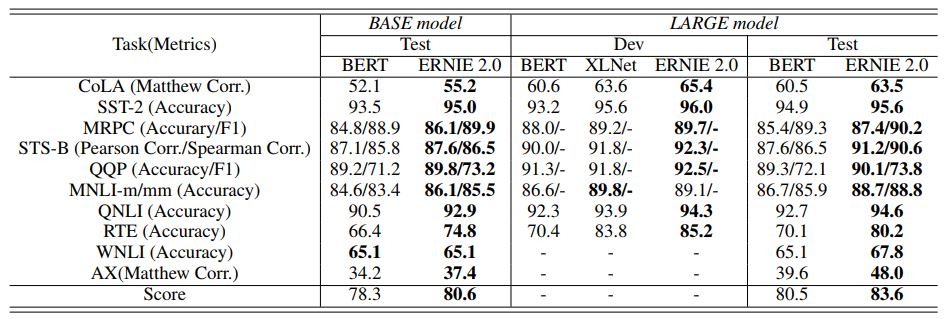
В тестировании на наборе данных GLUE для английского языка ERNIE 2.0 обошла BERT и XLNet в 7 задачах из 9
Команда Baidu сравнила производительность ERNIE 2.0 с другими NLP-моделями для английского языка на наборе данных GLUE и отдельно на 9 популярных наборах для китайского языка. Результаты показывают, что ERNIE 2.0 превосходит BERT и XLNet в 7 задачах на понимание английского языка и превосходит BERT по всем 9 задачам, когда дело касается китайского, таких как машинное чтение с использованием набора данных DuReader, семантический анализ и ответы на вопросы.
Чтобы узнать больше об ERNIE 2.0, вы можете прочитать исследовательскую работу на английском языке, а исходные коды и предварительно обученную модель можно загрузить с официальной страницы на GitHub.
Источники:
© 3DNews
